GPT-4太烧钱,微软想甩掉OpenAI?曝出Plan B:千块GPU专训「小模型」,开启必应内测
GPT-4太吃算力,微软被爆内部制定了Plan B,训练更小、成本更低的模型,进而摆脱OpenAI。
GPT-4太吃算力,连微软也顶不住了!
今年,无数场微软AI大会上,CEO纳德拉台前激动地官宣,将GPT-4、DALL·E3整合到微软「全家桶」。
微软全系产品已被OpenAI的模型重塑,愿景是让AI成为每个人的生活伴侣。

然而在幕后,因GPT-4运行成本太高,微软却悄悄地搞起了plan B。
The Information独家爆料称,为了摆脱对OpenAI的依赖,由Peter Lee领导的1500人研究团队中,一部分人转向研发全新对话式AI。

据称,研发的模型性能可能不如GPT-4,但参数规模小,研究成本更低,运行速度更快。
目前,微软已经在必应聊天等产品中,开启了内测。
不仅是微软,包括谷歌在内的其他科技巨头,正在另辟蹊径,以在AI聊天软件和芯片两方面节省成本。
而Llama2宣发时微软与Meta的合作,也不啻是一种摆脱完全依靠OpenAI的手段。
这是微软帝国继续向前成长、突破当前局限,注定要走的路。
更「精炼」的模型,必应先尝鲜
今年2月,微软正式发布新必应(New Bing),其中结合了ChatGPT和自家的普罗米修斯(Prometheus)模型。
在GPT-4公布后,微软紧接着宣布,GPT-4整合到必应中,将搜索体验带上了一个新台阶。
微软搜索主管Mikhail Parakhin近日表示,Bing Chat目前在「创意」和「精准」模式下使用的是100%的GPT-4。
而在平衡模式下(多数用户选择的模式),微软用普罗米修斯模型,以及图灵语言模型(Turing language models)作为补充。
普罗米修斯模型是技能和技术的集合体。而图灵模型不如GPT-4强大,旨在识别和回答简单的问题,并将更难的问题传递给GPT-4。
微软内部,已经将其手头的2000块GPU中的大部分,都投入到了「小模型」的训练当中。当然,这与微软提供给OpenAI的芯片数量相比,只能说是小巫见大巫了。
不过,这些模型可以执行比GPT-4更简单的任务,也是微软为破冰所作的努力。
打破OpenAI束缚
多年来,微软与OpenAI这两家公司,保持着千丝万缕的联系。
但是,随着ChatGPT,微软必应等全家桶竞相推出,微软与OpenAI也开始秘密开展市场角逐战。
尽管微软的努力仍处于早期阶段,但纳德拉正带领微软,为自家AI产品开辟一条不完全依赖OpenAI的路。
「这终究还是要发生的」,Databricks的高管Naveen Rao在谈到微软内部的AI工作时说。
「微软是一家精明的企业,当你部署产品使用GPT-4巨型模型时,他们要的是高效。这就好比说,我们并不需要一个拥有3个博士学位的人,来当电话接线员,这在经济上是行不通的。」
然而,纳德拉和研究主管Peter Lee希望在没有OpenAI的情况下,开发出复杂的AI,这大概只是一厢情愿。
自从微软投资OpenAI后,这家巨头的研究部门把大部分时间,都用来调整OpenAI的模型,以便使其适用微软的产品,而不是开发自己的模型。
微软的研究团队,也并没有幻想自己能开发出像GPT-4这样强大的AI。

他们清楚地知道,自身没有OpenAI的计算资源,也没有大量的人类审查员来反馈LLM回答的问题,以便工程师改进模型。
过去一年里,随着几波研究人员的离职,包括一些转入微软内部的产品团队,研究部门的人才也在不断流失。
对微软自身来说,在没有OpenAI帮助的情况下,开发高质量的LLM,可以在未来几年,两家公司讨论续签合作关系时赢得更多谈判筹码。
目前,两者交易对双方都有利。
微软投资OpenAI一百多亿美元,作为回报,能够在微软产品中永久使用OpenAI 现有知识产权的独家权利。
此外,微软还将获得OpenAI75%的理论运营收益,直到其初始投资偿还为止,并且将获得利润的49%,直到达到一定上限为止。
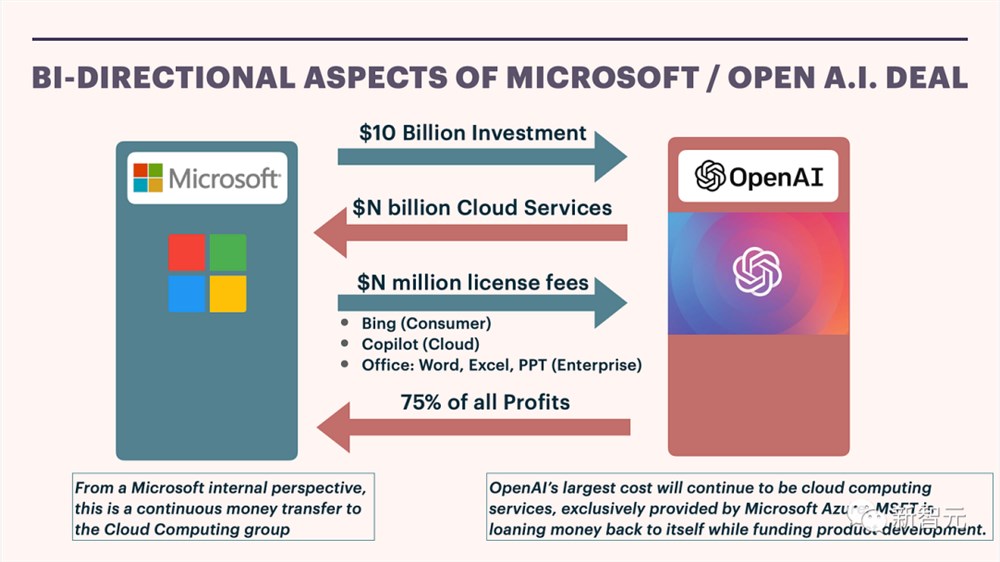
现在,微软希望通过与OpenAI,以及其他AI企业的现有联盟,在一个不确定的时期内增加至少100亿美元的新收入。
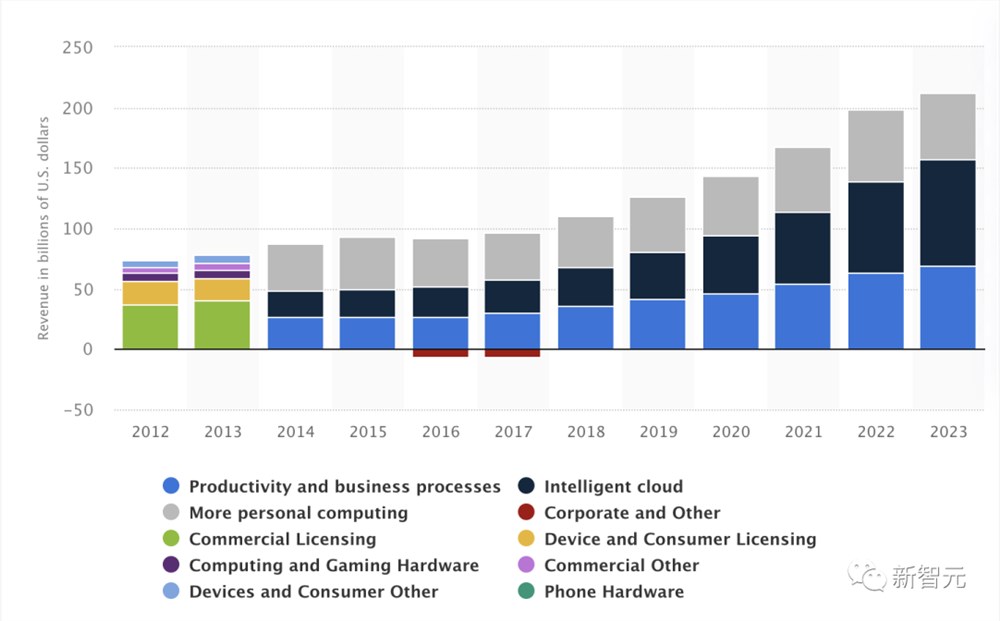
Office365全家桶在得到GPT-4能力加持,已经出现了早期的收入增长迹象。
微软还在7月份表示,已有超过2.7万家公司为代码编写工具GitHub Copilot付费了。
Statista统计,2023年除了微软云服务比例最大,加速生产力商业流程的软件产品收入占比也在逐渐增加。
然鹅,讽刺的是,微软与OpenAI的交易条款,也间接地帮助微软努力摆脱对OpenAI的依赖。
当用户使用必应时,微软可以访问OpenAI模型输出的结果。
目前,微软正在利用这些数据,创建更加「精炼」的模型。内部研究人员的研究结果表明,这些模型可以用更少的计算资源产生类似的结果。
「小模型」的探索
在OpenAI的阴影下度过一年后,微软的一些研究人员找到了全新的目标——制造一个模仿GPT-4的「蒸馏」模型。
今年6月,微软训练了一个算力消耗只有GPT-4十分之一的模型——Orca。
为了创建这个Orca,微软将GPT-4生成的数百万个答案输入到了一个更为基本的开源模型之中,并以此教它模仿GPT-4。

论文地址:https://arxiv.org/abs/2306.02707
结果显示,Orca不仅超过了其他的SOTA指令微调模型,而且在BigBench Hard(BBH)等复杂的零样本推理基准中,实现了比Vicuna-13B翻倍的性能表现。
此外,Orca在BBH基准上还实现了与ChatGPT持平的性能,在SAT、LSAT、GRE和GMAT等专业和学术考试中只有4%的性能差距,并且都是在没有思维链的零样本设置下测量的。
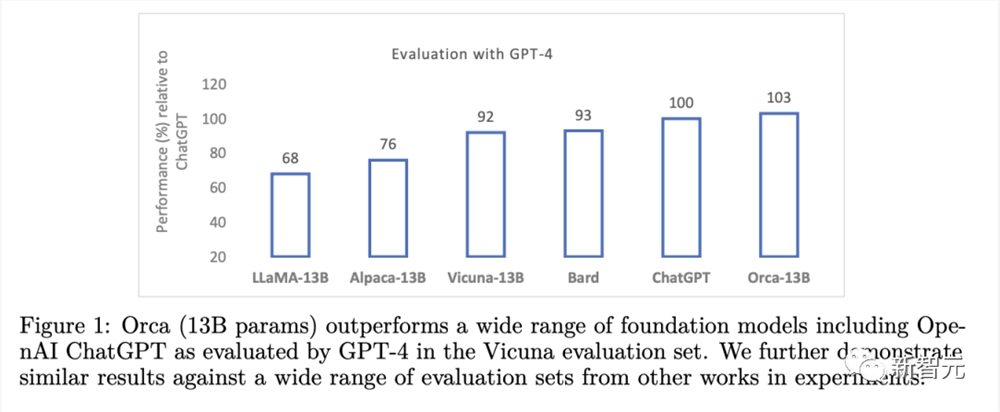
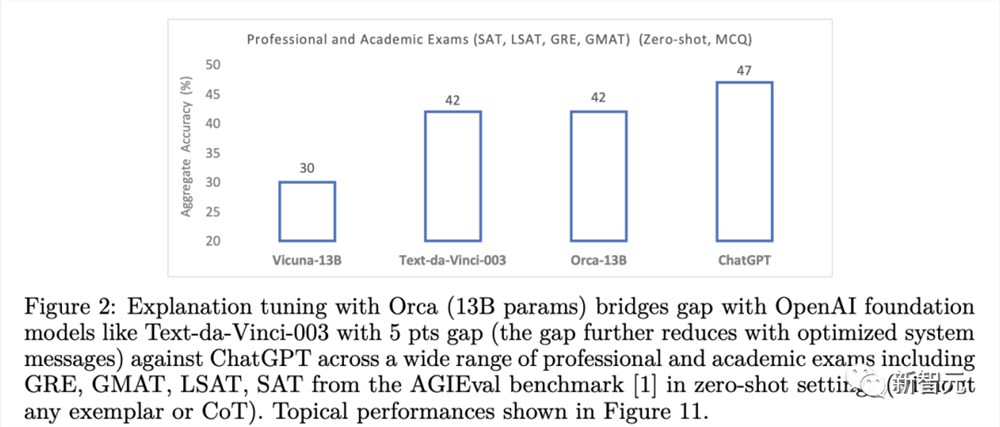
甚至,在某些情况下,Orca的表现与OpenAI的免费版ChatGPT不相上下。
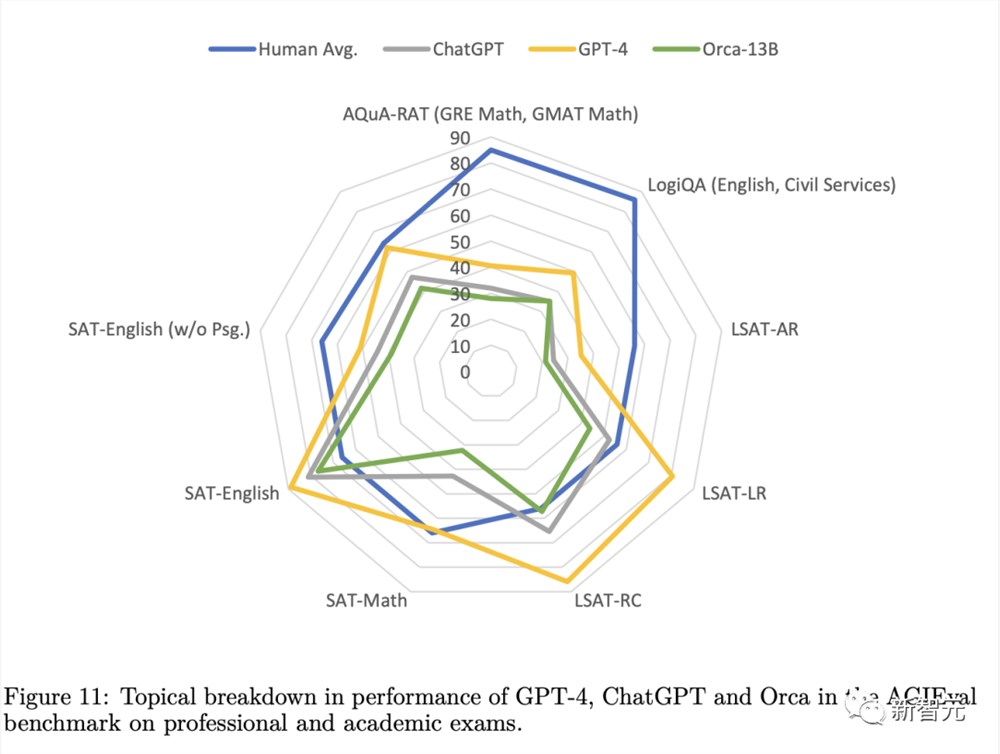
类似的,微软还公布了一款参数量不到GPT-4千分之一的模型——phi-1。
由于采用了「教科书级」的高质量训练数据,phi-1在数学和逻辑问题上的熟练程度,完全不亚于5倍于它的开源模型。

论文地址:https://arxiv.org/abs/2306.11644
随后,微软在研究「一个LLM有多小,才能达到一定的能力」上更进了一步,推出了只有13亿参数的模型phi-1.5。

论文地址:https://arxiv.org/abs/2309.05463
phi-1.5展现出了许多大模型具备的能力,能够进行「一步一步地思考」,或者进行一些基本上下文学习。

结果显示,phi-1.5在常识推理和语言技能上的表现,与规模10倍于它的模型旗鼓相当。
同时,在多步推理上,还远远超过了其他大模型。

虽然目前还不清楚,像Orca和Phi这样的「小模型」是否真的能与更大的SOTA模型(如GPT-4)相媲美。但它们巨大的成本优势,加强了微软继续推动相关研究的动力。
据一位知情人士透露,团队在发布Phi之后,首要任务就是验证此类模型的质量。
在即将要发表的论文中,研究人员又提出了一种基于对比学习的方法,让工程师们可以教模型区分高质量和低质量的响应,从而改进Orca。
同时,微软其他的团队也正在紧锣密鼓地开发全新的多模态大模型,也就是一种既能解释又能生成文本和图像的LLM。
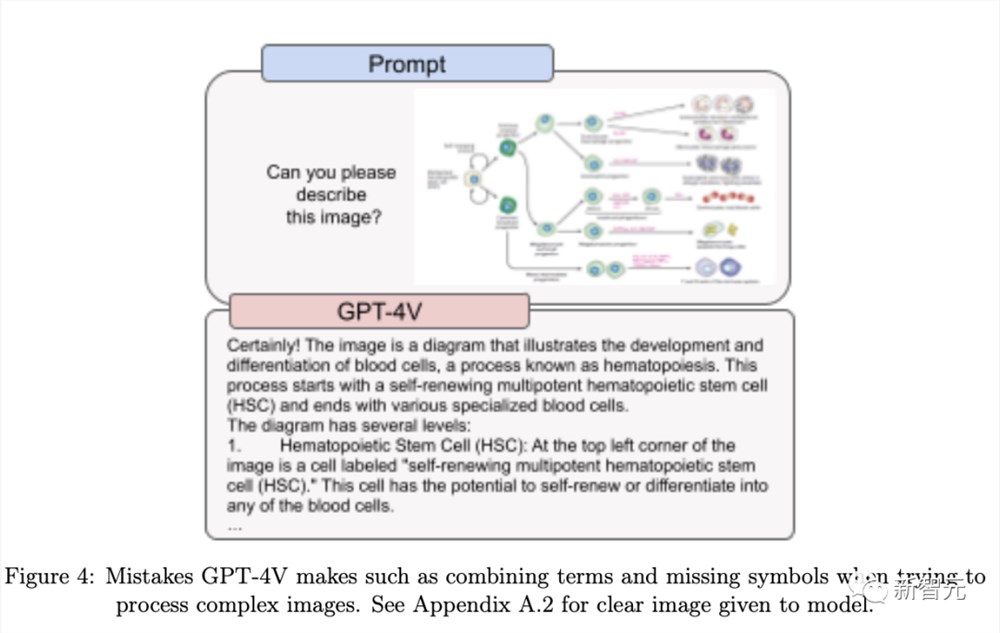
GPT-4V
显然,像Orca和Phi这样的模型,可以帮助微软降低为客户提供AI功能时所需的计算成本。
据一位在职员工透露,微软的产品经理已经在测试如何使用Orca和Phi而不是OpenAI的模型,来处理必应聊天机器人的查询了。比如,总结小段文本、回答是或者否,这种相对简单的问题。
此外,微软还在权衡是否向Azure云客户提供Orca模型。
据知情人士透露,Orca论文一经发表,就有客户来询问何时能用上了。
但问题在于,如果真要这样操作的话,微软是不是还需要找Meta拿个许可。毕竟后者对哪些公司可以将其开源LLM进行商业化,还是有所限制的。
参考资料:
https://www.theinformation.com/articles/how-microsoft-is-trying-to-lessen-its-addiction-to-openai-as-ai-costs-soar?rc=epv9gi
https://the-decoder.com/microsoft-seeks-plan-b-for-more-cost-effective-ai-sidestepping-openais-gpt-4/
德国反垄断负责人:人工智能可能会增强大型科技公司的主导地位
站长之家(ChinaZ.com)10月10日消息:德国卡特尔办公室主席AndreasMundt警告称,人工智能可能会增强大型科技公司的市场实力,监管机构应警惕任何反竞争行为。Mundt的评论强调了监管机构对科技巨头的担忧,这些公司拥有大量用户数据,可能在智能家居、网络搜索、在线广告、汽车和许多其他产品和服务中使用的新技术中获得竞争优势。站长网2023-10-10 16:08:370000LangSplat:一种基于3D高斯技术提高3D语言查询交互任务效率
划重点:1.LangSplat是一种基于传统3D高斯技术的人工智能方法,用于在3D环境中进行开放式语言查询,以解决当前方法在处理速度和准确性方面的限制。2.该方法使用了独特的3D语言领域构建和语言嵌入技术,通过场景级语言自动编码器减少内存使用,并通过SegmentAnythingModel(SAM)解决复杂场景中的点模糊问题。站长网2024-01-18 11:25:450000vivo X100 Ultra今日开售 首销1小时累计销售额破5亿
中关村在线消息:5月28日,vivoX100Ultra正式开售,起售价12GB256GB版本6499元。vivo官方表示,该机开售1小时累计销售金额破5亿,感谢所有用户对产品的认可和支持。站长网2024-05-28 17:28:200000用AI整顿职场,这次打工人终于不骂钉钉了
从ChatGPT到Midjourney,从OpenAI到Office的Copilot,最近这小半年,不论是做图、写文章,甚至是做PPT、写邮件,只要是和人力创作有关的领域,我们都能够发现AIGC的浪潮汹涌,几乎每周乃至每天,AIGC领域都有新的成果。站长网2023-04-19 09:04:510001Vercel发布界面生成器v0.dev 简单文本描述即可快速生成界面
Vercel最新发布了v0版本的界面生成器,现在你可以通过自然语言描述生成界面代码,随后直接在预览中查看和调整生成的代码。完成后,你可以将代码复制下来,或者将应用部署在Vercel上。地址:https://v0.dev/站长网2023-09-15 11:51:340000