Google DeepMind提出DRaFT算法以高效优化扩散模型
要点:
1、Google DeepMind提出了直接奖励微调(DRaFT)的概念,可以高效微调扩散模型以最大化可微的奖励函数。
2、引入DRaFT-K和DRaFT-LV算法,限制反向传播步数,提高效率。实验证明优于全反向传播。
3、在Stable Diffusion1.4上应用DRaFT,结果显示其效率远超基于强化学习的微调基线。DRaFT-LV效率最高。
扩散模型已经革新了各类数据的生成建模。但是在实际应用中,如根据文本描述生成美观图像,仍需要微调模型。目前文本到图像的扩散模型采用无分类器指导和精心设计的数据集如LAION美学数据集来提升图像质量和模型对齐性能。

论文地址:https://arxiv.org/abs/2309.17400
在研究中,Google DeepMind提出了一种直接而高效的基于梯度的奖励微调方法,其核心是将扩散采样过程微分化。他们提出了直接奖励微调(DRaFT)的概念,其本质是反向传播整个采样链,通常表示为具有50步长度的展开计算图。为有效管理内存和计算成本,他们采用梯度检查点技术,优化LoRA权重而不是修改全部模型参数。
此外,Google DeepMind还提出了DRaFT方法的改进,以提升其效率和性能。首先是DRaFT-K,其限制采样时仅反向传播最后K步时的梯度计算。实验结果显示,与全反向传播相比,这种截断梯度方法的性能明显更好,因为全反向传播会导致梯度爆炸问题。
另外,研究人员提出了DRaFT-LV,其平均多个噪声样本来计算更低方差的梯度估计,进一步提高方法效率。
研究人员在Stable Diffusion1.4上应用DRaFT,使用各种奖励函数和提示进行评估。他们的梯度方法相比基于强化学习的微调基线,效率优势明显。例如,在最大化LAION美学分类器分数时,与强化学习算法相比取得了200倍的加速。
他们提出的变体DRaFT-LV展现出卓越的效率,学习速度约为先前梯度微调方法ReFL的两倍。此外,他们证明了DRaFT可以与预训练模型组合或插值,通过混合或缩放LoRA权重来实现。
总之,直接在可微奖励上微调扩散模型是一个提升生成建模技术的有前景的方向。其效率、通用性和有效性使其成为机器学习和生成建模领域研究者和从业者的有价值工具。
专家:AI聊天模型消耗的水量惊人 ChatGPT回答25个问题消耗近半升水
据外媒报道,一位专家表示,人工智能聊天模型每回答25个问题就消耗近半升水,关于人工智能对环境的影响仍在探索中。OndokuzMayıs大学环境工程系的教员YükselArdalı教授博士对AI聊天模型的使用提出了一些见解,尤其是在过去的几个月中,人工智能聊天模型的使用量有所增加,以及它们的耗水量如何影响环境。站长网2023-07-20 16:56:010001财报解读:新鲜感褪去后,微软直面AI的骨感现实?
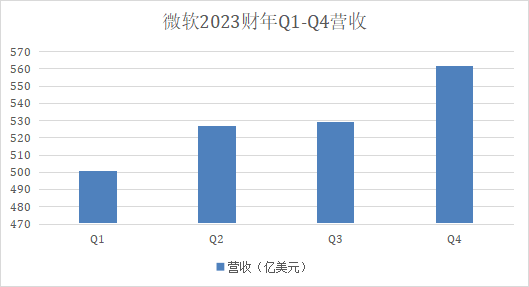
微软交出了一份远观尚可,但近看承压的“答卷”。北京时间2023年7月26日,微软披露了2023财年第四财季及全年财报。受生产力和业务流程部门和智能云部门等业务带动,微软第四财季营收561.89亿美元,同比增长8%;净利润200.81亿美元,同比增长20%;每股摊薄收益2.69美元,同比增长21%。站长网2023-07-29 09:49:400000英国政府推出超过 1 亿英镑的计划来启动“负责任的”人工智能研发
**划重点:**-🇬🇧**AI监管回应:**英国政府对AI监管咨询作出回应,强调依赖现行法律和监管机构,并提供针对AI监管和创新的逾1亿英镑资金。-💼**全球引领提振:**科学、创新与技术部(DSIT)将该计划打造成对英国在AI领域“全球引领”的提振,其中包括逾1亿英镑的资金。站长网2024-02-06 09:58:430000宝可梦公司调查幻兽帕鲁 回应幻兽帕鲁爆火:未授权相关元素
站长之家(ChinaZ.com)1月25日消息:宝可梦公司近日发布声明,针对一款名为《幻兽帕鲁》的游戏展开调查。声明称,公司收到了大量客户咨询,反映这款游戏与《宝可梦》在内容上存在高度相似性,并要求确认该游戏是否获得了宝可梦公司的授权。宝可梦公司明确表示,他们并未授权《幻兽帕鲁》使用任何与《宝可梦》相关的元素。公司强调,将对任何侵犯《宝可梦》知识产权的行为展开调查,并采取适当的法律行动。站长网2024-01-25 14:25:540000开启新一轮红利期,TikTok Shop美区单场直播破百万美金
近日,在一场TikTokShop平台美国直播中,美容品牌主播StormiSteele达成了销售额突破100万美金的成绩,也刷新了美国单场直播纪录。有媒体评价Stormi成为美国第一位在单场TikTokShop直播中收获百万美元的达人,这开创了一种前所未有的创业道路,集娱乐、发现和购物为一体,为美国直播购物树立了新标杆。美国小镇女孩的创业故事站长网2024-06-17 18:24:040000