谷歌、CMU研究表明:语言模型通过使用良好的视觉tokenizer首次击败了扩散模型
站长网2023-10-11 17:56:520阅
要点:
1. 研究表明,在图像和视频生成领域,语言模型通过使用良好的视觉 tokenizer 首次击败了扩散模型,强调了 tokenizer 的重要性。
2. 传统大型语言模型(LLM)在图像生成方面一直落后于扩散模型,主要原因是缺乏有效的视觉表示。
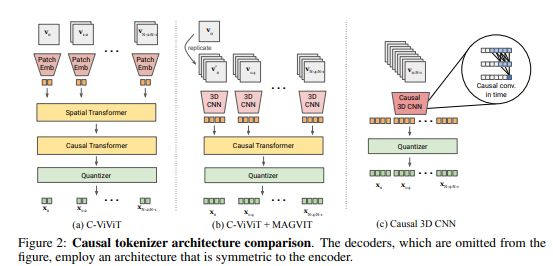
3. 新研究引入了名为MAGVIT-v2的视频 tokenizer,采用无查找量化和增强功能的设计,取得了在图像和视频生成、视频压缩以及动作识别领域的显著性能提升。
来自谷歌、CMU 的研究发现,语言模型在图像、视频生成领域的性能一直不如扩散模型,主要原因是缺乏有效的视觉表示。
然而,通过引入一种名为MAGVIT-v2的视频 tokenizer,采用无查找量化和增强功能的设计,研究者成功改进了图像和视频生成的质量,超越了现有技术。
论文地址:https://arxiv.org/pdf/2310.05737.pdf
实验证实,良好的视觉 tokenizer 在使语言模型生成高质量图像和视频方面具有关键作用。
这一研究的重要性在于它为语言模型的多模态应用提供了新的思路,通过将视觉和语言统一在相同的 token 空间中,可以提高多模态语言模型的性能,加快视频应用的处理速度,并提高视频压缩质量。
此外,新的 token 也提供了更好的视觉理解,增强了模型的鲁棒性和泛化性。通过这一研究,我们可以看到语言模型在视觉生成领域的潜力,以及如何通过创新的设计和改进来实现更好的性能。
0000
评论列表
共(0)条相关推荐
软银计划于2025年推出自家AI芯片,投资640亿美元
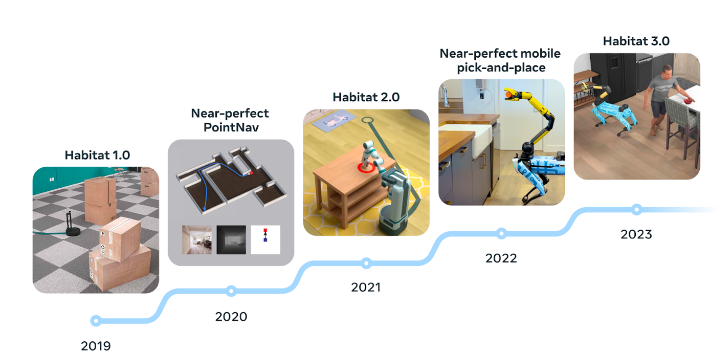
划重点:🔍软银计划于2025年推出自家AI芯片,将投资640亿美元(10万亿日元)用于AI芯片、机器人、数据中心等领域。🔍Arm,软银的子公司,将建立自己的AI芯片部门,并计划于2025年春季推出原型,秋季开始由约制造商进行大规模生产。🔍软银计划建设数据中心和可再生能源厂,并通过收购来打自己的AI集团。站长网2024-05-13 09:58:110000Meta推出AI模拟环境Habitat 3.0 为机器人训练提供更真实的场景
要点:1.MetaPlatformsInc.的研究团队发布了AI模拟环境Habitat的进阶版本Habitat3.0,用于教授机器人如何与物理世界互动。2.发布了HabitatSyntheticScenesDataset,这是由艺术家制作的3D数据集,可用于训练AI导航代理,以及HomeRobot,一个用于模拟和现实世界环境的廉价机器人助手硬件和软件平台。站长网2023-10-26 11:51:580001视频修复项目ProPainter发布Comfyui节点 可从视频中删除指定内容
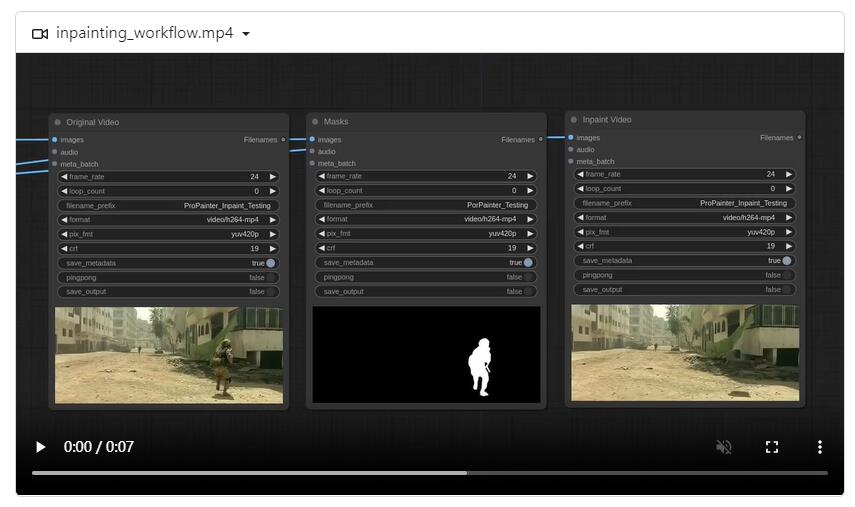
ComfyUI_ProPainter_Nodes项目是一个专门针对视频修复的解决方案,它基于ProPainter框架并实现了ComfyUI界面。以下是该项目的主要特点和功能:基于ProPainter框架:该项目利用ProPainter框架的基于流的传播和时空转换器技术,提供了高级视频帧编辑和无缝的视频修复任务。站长网2024-05-27 19:47:130000FF:美国著名说唱歌手Chris Brown成为第五位FF19车主
据法拉第未来官方消息,全球巨星兼企业家克里斯布朗在过去一个月里,经过试驾和体验FF912.0FuturistAlliance后,正式成为了这款车的第五位车主。现在,克里斯布朗已身兼FF车主及开发者共创官两重身份,他已向FF提供了宝贵的反馈意见,这些意见不仅会进一步完善属于他的FF912.0,也会对提升FF的整体用户体验起到推动作用。站长网2023-11-06 16:00:250000AI搜索大变局
AI浪潮愈演愈烈的当下,信息量与应用需求迎来彻底爆发,外加参战厂商们急需寻找大模型落地场景,2024年无疑会成为AI应用场域争夺的“修罗场”。贯览整个战局,仍不断发生着变化,新生力量不断跻身竞技场,传统巨头们也在试图演绎新的打法。而其中,AI搜索似乎成为了大模型时代的兵家必争之地。站长网2024-02-22 14:24:310000