对话蚂蚁李建国:当前AI写代码相当于L2.5,实现L3后替代50%人类编程
超70%代码问题,单纯靠基座大模型是解决不了的;
未来3-5年,人类50%编程工作可以被替代,有些环节甚至完全自动化。
蚂蚁集团代码大模型CodeFuse负责人李建国说道。
当下,AI代码生成领域正在野蛮式生长,巨头涌入,AI员工频频上线企业;首个AI程序员Devin被曝造假…… 面对风起云涌的代码生成变革,李建国给出了这样一个明确论断。
李建国是谁?
清华大学博士,机器学习、深度学习深耕十余年,论文被引万余次。在他的带领下,蚂蚁内部正全面推行AI编程。每周已有超五成程序员使用CodeFuse,目前CodeFuse生成代码整体采纳率为30%,已经属于整个AI编程工具中能力第一梯队,最强*代码整体采纳率差不多在35%。

图源备注:图片由AI生成,图片授权服务商Midjourney
而在开源这边,在各社区网站上CodeFuse下载量已经达到170万左右。
因此不管是学术的权威性,还是产业落地的代表性,李建国博士极具话语权。于是在代码生成模型和产品爆发式发展的当下,量子位同李建国博士展开了进一步交流。
核心观点如下:
编写代码在整个企业研发过程中所占的比重可能连1/5,甚至1/10都不到;
要实现项目级的需求实现,从原子级需求端到端渐进发展的模式是切实可行的;
AI程序员成为企业运营中的新常态已经是势不可挡的趋势;
超70%代码问题,单纯靠基座大模型是解决不了的;
目前自然语言编程处于L2.5阶段,按照万物摩尔定律的发展趋势,未来3-4年达到L3,甚至接近L4的水平是有可能的。
相较于前、后端的软件工程师,AI全栈工程师需求更大。
当前代码生成变革所面对的挑战包括:端到端代码生成能力、Agent推理能力、复杂需求拆解、跨模态横向交互、安全可信可靠。
编写代码只占整个研发生命周期1/5不到
首先,程序员这个行业历史并不算长,从20世纪50年代至今,大约有七八十年的历史。随着技术的进步,编程工具不断更新迭代(打孔- VI编辑器-集成开发环境-辅助编程工具),程序员的工作效率得到了显著提升。
来到大模型时代,相关模型和产品演化迭代十分迅速,可以说十分的“卷”。
对个人开发者而言,AI编程工具只需完成从需求到代码实现的闭环过程就够了,就像*这样的工具。他们更倾向于关注如何高效地实现需求。
但从企业维度则更关注整个研发流程的效率提升,除了关注代码生成的安全可靠可信,测试构建、发布运维以及数据洞察等方面也是至关重要的。
我们期望能够有一个研发智能体,甚至是一个智能总线(bus),它能够与各个Agent进行交互,并将任务分发下去——从架构设计到前端实现,再到后端开发,以及安全测试和功能测试,最后是效能方面的持续集成/持续部署(CICD)和运维自动化。
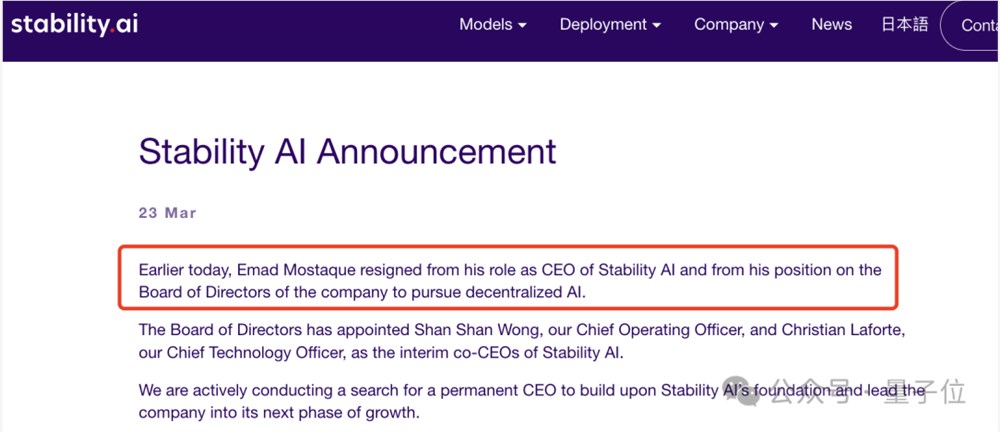
△测试-自然语言生成终端用例
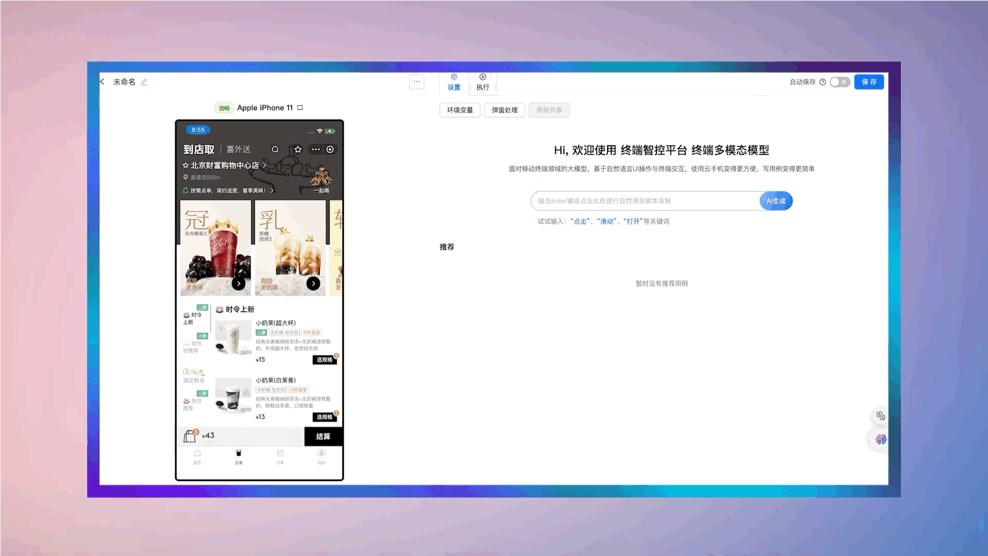
整个系统上线后,还能够自动进行运维布控,并分析产品的用户访问量(UV)、页面浏览量(PV)等数据。
△运维-监控解读
编写代码在整个过程中所占的比重可能连五分之一或十分之一都不到。但如果这样的Agent能将所有环节高效连接起来,从而真正提升整个流程的效率。
再加上当前程序员实际所面临的痛点在于,市面上一些产品大多是原子级能力的实现——通过单体大模型只能解决30%的代码补全,无法解决更多的代码问题,比如跨库的函数调用。
基于这样的行业思考,去年9月份开始,我们开源了CodeFuse,并明确提出要构建全生命周期的代码大模型。
目前,我们已经发布基础模型,并持续开发和开源相关的仓库,涵盖了从需求设计、编程开发、测试构建、发布运维、到数据洞察分析等多个方面,在modelscope和huggingface上模型下载量已经达到170万左右。
下一步,我们计划进行项目级的需求实现,这相当于去实现一个全新的系统。这对基础模型提出更高的要求——
自然语言理解的能力至少达到GPT-4或GPT-4.5的水平。但从目前的情况来看,我们更倾向于采取一种渐进的模式。
我们首个MileStone是解决仓库内及跨仓库的需求实现问题,包括API调用、服务调用,以及涉及到的外部中间件版本更新问题。
如果我们能够妥善处理这些问题,就能解决刚才提到的70%问题中很大一部分(比如20%的问题),这将显著提高代码采纳率,并让用户感到满意。
最终要实现项目级别的需求任重而道远。我认为,代码基础模型和Agent技术需要同步快速发展,才能达到我们的目标。
我们的思路相对保守,因为就基础模型的要求而言,我认为短期内国内要达到GPT水平还存在一定差距。
大模型对软件开发的范式改变
AI程序员成为企业运营中的新常态已经成为势不可挡的趋势。不管是像Devin这种AI程序员,还是我们提到的全生命周期研发智能体,大模型对整个软件研发范式都是非常大的提效。
过去遇到不懂的问题,人们可能首先会去Google或百度上搜索,而现在,他们可以直接在代码中提问,随即获得一个相对精确的结果,采纳后即可使用。
我认为这是一个巨大的效率提升,它代表着进步。人们可以将更多的精力释放出来,投入到更具创造性的工作中去。
前段时间,CodeFuse发布了图生代码的功能,它可以通过在界面上简单画一个框,就能自动生成相应的代码。
以往可能需要编写数百行代码的工作,现在只需一次点击和画框操作就能实现。
而要从产品设计的角度来看,我认为实现无缝接入和无感体验是至关重要的。
这意味着产品应能平滑地融入现有的工作模式中,用户在使用过程中几乎不会意识到它的存在,从而极大地提升用户体验,并推动整个研发流程的创新和进步。
例如,我们内部每周有超过一万人的智能代码生成活跃用户,很多人都没意识到自己在使用CodeFuse,在日常使用IDE插件、浏览器的过程中,用户已经不知不觉地使用了我们的产品。
我们的目标是服务于整个研发的全生命周期。如果能够实现这一点,那将是一个革命性的成功。
现在AI写代码相当于L2.5
目前整个代码生成领域,可能处于一个类似于自动驾驶技术中的L2.5级别,许多公司都处于这一水平。
比如自动驾驶L2.5级别的功能,如车道线辅助、前方碰撞检测等,这些都是作为整体存在的一部分。在大模型领域,也看到了类似的补充功能,包括解释、注释、简化优化和单元测试等。
我们接下来的目标是在某些特定场景下实现L3级别的完全自动化,这是有可能实现的。例如,在效能领域中的持续集成(CICD)场景,就有可能通过大模型的驱动来自动完成,包括触发检查、提交,甚至创建拉取请求(PR)等操作。
然而,要实现全场景、全链路的自动化,前端可能还需要一段时间才能发展起来,复杂的项目级的需求拆解特别是特定领域的拆解,也面临较大挑战。我认为可能还需要3-5年的时间,在万物摩尔定律的推动下,整个社区,包括我们自己的不断努力和发展。
到那时候,我们可以期待从当前的状态发展到一个新的阶段——
例如,从*到co-worker,现在可能有20%到30%的编程工作可以被替代,未来这个比例可能会提高到50%,甚至有些环节可以完全被自动化取代,释放人去做更有创意的工作。
甚至成为一个full agent。虽然可能无法完全替代人类,但在未来3-5年内,达到L3甚至接近L4的水平是有可能的。
正如自动驾驶技术一样,虽然已经提出很多年,许多人声称已经达到L4级别,但实际上许多场景仍然处于L2.5到L3级别。要实现全场景的自动化,人类仍然需要在其中扮演一个重要的角色。
这样一来,软件工程人员的定位其实也在发生变化。以前大家可能专注于前端或后端的开发工作。而现在,AI全栈工程师的需求更大。
过去所谓的全栈工程师意味着前端、后端和数据都懂,但现在可能还需要理解算法。随着大模型发展,前端和后端的工作可能会逐渐由大模型辅助,即作为协作者(Co-worker)来分担部分功能,从而释放出开发者的时间。这样开发者就可以将更多时间投入到提升新的技能上,比如对产品的深入理解,对用户体验的关注,对算法创新等。
基于对整个领域进行了深入的探索,我发现要进一步去实现还有不少挑战,主要有五个方面:
端到端代码生成能力
基础模型层面,目前主要是实现代码补全的功能,但在实际应用中只有大约30%问题可以通过这种方式解决,剩余的70%则需要端到端代码生成能力,需要跨文件、跨代码库,甚至跨代码库和文档库的理解和交互。
所谓的端到端,对于一个代码库而言,一个典型的例子,我们需要能够直接调用库中的API,修复问题(issue),甚至能够复用跨库的中间件能力。
然而,仅凭基础模型是无法实现这些的,我们还需要探索更多的能力。
Agent推理能力
尽管最近Devin 被曝出演示视频存在造假,备受关注,但我认为它还是代表了一种趋势、一种技术流派——
如何将定制工具调用与大型模型相结合,实现整个工作流程的自动化。这个问题,尤其是扩展到全生命周期,实际上相当困难,尤其是面向云后端的研发环境,工具种类繁多。
比如面向前端应用可能只有天气预报、查询火车票、预定酒店等十几个工具,但在云后端,则可能会有数百个甚至上千个工具,每个工具都包含数十个参数。
除此之外,还有需求拆解、跨模态横向交互、安全可信可靠的挑战。
尤其代码的安全可信可靠,像蚂蚁这样的企业级用户,需要应对面向金融级别的高可用性和安全性的要求,也充满了挑战。
不过也正因为在金融级垂直场景的深耕,包括资源配置和历史经验积累,蚂蚁也构成了属于自己的场景优势。
首先,我们拥有涵盖整个生命周期各个环节全方位的团队,尤其在双十一等大型促销活动期间的高可用性方面经验丰富,这有助于推进全生命周期的代码大模型,这是我们与外部的主要区别之一。
其次,我们在特定领域,如金融领域,以及前端领域,都有一定经验积累,尤其是在支付系统等对安全性要求极高的场景中。这些积累使我们在安全性、可靠性和可信度方面具有差异化优势。
虽然挑战不少、道阻且长,但我认为,蚂蚁将携手开源社区一起努力,在万物摩尔定律的牵引下,未来两三年可以一定程度解决好这个问题。
One More Thing
最后,面对当下大模型发展,李建国博士忍不住感叹:
我以前做深度学习,那时候非常卷,可能2019年之前,我发现这个领域已经卷不动了,跳出来做NLP,发现这个领域也还是更加的卷。
但不得不承认,大模型再次点燃了NLP、视觉处理、代码生成等各个领域的热度,焕发新的活力。
对于接下来的发展,李建国点名最看好具身智能的发展,这将是未来5到10年的研究热点。
它将成为数字世界与物理世界之间的桥梁,能够感知并执行操作。这可能会带来类似Matrix(黑客帝国)这样的场景的巨大进步,甚至可能像电影《终结者》中展示的那样,成为真正的巨大飞跃。
Comfyspace插件更新 新增模型管理功能
最近,Comfyui工作流管理插件Comfyspace进行了升级更新,新增模型管理功能。现在,你可以点击右上角的模型按钮,查看你已有的模型文件。同时,该插件会根据模型文件同步Civitai的模型封面图,不再需要通过文字来猜测模型了。下载地址:https://top.aibase.com/tool/comfyspace站长网2024-02-06 09:53:360000Salesforce 和埃森哲合作创建生成式人工智能加速中心
Salesforce和全球专业服务公司埃森哲合作,以加速跨客户关系管理(CRM)技术部署生成式人工智能。两家公司计划为生成人工智能建立一个加速中心,让客户能够扩展Salesforce的EinsteinGPT,这是一种用于CRM的生成人工智能工具。站长网2023-05-05 10:51:070000只需一个眼神!韩国医学院使用AI筛查自闭症:准确率100%
快科技12月21日消息,据媒体报道,韩国延世大学医学院近日发布了一项研究成果:可用深度学习后的人工智能算法,对儿童的视网膜照片进行分析,从而检测儿童是否患有自闭症谱系障碍(ASD)。据悉,在本次实验中,研究人员共召集了900多名年龄在7-8岁的儿童,其中有一半的儿童都患有了自闭症。随后,研究人员拍摄了所有参与者的视网膜照片。随后,研究人员使用深度学习算法分析照片与症状严重程度评分之间的关联。0000SK 电讯推出利用人工智能技术降低云成本的 Cloud Radar 2.0
站长之家(ChinaZ.com)10月18日消息:SK电讯周三宣布,推出CloudRadar2.0,这是一款利用人工智能技术的云管理平台,旨在帮助企业降低其云计算服务成本。站长网2023-10-18 22:32:520000谷歌祭出多模态“杀器” Gemini真能碾压GPT-4吗?
“最大”、最有能力”、“最佳”、“最高效”,谷歌为其12月7日新发布的多模态大模型Gemini冠上了好几个“最”,与OpenAIGPT-4“比高高”的胜负欲呼之欲出。区分为Ultra、Pro、Nano三个尺寸的Gemini,不仅号称在各种“AI考试”中得了“高分”,演示视频里显示的Gemini简直就是“听说读写”样样拿的“超级工具”。0000