研究人员教会GPT-4V使用iPhone并在亚马逊应用程序上购物
要点:
1. 《MM-Navigator》是基于GPT-4V的智能代理,通过图像处理和文本推理结合,使其能够在iPhone上执行购物任务。
2. GPT-4V的关键创新在于同时处理图像和文本,使得AI系统能够直接处理真实的智能手机界面截图,而不仅仅是处理文本描述。
3. MM-Navigator在处理多步骤场景方面表现出色,例如成功地在Amazon应用上购买商品,展示了其在理解和与多个界面交互方面的潜力。
在当今智能手机技术不断发展的世界中,对能够导航和与移动应用程序复杂界面进行交互的人工智能的需求不断增加。MM-Navigator通过使用GPT-4V代理来满足这一需求,该代理结合了图像处理和文本推理,使其能够在iPhone上执行购物任务。本文将着重介绍MM-Navigator的技术能力,特别是其对GPT-4V的应用。我们将探讨它如何解释屏幕,决定动作,并与移动应用程序进行准确的交互。同时,我们将关注GPT-4V的关键特性,屏幕理解和动作决策的创新方法,以及实现准确、上下文敏感的应用程序交互的策略。通过这些分析,我们将突显MM-Navigator如何显著缩小了人工智能潜力与智能手机应用功能复杂性之间的差距。

多年来,科学家们一直追求能够像人类一样与计算设备交互并遵循自然语言指令的AI助手目标。随着智能手机的广泛采用,虚拟助手如Apple的Siri变得更加普遍,但它们的能力仍然有限。实现能够执行复杂多步骤任务的智能助手需要在AI模型理解和操作复杂应用程序界面方面取得重大进展。
近年来,AI领域的进展主要是由类似GPT-4的大型语言模型(LLMs)推动的。然而,要控制像智能手机这样的真实设备,AI系统需要超越仅仅处理文本的范畴。它还必须能够解释屏幕上显示的复杂视觉界面,然后执行精确的物理操作,如点击特定按钮或滚动菜单。早期尝试将智能手机截图转换为文本描述,然后将该文本馈入语言模型。然而,这种方法丧失了很多重要的布局和视觉关系信息,这对于识别与之交互的正确界面元素至关重要。
但现在,GPT-4V应运而生!它能够摄取并理解图像和文本的结合。这一发展使得AI系统能够直接处理真实的智能手机界面截图,理解各个组件,并确定智能的操作,而无需将输入简化为仅文本。然而,在将大型多模型模型(LMMs,与LLMs不同)应用于设备控制任务方面仍然存在重大挑战。模型需要能够智能生成一系列的动作,以视觉屏幕输入和提供的文本指令为条件。然后,它必须能够通过点击或点击屏幕上特定区域来精确执行每个动作,这些区域对应于按钮或菜单。这个对于推理复杂界面并产生精确的本地化动作的复杂性使得这成为一个极其困难的问题。MM-Navigator正试图解决这个问题。
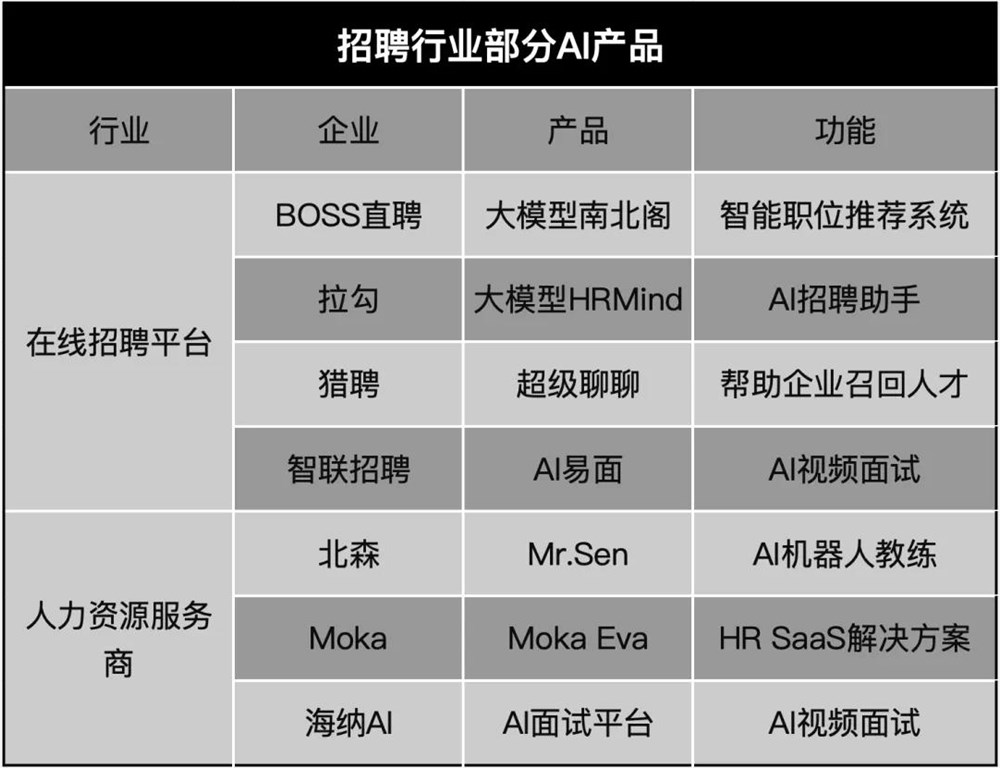
MM-Navigator系统由GPT-4V模型和新颖的提示技术组成,以实现对屏幕位置的精确定位。在高层次上,GPT-4V接收用户提供的文本指令和当前智能手机屏幕的图像作为输入。然后,它产生描述下一步动作的文本输出。为了允许点击屏幕的精确区域,研究人员首先在屏幕图像中的每个交互元素(如按钮和图标)上添加编号标记。GPT-4V可以在生成的动作文本中引用这些数字标签,索引特定的屏幕位置。
由于提供所有过去图像和动作的完整历史会带来计算上的问题,所以在每个步骤中,提示提供了关键过去事件和上下文的自然语言总结。这种自我总结提供了对交互历史的有效近似。GPT-4V的输出文本包含动作的高级自然语言描述,例如“点击发送按钮”,以及像“[Action: Tap, Location: (12)]”这样的数字标签。这种双重输出允许既有人类可读的描述,又有在实际智能手机界面上执行点击或滚动动作的精确坐标。
为了评估MM-Navigator系统,研究人员对两个数据集进行了测试:一个包含他们自己收集的iOS屏幕和指令的数据集,以及一个包含Android设备屏幕和动作的公开数据集。在包含单一动作指令的iOS屏幕上,人类评估发现预期动作的自然语言描述在91%的情况下是合理的。由数字标签选择的实际屏幕位置在75%的情况下是正确的,表明具有良好但不完美的视觉基础能力。
MM-Navigator在处理多步骤场景方面的熟练表现在于其在协助购物等任务中的能力。在论文中,一个例子吸引了我,他们让代理在Amazon上购买了一台奶泡机!该系统成功地在各种应用程序和界面中导航,甚至保持在50-100美元的预算范围内。这张图片摘自论文,详细展示了它的工作原理。在这种情况下,MM-Navigator解释了用户的文本指令和智能手机屏幕上的视觉元素。然后,它确定完成购买所需的动作序列。这可能涉及在购物应用程序中搜索产品,根据价格和产品规格应用过滤器,选择适当的项目,并引导用户完成结账过程。
这展示了MM-Navigator处理复杂、序列任务的能力,这些任务需要理解和与多个界面交互。它不仅展示了该系统在执行单个、孤立动作方面的潜力,还展示了其在管理一系列互相关联步骤方面的潜力,这与人类使用智能手机应用程序完成实际任务的方式相似。
然而,MM-Navigator也存在许多错误情况。在论文的“错误分析”部分,作者们审查了GPT-4V在预测图形用户界面(GUIs)中用户动作时所犯的错误类型。他们确定了两类主要错误:假阴性和真阴性。假阴性通常是由于数据集或注释过程的问题。在某些情况下,GPT-4V的预测是正确的,但由于Set-of-Mark注释解析的不准确或数据集注释不完美而被标记为错误。
这种情况经常发生在GUIs中的目标区域被过度分割或存在多个有效动作的情况下,但注释只认定一个为正确。真阴性错误归因于GPT-4V的零样本测试方法的局限性。由于缺乏示例来指导其对用户动作模式的理解,该模型倾向于点击而不是滚动,导致与典型人类动作不符的决策。例如,GPT-4V可能试图在可见选项卡中找到选项,而不是向下滚动以获取更多选项。它还可能点击不可交互的元素,或者过于字面地解释指令,导致不适当的动作。
总的来说,由GPT-4V模型驱动的MM-Navigator在AI导航和与智能手机界面交互的能力方面取得了有趣的进展。它将大型多模型模型的先进功能与创新技术结合起来,以解释和在移动应用中执行动作。虽然它在理解用户指令和执行任务方面表现出高准确性,但仍然存在挑战,特别是在处理多样化和动态界面元素以及确保与人类行为一致的准确决策方面。
该系统的开发和测试突显了创建能够进行如此复杂交互的AI模型的复杂性,并强调了准确的数据集注释和可调整的测试方法的重要性。如果进一步发展,我能看到这项技术有各种用途 - 自动化QA测试,帮助残障人士,甚至在我们忙于其他工作时为我们完成手机上的任务。看起来很有趣!
小米14Ultra已进入试产阶段 即将开始量产
近日,数码闲聊站透露,小米14Ultra已经进入了试产阶段,并且即将开始量产。这款手机预计最快将在2月底正式发布,届时将与小米平板7系列一同亮相,并与小米汽车SU7实现跨端协同。作为小米的旗舰级产品,小米14Ultra无疑拥有强大的影像能力。与小米14Pro相比,其最大的变化在于配备了1英寸超大底主摄和5倍潜望长焦镜头。这种配置有望为用户带来更出色的拍摄体验。站长网2024-01-25 16:44:130000直播间“贩卖”小哥哥:有人看没人买
没想到,蒙牛用一群“小哥哥”,接住了“从天而降”的流量。近日,有网友发现,蒙牛冰淇淋旗舰店官方账号在抖音开启直播带货,五天七场直播涨粉三万多,平均每场直播涨粉四千多,账号视频点赞量也从个位数增长过万。虽然蒙牛的数据还算不上顶流,但对一个自播品牌,属实算“出圈”。站长网2023-04-22 07:42:040000研究:深度伪造视频中伪造色情视频占98%
**划重点:**1.📈2023年分析揭示,绝大多数在线深度伪造视频为色情内容,其中数量较2019年增长550%。2.👩💻深度伪造色情内容占所有深度伪造视频的98%,受害者中99%为女性。3.🇰🇷韩国成为深度伪造色情内容的主要受害国,部分归因于流行音乐,尤其是女子流行乐队Blackpink。站长网2023-11-13 21:42:390001韩国流行音乐厂牌HYBE利用AI技术6种语言发行歌曲
以BTS防弹少年团而闻名的韩国最大流行音乐厂牌利用人工智能技术,将韩国歌手的声音与其他五种语言的母语演唱者的声音融合在一起,以解决语言障碍问题。该技术使韩国最大的音乐公司HYBE(352820.KS)在5月份以韩文、英文、西班牙文、中文、日文、越南文等6种语言发行了歌手MIDNATT的歌曲。站长网2023-07-20 16:55:590000抖音生活服务上线“安心游”优质出行商品质量保障计划
抖音生活服务正式上线了名为“安心游”的优质出行商品质量保障计划。该计划通过甄选高品质线路商品和设定严格的商品标准,保障消费者在出行过程中的安心体验。消费者通过“安心游”购买服务可以享受到纯玩无购物、透明费用、成团保障、退费拒签保障等权益。同时,入驻“安心游”对商家来说也意味着获得更多的曝光和经营上的支持。站长网2023-09-15 08:31:260000