AI实时绘画系统StreamMultiDiffusion 支持局部涂抹+提示生成图片
近期,一篇名为"StreamMultiDiffusion"的论文提出了一种新颖的实时、交互式的文本到图像生成系统。这种系统能够根据用户提供的手绘区域和相应的语义文本提示来生成图像,为专业图像创作者提供了一个强大的工具,可以用于快速原型设计和创意探索。
项目地址:https://github.com/ironjr/StreamMultiDiffusion
扩散模型在文本到图像合成领域取得了巨大成功,成为了图像生成和编辑的有前途的候选者。然而,将这些模型用于实际应用仍面临两大挑战:一是需要更快的推理速度,二是需要更智能的模型控制。这两个目标需要同时满足,才能在实际应用中发挥作用。为了解决这些挑战,作者提出了StreamMultiDiffusion框架。
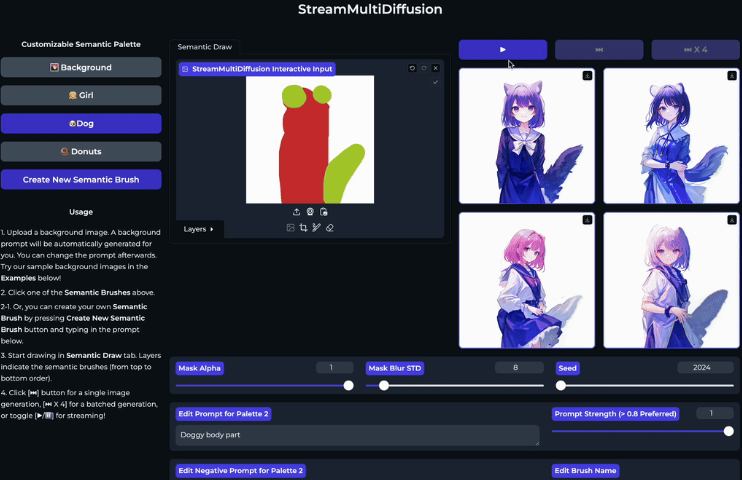
该框架是第一个实时基于区域的文本到图像生成框架。通过稳定快速推理技术并重构模型为新提出的多提示流批处理架构,实现了比现有解决方案更快的全景图生成速度,并在单个RTX2080Ti GPU上实现了基于区域的文本到图像合成的1.57FPS生成速度。
该框架引入了几种关键技术。首先是Latent Pre-Averaging,在推理的每个步骤中,先对中间潜在表示进行平均,以适应快速推理算法。其次是Mask-Centering Bootstrapping,在生成过程的前几步中,将每个遮罩的中心点对齐到图像中心,以确保对象不会被遮罩边缘切断。再次是Quantized Masks,通过量化遮罩来控制提示遮罩的紧密度,从而在不同噪声水平下平滑地融合生成区域。
此外,StreamMultiDiffusion还引入了一个名为Semantic Palette的新概念,这是一种交互式图像生成范式,允许用户通过手绘区域和文本提示实时生成高质量图像。这种方法类似于使用画笔在画布上绘制,但使用的是文本提示和遮罩。例如,用户可以在红色区域生成人物,在耳朵和尾巴区域标记为狗,系统会根据涂抹的区域生成长着狗狗耳朵和尾巴的人物。
论文中的实验结果表明,StreamMultiDiffusion在全景图生成和基于区域的文本到图像合成方面,相比于现有的MultiDiffusion方法,实现了显著的速度提升,同时保持了图像质量。这证明了该系统在实际应用中的巨大潜力和价值。
ai贴纸工具Face-to-sticker 可一键将照片转化为卡通贴纸
Face-to-sticker是一个旨在将人脸转换为贴纸的工具。通过这个工具,用户可以上传一张包含人脸的图像,然后选择一些参数来定制生成的贴纸。这些参数包括对生成图像的指导性描述,以及一些控制生成过程的参数,比如图像的尺寸、生成步数等等。产品入口:https://top.aibase.com/tool/face-to-sticke0000抖音:房产经营类账号需提交资质审核
抖音发布关于房产经营类账号资质审核的公告称,为确保用户安全与利益,防止个别房产账号利用抖音平台从事违规导流、恶意营销等行为,抖音平台将分批要求房产经营类账号提交相应资质,支持具备资质的房产账号在抖音获得更好发展。站长网2023-09-01 17:52:430000Bluehost 推出人工智能驱动的 WordPress 网站建设 AI 套件 WonderSuite
Bluehost是一家专门提供WordPress托管服务的网络托管服务提供商,周三宣布推出一款利用人工智能的WordPress网站构建套件。该套件名为WonderSuite,Bluehost表示它旨在成为一个数字合作伙伴,帮助用户轻松快速地创建网站。Bluehost网站截图站长网2023-07-14 17:24:470000百度推出文心一言会员以及文心一格白银会员服务 模型各项能力全面升级
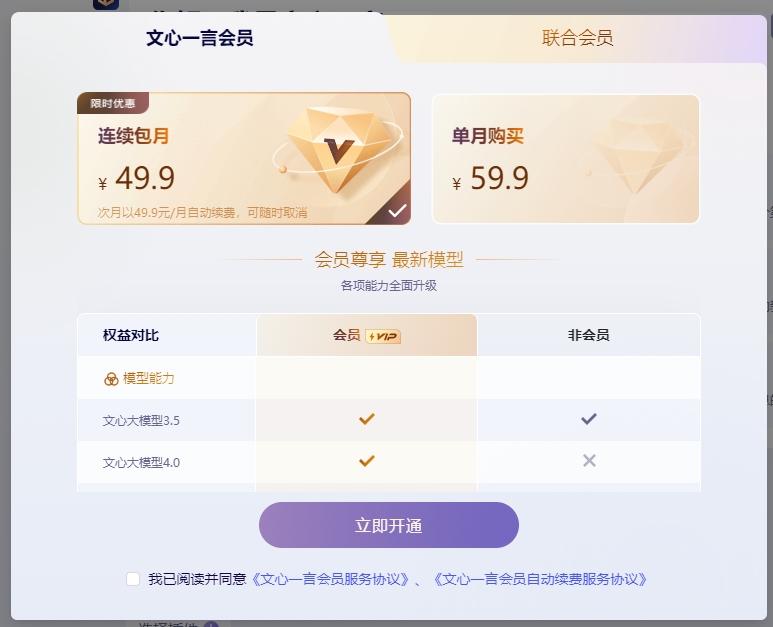
百度文心一言今日宣布推出会员服务,提供文心大模型4.0的提前体验,连续包月售价49.9元,单月购买售价59.9元。购买会员后,用户将享受每3小时内畅享100次问答的特权,并拥有更全面的模型能力和图片生成能力,包括文心大模型4.0和文生图能力的全面升级。同时,会员还享有高阶插件和App端单月赠送的600灵感值的权益。站长网2023-11-01 10:01:480001赵明:荣耀AI服务最智能 MagicOS 7.2表现惊艳
荣耀日前正式发布了新一代数字系列旗舰荣耀100系列,在发布会后的专访中,赵明强调,荣耀的屏幕最护眼、AI服务最智能,折叠屏做得最轻薄、续航能力还最强,这些都没有任何一家能与荣耀相比。荣耀100系列通过MagicOS7.2系统实现了AI内容创作、语义搜索功能,具有更强的AI实力。站长网2023-11-24 16:34:260000