大模型幻觉率排行:GPT-4 3%最低,谷歌Palm竟然高达27.2%
排行榜一出,高下立见。
人工智能发展进步神速,但问题频出。OpenAI 新出的GPT 视觉 API 前脚让人感叹效果极好,后脚又因幻觉问题令人不禁吐槽。
幻觉一直是大模型的致命缺陷。由于数据集庞杂,其中难免会有过时、错误的信息,导致输出质量面临着严峻的考验。过多重复的信息还会使大模型形成偏见,这也是幻觉的一种。但是幻觉并非无解命题。开发过程中对数据集慎重使用、严格过滤,构建高质量数据集,以及优化模型结构、训练方式都能在一定程度上缓解幻觉问题。
流行的大模型有那么多,它们对于幻觉的缓解效果如何?这里有个排行榜明确地对比了它们的差距。
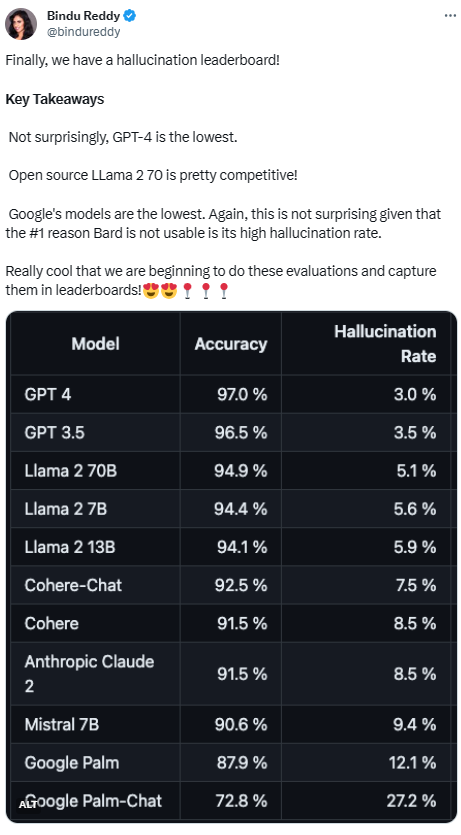
该排行榜由专注于 AI 的 Vectara 平台发布。排行榜更新于2023年11月1日,Vectara 表示后续会随着模型的更新继续跟进幻觉评估。
项目地址:https://github.com/vectara/hallucination-leaderboard
为了确定这个排行榜,Vectara 使用各种开源数据集对摘要模型进行了事实一致性研究,并训练了一个模型来检测 LLM 输出中的幻觉。他们使用了一个媲美 SOTA 模型,然后通过公共 API 向上述每个 LLM 输送了1000篇简短文档,并要求它们仅使用文档中呈现的事实对每篇文档进行总结。在这1000篇文档中,只有831篇文档被每个模型总结,其余文档由于内容限制被至少一个模型拒绝回答。利用这831份文件,Vectara 计算了每个模型的总体准确率和幻觉率。每个模型拒绝响应 prompt 的比率详见 「Answer Rate」一栏。发送给模型的内容都不包含非法或 不安全内容,但其中的触发词足以触发某些内容过滤器。这些文件主要来自 CNN / 每日邮报语料库。
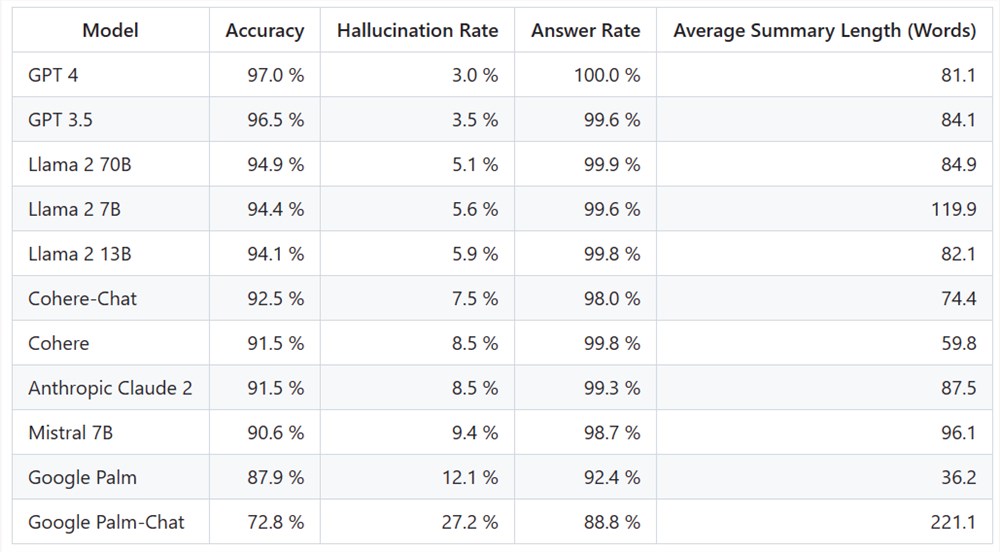
需要注意的是,Vectara 评估的是摘要准确性,而不是整体事实准确性。这样可以比较模型对所提供信息的响应。换句话说,评估的是输出摘要是否与源文件「事实一致」。由于不知道每个 LLM 是在什么数据上训练的,因此对于任何特别问题来说,确定幻觉都是不可能的。此外,要建立一个能够在没有参考源的情况下确定回答是否是幻觉的模型,就需要解决幻觉问题,而且需要训练一个与被评估的 LLM 一样大或更大的模型。因此,Vectara 选择在总结任务中查看幻觉率,因为这样的类比可以很好地确定模型整体真实性。
检测幻觉模型地址:https://huggingface.co/vectara/hallucination_evaluation_model
此外,LLM 越来越多地用于 RAG(Retrieval Augmented Generation,检索增强生成)管道来回答用户的查询,例如 Bing Chat 和谷歌聊天集成。在 RAG 系统中,模型被部署为搜索结果的汇总器,因此该排行榜也是衡量模型在 RAG 系统中使用时准确性的良好指标。
由于 GPT-4一贯的优秀表现,它的幻觉率最低似乎是意料之中的。但是有网友表示,GPT-3.5与 GPT-4并没有非常大的差距是令他较为惊讶的。

LLaMA2紧追 GPT-4与 GPT-3.5之后,有着较好的表现。但谷歌大模型的表现实在不尽人意。有网友表示,谷歌 BARD 常用「我还在训练中」来搪塞它的错误答案。

有了这样的排行榜,能够让我们对于不同模型之间的优劣有更加直观的判断。前几天,OpenAI 推出了 GPT-4Turbo,这不,立刻有网友提议将其也更新在排行榜中。

下次的排行榜会是怎样的,有没有大幅变动,我们拭目以待。
参考链接:
https://twitter.com/bindureddy/status/1724152343732859392
https://twitter.com/vectara/status/1721943596692070486
华硕计划推出基于英伟达芯片构建的 AI 系统服务 AFS Appliance:企业数据安全可控
华硕计划推出一项服务,让企业能够充分利用生成式人工智能的潜力,同时保持对其数据的控制权。这项名为AFSAppliance的服务的新颖之处在于所有硬件将安装在客户自己的设施中,以维护安全性和控制权。这个基于英伟达公司芯片技术构建的AI计算平台将由华硕运营和更新数据。站长网2023-05-31 11:46:510000GPT-4 MATH准确率最高涨至84.3%!港中文、清华等七所顶尖高校提出全新CSV方法
【新智元导读】让模型用代码自我验证解决方案,结合多数投票集成机制,推理准确率可以提升近30%!虽然大型语言模型(LLMs)在常识理解、代码生成等任务中都取得了非常大的进展,不过在数学推理任务上仍然存在很大改进空间,经常会生成无意义、不准确的内容,或是无法处理过于复杂的计算。站长网2023-09-01 18:12:490000抖音治理面向老年人流量收割违规行为 打击冒充名人、土味儿情话诱导等问题
抖音宣布,将持续开展老年人保护相关的内容治理专项,对各类面向老年人进行“流量收割”的违规现象进行升级治理,重点打击冒充名人、土味儿情话诱导、利用老年人卖惨博流量、领收益骗互动的四大违规行为。部分代表性案例如下:一、冒充名人0000眼馋GPTs的人有福了,我们找到了一款不用花钱的平替
AI能替我完成工作吗?在研究AI的过程中,这个问题时常出现在我的脑海。比如关注我们的朋友应该知道,“头号AI玩家”有一个每日更新AI行业资讯的栏目「AI日报」,平时,我们的同事会轮流搜集信息进行整理编辑。这样的内容,可以让AI来帮我们完成吗?我试着用Poe做了一个新闻快讯AI机器人,来测试这一想法的可行性(至于Poe是个什么产品,我会在后文会进行解释)。站长网2023-11-13 21:47:380003