手机就能运行,1万亿训练数据!StableLM-3B-4E1T来啦
美东时间10月2日,著名开源平台Stability.ai在官网宣布,推出开源大语言模型StableLM-3B-4E1T。(开源地址:https://huggingface.co/stabilityai/stablelm-3b-4e1t)
据悉,Stable LM3B是一款主要面向手机、笔记本等移动设备的基础大语言模型,在保证性能的前提下,极大降低了算力资源的要求。
Stable LM3B支持生成文本/代码、总结摘要、数据微调、常识推理、解答数学题等功能,全局上下文长度为4096。(简称“Stable LM3B”)

随着ChatGPT的火爆出圈,全球掀起了轰轰烈烈的“大模型开发热潮”。但多数模型皆需要耗费大量算力资源才能预训练、微调,同时对开发的生成式AI应用的运行环境也有很高的要求。高通更是发布了专门针对移动端的生成式AI芯片,以解决算力问题。
Stability.ai希望通过开源Stable LM3B,帮助那些没有庞大算力资源的开发者,也能打造小巧精悍的生成式AI产品,可以安全、稳定地在移动端运行。
Stable LM3B训练数据集
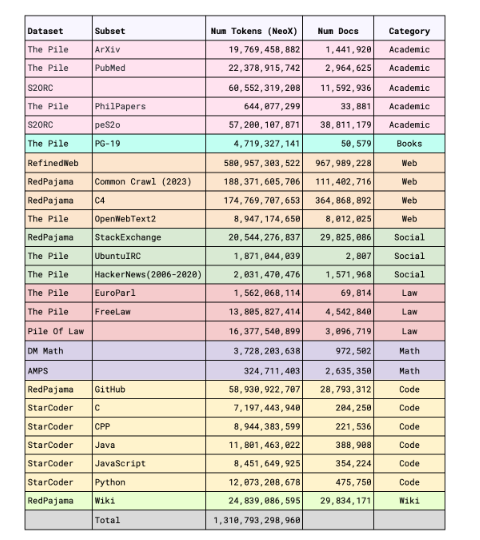
虽然该模型只有30亿参数,却使用了一个包含文本、代码、维基百科、ArXiv、图书、C4等多种数据的1万亿tokens庞大的训练数据集。
该数据集由多个开源的大规模数据集经过筛选混合而成,包括Falcon RefinedWeb、RedPajama-Data、The Pile以及 StarCoder等。
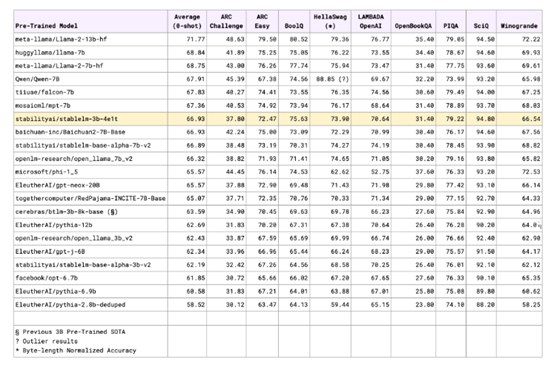
这使得Stable LM3B以更少的资源,性能却超越同等规模模型,甚至比一些70亿、100亿参数的大模型更强。
Stable LM3B训练流程
Stable LM3B以bfloat16精度训练972k起步,全局上下文长度为4096,而不是像 StableLM-Alpha v2那样从2048到4096进行多阶段提升。
Stability.ai使用了AdamW进行性能优化,并在前4800步使用线性预热,然后采用余弦衰减计划将学习率降至峰值的4%。
早期的不稳定性归因于在高学习率区域的长期停留。由于模型相对较小,没有采用dropout。
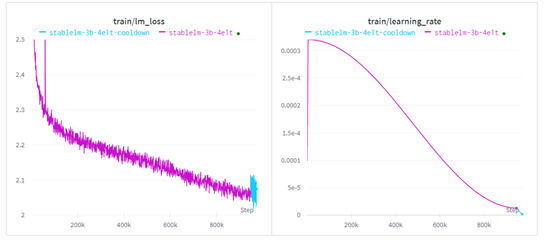
在训练过程中,Stability.ai评估自然语言基准,并在学习率衰减计划的尾声阶段,观察到训练带来的稳步提升。基于这个原因,开发人员决定将学习率线性降低至0,类似于Zhai等人的做法,以期获得更好的性能。
此外,在预训练的初始阶段依赖于 flash-attention API及其开箱即用的三角因果屏蔽支持。这迫使模型以类似的方式处理打包序列中的不同文档。
在冷却阶段,Stability.ai在并发实验中凭经验观察到样本质量提高(即:减少重复)后,为所有打包序列重置 EOD 标记处的位置ID和注意掩码。

硬件方面,StableLM-3B是在Stability AI的算力集群上训练的。该集群包含256个NVIDIA A10040GB显卡。训练开始于2023年8月23日,大约消耗了30天完成。
性能测试方面,StableLM-3B在零样本的lm-evaluation-harness评估框架中,进行了性能测试。结果显示,性能完全不输70亿参数的模型,甚至比一些100亿参数的更强。
学而思计划年内推出数学大模型MathGPT
今日,有消息称,学而思正在研发自主研制的数学大模型MathGPT,该模型以数学解题和讲题算法为核心,面向全球数学爱好者和科研机构。目前,该项目已经获得阶段性成果,并计划在今年推出基于该模型的产品级应用。站长网2023-05-05 17:25:470000I2VEdit:修改单帧即可编辑整个视频 搞定虚拟试妆、风格转换
划重点:⭐️利用预训练的图像到视频模型,编辑单帧就能扩散到整个视频⭐️包括粗略运动提取和外观细化两个关键过程⭐️保持外观和运动与原始视频的一致性,减少质量损失的跳跃间隔策略近年来,扩散模型在图像和视频编辑方面的出色生成能力引发了广泛研究。与图像编辑相比,视频编辑在时间维度上面临额外挑战,而图像编辑已经见证了更多种类、高质量方法以及像Photoshop这样更强大的软件的发展。站长网2024-05-29 19:10:240000调查显示:25%全球CEO预计生成式AI将导致2024年至少裁员5%
**划重点:**1.🌐25%的全球首席执行官预计生成式人工智能的部署将在今年至少导致5%的裁员。2.🏦媒体、银行、保险和物流行业最有可能因先进的AI工具而预测到裁员。3.💼调查显示,46%的首席执行官预计未来12个月内使用生成式AI将提高盈利能力,但47%表示该技术将带来较小或无变化。站长网2024-01-17 14:22:480000绝美AI婚纱照抖音爆火 网友:我终于“嫁”给了自己
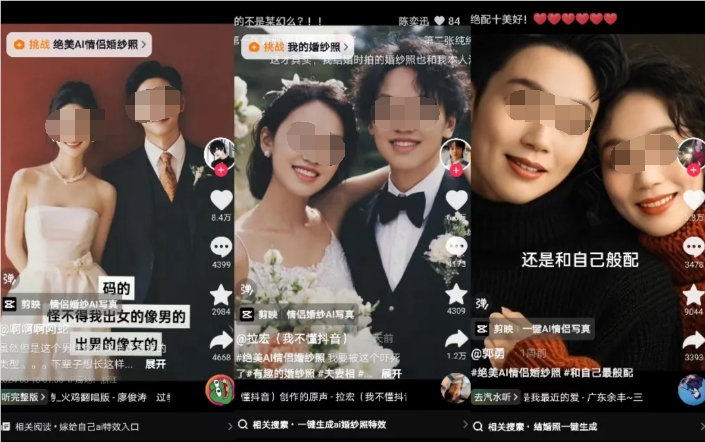
随着AI技术的不断发展,AI证件照、家庭合照等写真产品在市场上持续流行。最近,许多抖音用户晒出了AI婚纱照,有趣的是,这些婚纱照中的两张脸都是自己的,实现了“自己嫁自己”的奇妙效果。据了解,这样的婚纱照是通过剪映的“情侣婚纱AI写真”模板制作的。用户只需上传一张照片,即可生成一张与自己结婚的婚纱照。据页面显示,目前已有1610.5万人使用过这个功能。站长网2024-03-26 19:01:160000德国反垄断负责人:人工智能可能会增强大型科技公司的主导地位
站长之家(ChinaZ.com)10月10日消息:德国卡特尔办公室主席AndreasMundt警告称,人工智能可能会增强大型科技公司的市场实力,监管机构应警惕任何反竞争行为。Mundt的评论强调了监管机构对科技巨头的担忧,这些公司拥有大量用户数据,可能在智能家居、网络搜索、在线广告、汽车和许多其他产品和服务中使用的新技术中获得竞争优势。站长网2023-10-10 16:08:370000