微软推出全新预训练模型phi-1.5 仅13亿参数常识推理碾压Llama2
站长网2023-09-18 10:01:440阅
要点:
1、微软研究人员推出了一个仅有13亿参数的LLM模型Phi-1.5。
2、Phi-1.5在常识推理任务上表现优异,优于多个参数量十倍以上的模型。
3、研究表明,模型参数规模不是决定性因素,高质量数据更为重要。
微软研究人员最近在一篇论文中提出了一个新的语言模型Phi-1.5,该模型的参数量仅有13亿。研究人员主要关注Phi-1.5在常识推理方面的表现,因为这是对语言模型能力的重要考验。
论文地址:https://arxiv.org/abs/2309.05463
项目地址:https://huggingface.co/microsoft/phi-1_5
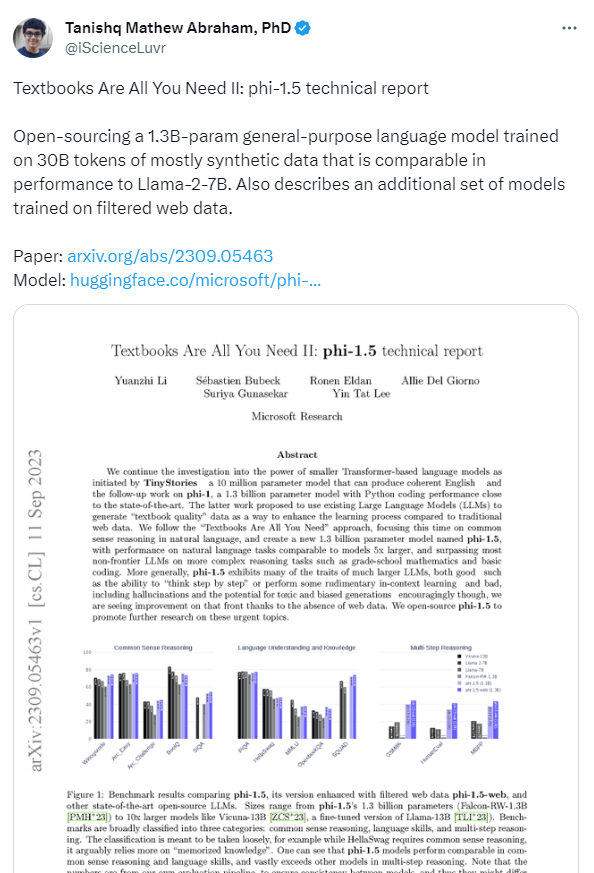
结果表明,Phi-1.5在多个常识推理基准测试数据集上都取得了与参数量是其10倍以上的模型相当或更好的结果。例如在WinoGrande、ARC-Easy、ARC-Challenge、BoolQ和SIQA等数据集上的表现,都与Llama2-7B、Falcon-7B和Vicuna-13B相当甚至更好。
这说明模型的参数规模不是决定性因素,采用高质量合成数据进行预训练可能更为关键。研究中,Phi-1.5使用了微软之前提出的Phi-1模型的训练数据,以及新增的“教科书级”合成数据进行训练。
结果表明,Phi-1.5不仅展现出许多大模型所具有的语言理解和推理能力,在控制有害内容生成方面也具有一定优势,这对研究大型语言模型的社会影响意义重大。本研究表明,相比单纯追求模型规模,如何获取高质量训练数据可能更为重要,这为未来语言模型研究提供了新的思路。
0000
评论列表
共(0)条相关推荐
OpenAI与迪拜G42合作,瞄准扩张中东市场
划重点:1.🤖OpenAI与G42达成合作,旨在在中东地区扩展人工智能能力。2.🌍合作计划在G42的专业领域,如金融、能源、医疗和公共服务中,利用OpenAI的生成式人工智能模型。3.💡合作被视为将AI解决方案带入中东地区,并提升全球扩张计划的关键一步。OpenAI与总部位于迪拜的科技控股集团G42宣布了一项新的合作伙伴关系,旨在扩展中东地区的人工智能能力。站长网2023-10-19 11:57:580000阿里云发布通义千问2.5版 性能赶超GPT-4 Turbo
阿里云今日正式发布通义千问2.5版本,该版本在模型性能上全面赶超了GPT-4Turbo,展现了其强大的技术实力。与此同时,通义千问最新开源的1100亿参数模型Qwen1.5-110B在多个基准测评中取得了卓越成绩,超越了Meta的Llama-3-70B模型,成为开源领域的新星。站长网2024-05-09 19:41:540000今年被众多VC一致看好的AI应用,为何是它们?
2023,眼看着只剩下不到两个月的时间了。在今年兴起的这股AI浪潮中,哪种AI应用是最有前景,最值得下注?关于这点,投资界似乎已经达成了一致的共识。最近,一家专注于AI的新闻平台AIbeat统计出了全球10家估值最高的人工智能初创公司。如果人们对表格中的企业进行筛选,就会发现,其中有超过半数以上的产品,都属于同一类AI应用。站长网2023-11-03 16:37:090000蔚来秦力洪:电动车电池寿命15年 蔚来车主的电池则是永生的
快科技6月14日消息,第十六届中国汽车蓝皮书论坛于6月14日-16日在北京举行,主题为想象”,蔚来联合创始人、总裁秦力洪出席并演讲。秦力洪表示,根据今天的可见的技术发展,我们定义的长寿命电池就是15年的使用寿命;并且到了电池寿命终止的时候,它的健康度还要大于等于85%。站长网2024-06-14 23:51:010000小米MIX Fold 3入网:支持67W快充 8月发布
根据3C认证最新数据显示,型号为2308CPXD0C的新机通过了认证,并支持67W快充,预计这款新机很可能就是小米MIXFold3。站长网2023-07-12 15:39:580000