多模态大模型MMICL霸榜 支持文本图像视频输入
要点:
1、MMICL在多模态能力评测中表现突出,支持文本图像视频三种模态输入。
2、采用两阶段训练,可实现“现学现卖”,有效缓解视觉语言模型中的语言偏见。
3、已开源可商用的Flan版和仅科研用的Vicuna版,都发布在GitHub。
最近,北京交通大学等机构联合推出了新多模态大模型MMICL。它支持文本、图像、视频三种模态的混合输入,在多项多模态能力评测中表现抢眼。
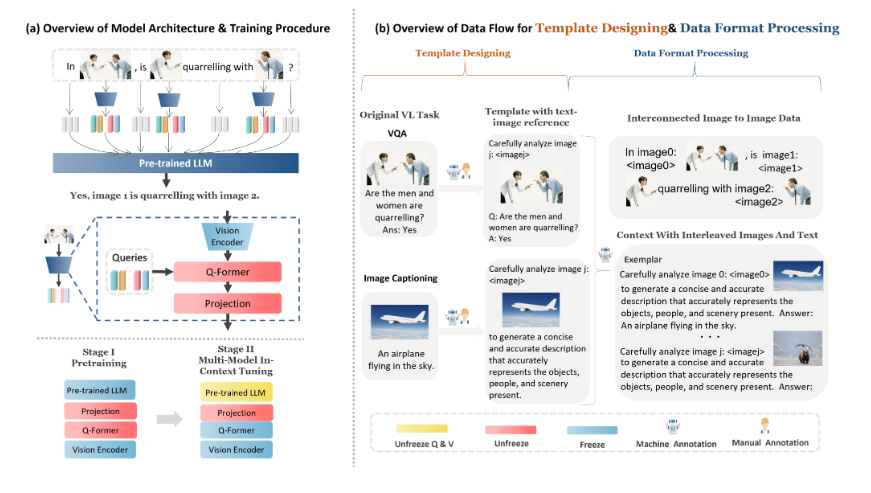
MMICL在MMBench和MME两项多模态测评中均获得不俗的成绩。它采用Flan-T5XXL作为基础模型,通过两阶段训练完成。第一阶段是预训练,使用大规模数据集;第二阶段是多模态上下文微调,使用自建包含丰富多模态样本的MIC数据集。这种训练方式让MMICL既具备强大的语义理解能力,又特别适合处理复杂的多模态输入。
项目地址:https://github.com/HaozheZhao/MIC
MMICL使用了VCR、VQAv2、GQA、COCO、NLVR2等多种数据源。研究人员将这些数据转换成了少样本式数据,存储在jsonl文件中,形成了带有0到少样本的多指令式数据。研究使用python数据预处理脚本,将数据转换为后续训练的原始化数据。数据格式支持交错的图像文字输入,相关图像输入以及语境示范输入。
MMICL最大的特色在于同时接受文本和图像的交错输入,就像微信聊天一样自然。它可以分析两张图像的关系,也可以从视频中提取时空信息。如果给它一些示例,MMICL还能进行“现学现卖”,对未知知识进行类比和推理。研究团队表示,MMICL成功缓解了视觉语言模型中的语言偏见问题,避免在大量文本输入时忽视视觉信息。
MMICL的核心功能包括:
1)理解并推理多幅图像之间的关系;
2)人工构建的语境训练数据,支持语境学习;
3)状态最先进的多模态建模能力。
目前,MMICL已开源两个版本,分别基于FlanT5XL和Vicuna模型,可满足商用和科研需求。该模型支持多种互动方式,开发者可以通过GitHub获取代码和模型进行试用。诸如图像分类、视频理解等多模态任务,都可以基于MMICL得到进一步提升。
总体来说,MMICL是新兴的多模态预训练模型中的佼佼者。它具备处理复杂多模态输入的能力,支持各种多模态任务精调。MMICL的开源发布为多模态AI的研究和应用提供了新的选择。随着其性能和适用场景的不断优化,MMICL有望成为多模态领域的新宠。
Design2Code:提供设计图,让多模态LLM自动生成前端代码
划重点:⭐️生成AI在近年来取得了快速进展,具有前所未有的多模态理解和代码生成能力。⭐️研究对可视化设计转换为代码实现的任务进行了系统研究,提出了一套自动评估指标。⭐️GPT-4V在任务中表现出色,生成的网页在视觉外观和内容方面有望取代原始参考网页。站长网2024-03-07 16:44:190000中消协出手:反对扫码强制关注公众号 全国范围可举报
快科技6月20日消息,近年来,随着移动支付和二维码的普及,很多餐厅等场所都采用扫码点单。需要注意的是,绝大多数商家都会设置成强制关注公众号才能点单的模式,不关注无法操作。其实《消费者权益保护法》第九条第二款早就有明确规定:消费者有权自主选择提供商品或者服务的经营者,自主选择商品品种或者服务方式,自主决定购买或者不购买任何一种商品、接受或者不接受任何一项服务。”站长网2023-06-21 15:13:140000大模型托管平台Replicate获得2.9亿元B轮融资
**划重点:**1.💰Replicate成功完成由a16z领投的2.9亿元B轮融资,英伟达、YCombinator等跟投。2.🌐Replicate开源平台提供超过25,000个模型,涵盖文本、图片、视频、音频、3D模型等领域,注册用户超200万,付费用户超3万。0000分析显示:AI 女友比 AI 男友更受欢迎,下载量多七倍
站长之家(ChinaZ.com)3月16日消息:根据AppRadar和专注于应用增长解决方案的公司SplitMetrics的分析,AI女友比AI男友更受欢迎,大约多七倍。AI伴侣的受欢迎程度飙升,SplitMetrics发现,在GooglePlay商店中,AI伴侣应用已达到2.25亿的终身下载量(LifetimeDownloads)。站长网2024-03-16 13:45:110000苹果介绍设备端神经网络驱动的「个人声音」辅助功能:残疾人可使用 iPhone 保留自己的声音
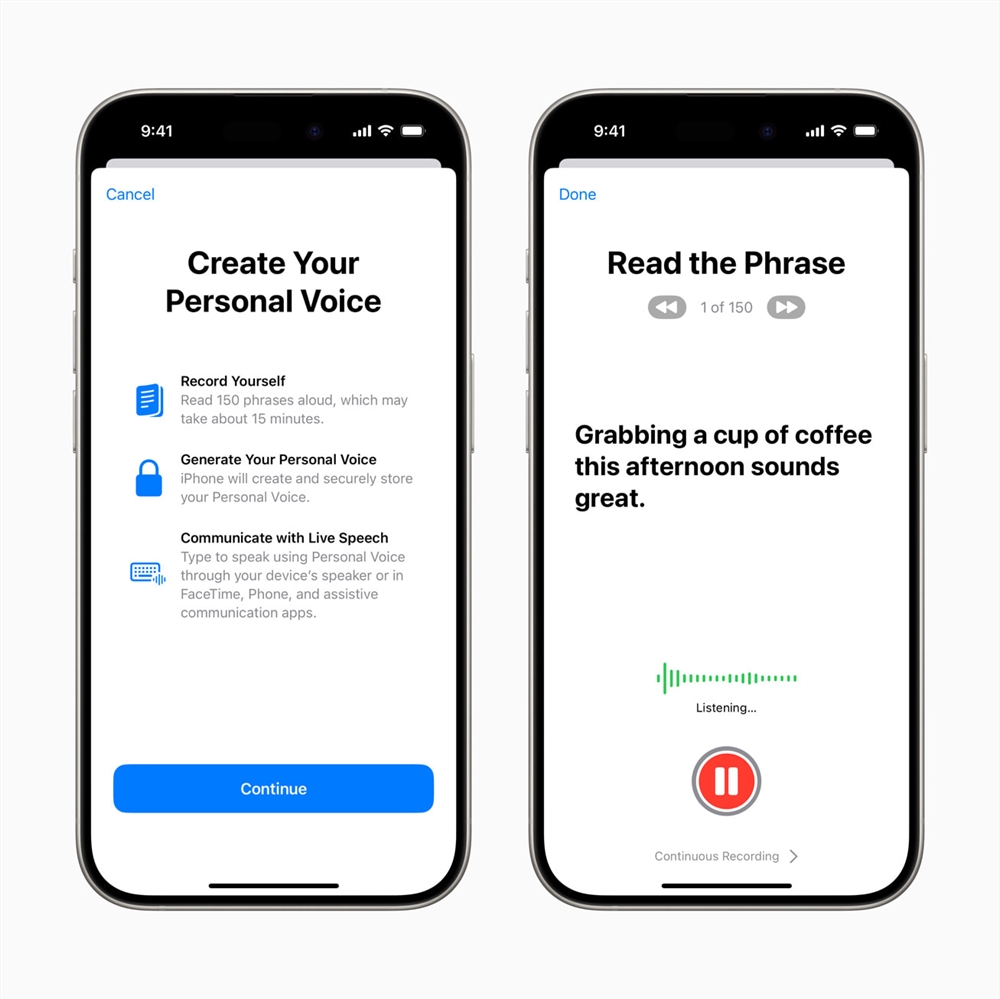
今天,苹果分享了一个温馨的广告,展示了其新推出的「个人声音」辅助功能,该功能适用于iPhone、iPad和Mac。图片来自Apple苹果公司在iOS17.iPadOS17和macOSSonoma中引入的个人声音功能允许那些面临失去语言能力风险的用户创建一个类似于他们实际声音的合成语音,以便他们能继续与他人交流。站长网2023-12-01 16:52:580000