新方法揭示了如何利用一个大语言模型来越狱另一个大语言模型
划重点:
🔍 一项由宾夕法尼亚大学的研究人员开发的新算法可以自动消除大型语言模型(LLM)中的安全漏洞。
🤖 这个名为Prompt Automatic Iterative Refinement(PAIR)的算法可以识别“越狱”提示,防止其生成有害内容。
🌐 PAIR不仅能够与ChatGPT等黑盒模型一起工作,还能够以较少尝试生成越狱提示,且这些提示具有可解释性和可传递性。
一项最新研究揭示了一种新的方法,允许一个大型语言模型(LLM)被用于越狱另一个,以揭示潜在的安全漏洞。
来自宾夕法尼亚大学的研究人员开发了一种名为Prompt Automatic Iterative Refinement(PAIR)的算法,该算法能够自动停止LLMs中的安全漏洞,防止其生成有害内容。

图源备注:图片由AI生成,图片授权服务商Midjourney
PAIR算法的独特之处在于它能够与黑盒模型(如ChatGPT)一起工作,而且它在生成越狱提示时所需的尝试次数较少,而且这些提示具有可解释性,可以在多个模型之间传递。这使得企业能够以经济高效的方式识别和修复其LLMs中的漏洞。
在研究中,研究人员使用了一个名为Vicuna的开源LLM作为攻击模型,并测试了多个目标模型,包括开源模型和商业模型。
研究结果显示,PAIR成功越狱了GPT-3.5和GPT-4的60%的设置,甚至在一些情况下只需要几十个查询,平均运行时间约为五分钟。这明显改进了现有的越狱算法,后者通常需要数千个查询和平均150分钟的攻击时间。
此外,PAIR生成的攻击具有人类可解释性,可以轻松传递到其他LLMs。研究人员认为这是由于PAIR的对抗性提示的语义性质,这些提示针对语言模型中的类似漏洞,因为它们通常是在相似的下一个单词预测任务上训练的。
PAIR算法的出现代表了一种使用LLMs作为优化器的新趋势。以前,用户不得不手动制作和调整提示以从LLMs中提取最佳结果。然而,通过将提示过程转化为可度量和可评估的问题,开发人员可以创建算法,其中模型的输出被循环用于优化,这将加速LLM领域的发展,可能引领领域中的新的和未预见的进展。
台积电推迟亚利桑那州工厂生产 该工厂最终将为 iPhone 和AI生产芯片
台积电将其位于亚利桑那州凤凰城的新工厂开始生产4nm芯片的时间推迟到2025年,原因是劳动力短缺。苹果表示,它打算最终从美国台积电(TSMC)工厂采购iPhone和MacBook机型的芯片,而英伟达和AMD也承诺使用其产能。站长网2023-07-21 15:17:250000谷歌云推出两个新 AI 工具:帮助加速药物发现和实现精准医学
站长网2023-05-17 10:00:140000陶哲轩:GPT-4神助攻,写Python代码轻松省半小时
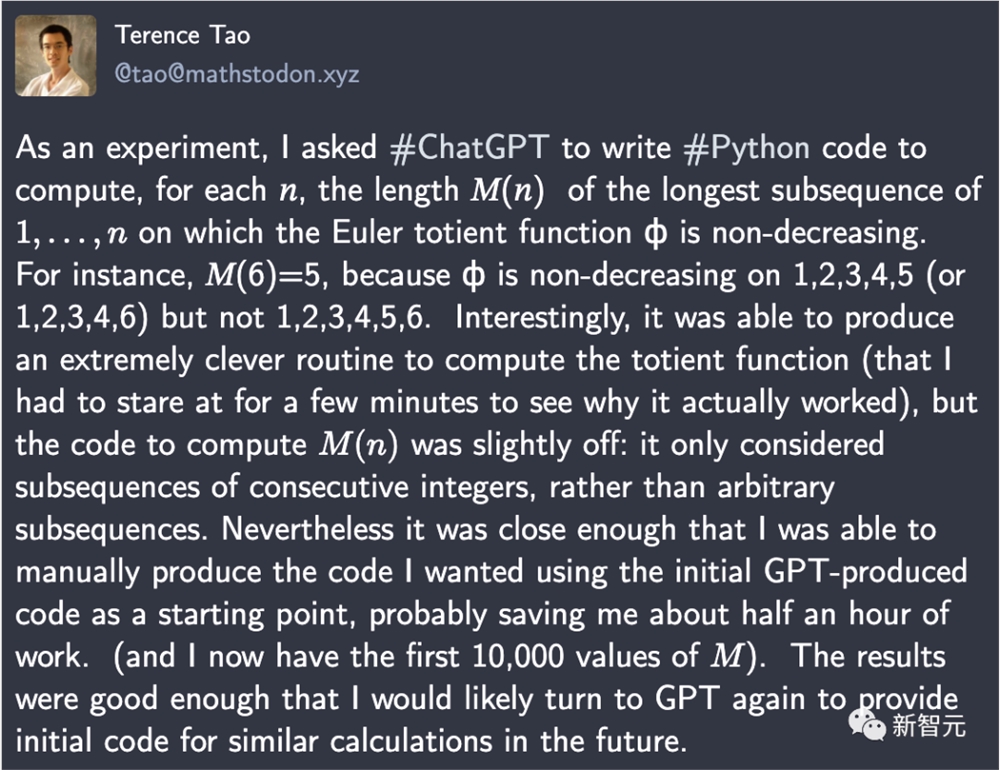
【新智元导读】陶哲轩早就预言,2026年GPT能帮数学家合著论文。今天,GPT-4就帮他写出一段代码,直接节省了半小时的工作量。刚刚,陶哲轩大赞:用ChatGPT写Python代码,效果真是太好了,它直接为我节省了数学研究中半小时的工作量!作为实验,他要求ChatGPT写一段Python代码,为每个自然数n计算1,...,n的最长子序列的长度𝑀(𝑛),其中欧拉全能函数ϕ不递减。站长网2023-09-03 08:59:450000“电商巨头”们的人效比正在重建
当洪流涌向你时,你被淹没,错并不在你。——《去有风的地方》近日,拼多多市值再次超越阿里,“人效”成为了业内的热议话题。虽然目前拼多多还没有实现千亿营收,但市场对它盈利能力的期望早已“不言而喻”。据雪球数据显示,截止5月31日收盘,拼多多的市值为2080.1亿美元,阿里的市值为1894.4亿美元。投资者们在股市的“投票”依据,则来自两家公司的“成绩单”。站长网2024-06-03 15:36:310000麻省理工学院教授称人类面临人工智能「逐底竞争」的风险
站长网2023-10-27 12:00:360001