LLaVA++:为Phi-3和Llama-3模型增加视觉处理能力
站长网2024-04-28 16:57:260阅
LLaVA 项目通过扩展现有的LLaVA模型,成功地为LLaVA 和Llama-3模型赋予了视觉能力。这一改进标志着AI在多模态交互领域的进一步发展。
主要创新点包括:
模型整合: LLaVA 将Phi-3和Llama-3模型进行整合,创建了具备视觉处理能力的Phi-3-V和Llama-3-V版本。
图像理解与生成: 新模型不仅能够理解与图像相关的内容,还能生成视觉内容,扩展了模型的应用范围。
复杂指令执行: 增强的视觉处理能力使得模型能够更准确地理解和执行与视觉内容相关的复杂指令。
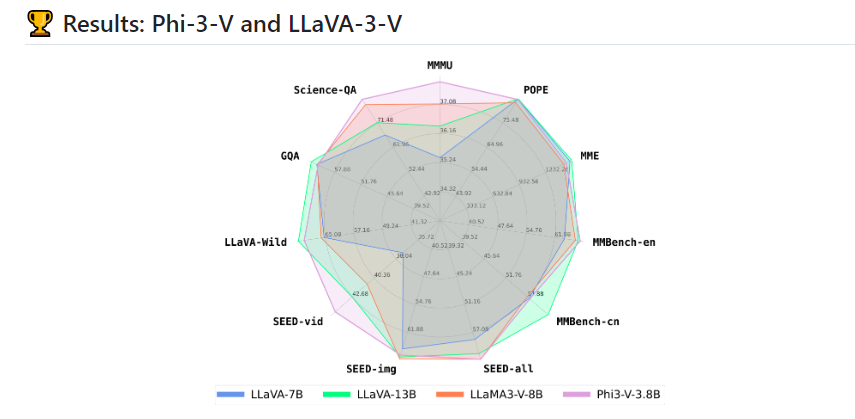
学术任务处理: 在需要同时理解图像和文本的学术任务中,LLaVA 展现了更高的准确率和效率,提升了模型的学术研究和教育应用潜力。
LLaVA 的优势:
通过赋予Phi-3和Llama-3视觉能力,LLaVA 项目不仅提升了AI模型的多模态交互能力,还为图像识别、视觉问答、视觉内容创作等领域带来了新的机遇。这种跨模态的能力增强,使得AI模型在执行需要视觉和文本结合的任务时更加得心应手。
LLaVA 的推出,预示着未来AI模型将更加智能和灵活,能够更好地服务于需要视觉与文本结合理解的复杂场景。
项目地址:https://top.aibase.com/tool/llava-
0000
评论列表
共(0)条相关推荐
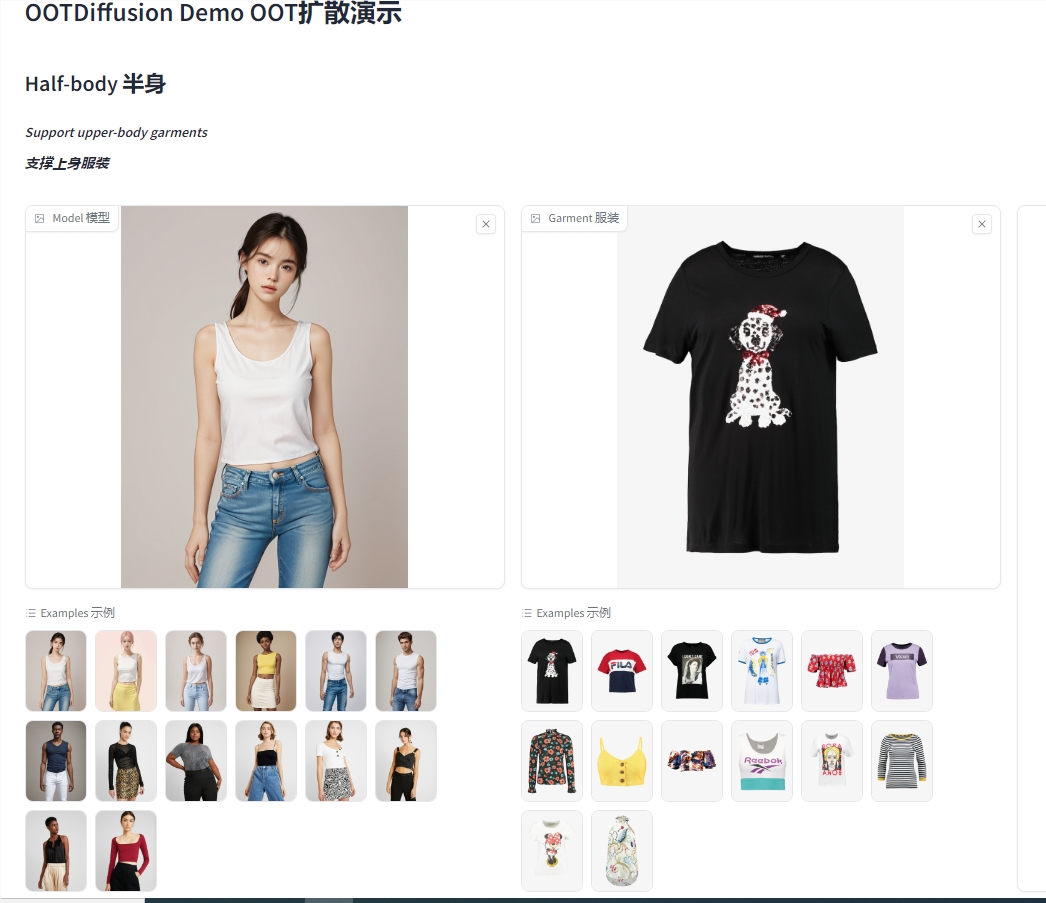
OOTDiffusion:一个高度可控的虚拟服装试穿AI工具
OOTDiffusion是一个高度可控的虚拟服装试穿开源工具,经过测试,效果非常出色。该工具可以根据不同性别和体型自动调整,与模特身形非常贴合。同时,用户也可以根据自己的需求和偏好调整试穿效果。此外,OOTDiffusion支持两种模式:半身模型和全身模型。在主要功能方面,OOTDiffusion利用潜在扩散模型的先进技术实现了高质量的服装图像生成和融合,确保试穿效果自然逼真。站长网2024-02-21 10:03:540001文娱行业的618:粉丝韭菜不好割,消费者的钱也不好赚
剧综流量一般,直播带货狂飙。“直播带货”的风,在这个618期间,吹向了整个文娱行业。早在两年前,明星直播带货碎滤镜的讨论已经甚嚣尘上。当明星们无戏可拍时,走进直播间卖低价产品成了他们的选择,伴随着统一色调的滤镜、嘈杂的叫卖声、以及偶尔的讲价演戏,艺人们的星光也相应黯淡。站长网2023-06-18 23:41:070000董明珠谈接班人:一把手要把企业视为自己的生命
格力接班人一直是外界关注的问题,在在6月30日格力电器股东大会上,格力电器董事长董明珠再度谈到接班人问题的看法。董明珠表示不乏有人想接班,但怎么样的人才能接班,企业内部发展有自己的规矩。“诚信的企业才能培养出优秀的人,志不同不为谋。”她还表示企业一把手要把企业视为自己的生命,要有奉献的精神。站长网2023-06-30 22:52:320001谷歌已悄然将下一代人工智能模型 Gemini 推迟到 2024 年 1 月推出
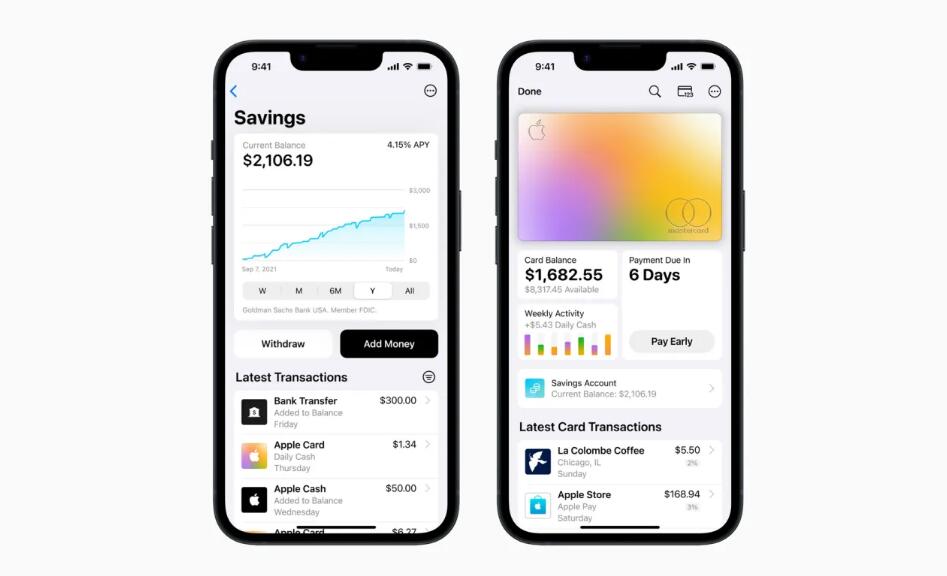
谷歌在I/O2023上宣布Gemini作为其下一代基础模型。据今天的报道称,谷歌原定于下周推出Gemini,但现在已推迟到明年一月份。据《TheInformation》报道,Gemini原本计划在下周通过在加利福尼亚、纽约和华盛顿的一系列活动中进行大规模揭幕,这是针对政治家和政策制定者的。站长网2023-12-03 11:05:500000上线四个月“苹果版余额宝”用户存款已超过 100 亿美元
苹果今天宣布,高盛提供的AppleCard高收益储蓄账户自4月份推出以来,用户存款已超过100亿美元。储蓄账户的APY(年收益率)为4.15%。站长网2023-08-03 10:41:330000