AudioSep:可以从音频剪辑中仅分离出特定的声音
站长网2023-10-27 10:48:250阅
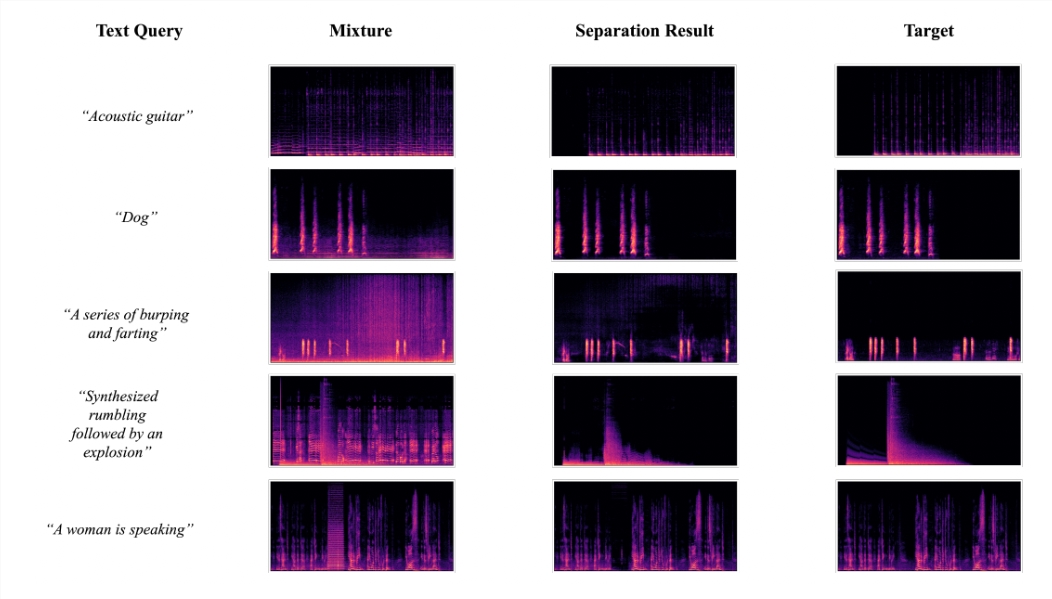
AudioSep 是一种 AI 模型,可以使用自然语言查询进行声音分离。这一创新性的模型由Audio-AGI开发,使用户能够通过简单的语言描述来分离各种声音源。
通过使用AudioSep这一人工智能模型,我们可以从音频剪辑中精准地分离出特定的声音。举个例子,假设你在一个拥挤嘈杂的咖啡馆录制了一段音频,现在你可以从中剥离出对应的人声。这项技术支持本地部署,并且还提供了一个直观的用户界面,使操作更加简便。
项目地址:https://github.com/Audio-AGI/AudioSep
主要功能:
训练和微调: AudioSep提供了训练和微调模型以适应特定音频-文本配对数据集的工具。无论您在音频事件分离还是语音增强领域工作,此功能都使您能够为自己的独特需求定制模型。
推断: 利用AudioSep通过提供文本描述来进行音频分离。该模型以32kHz采样率处理音频,确保高质量的结果。您还可以直接从Hugging Face加载模型以方便使用。
内存效率: AudioSep提供基于块的推断,这是一种节省内存的选项,可以让您处理大型音频文件,而无需担心资源限制。
评估基准: 使用内置的基准工具来评估分离音频的性能。下载各种类别的评估数据,包括audioset、audiocaps、vggsound、music、clotho和esc50,并获得详细的结果。
引用: 如果您发现AudioSep有用,请考虑引用其背后的研究。承认开发者和研究人员为使这个工具可用所付出的辛勤工作是至关重要的。
AudioSep具有强大的分离性能和出色的零射击泛化能力,AudioSep为音频事件分离、乐器分离和语音增强等任务提供了广泛的应用。
0000
 正在请求数据,请稍候!
正在请求数据,请稍候!相关推荐
孟羽童回应被董明珠怒斥:准备去国外读研 不太方便回应
孟羽童在接受采访时表示正在备考,对于一些事情暂时不便回应。据孟羽童此前发布的内容显示,她正在申请去外国读研究生。今年5月,孟羽童从格力离职,引起了广泛关注。董明珠在格力电器2023届大学生入职仪式中再次提及孟羽童。董明珠表示,当时在实习生节目中看中孟羽童勤奋,选来做秘书,但在工作中不尽人意,只想着用格力平台当网红,在公司中产生了不好的影响,所以将她开除出去。站长网2023-12-15 16:06:590001董宇辉新账号与辉同行上线 此前个人工作室已成立
董宇辉新账号“与辉同行”正式上线,并获平台认证,认证信息为“与辉同行(北京)科技有限公司”。账号介绍为:这是真的,与辉同行。目前该账号仅发布了一条图文内容。此前,与辉同行(北京)科技有限公司成立,法定代表人董宇辉。注册资本1000万元,经营范围包含鲜肉零售、网络文化经营、演出经纪等。该公司注册地址与东方甄选关联公司东方优选(北京)科技有限公司为同一栋楼。站长网2023-12-26 20:09:330000OpenAI CEO:构建巨型 AI 模型时代已经结束
近年来,OpenAI在处理语言方面取得了一系列令人印象深刻的进步,方法是将现有的机器学习算法扩大到以前无法想象的规模。不过,OpenAICEOSamAltman最近表示,构建巨型AI模型的时代已经结束,未来的进一步进展不会来自于更大的模型。Altman的声明表明,在开发和部署新AI算法的竞赛中出现了意想不到的转折。站长网2023-04-18 10:53:300000恋爱输入法,率先在国内找到AI应用商业化的答案?
“2024年国人最爱为哪些消费级AI应用花钱?答案可能是AI恋爱输入法”,点点数据显示头部产品的ARR已上探至千万人民币,甚至更高。「Love键盘」6月25号上线,月流水48万美元,累计营收180万美元,合1314万人民币;「蜜小语」6月13号上线,月流水52万美元,累计营收196万美元,合1431万人民币;00003000价位618手机推荐,华为魅族一加这三款必看,原因有哪些?
618预售活动还未正式开始,但估计有不少小伙伴都跟我一样已经蠢蠢欲动,准备好预算要给自己换部新手机了吧?好歹年中大促也是一次相当重磅的电商活动了,厂商们在安排福利这件事上也并不会含糊,受益的自然是咱消费者!站长网2023-05-24 03:30:410000