吃“有毒”数据,大模型反而更听话了!来自港科大&华为诺亚方舟实验室
现在,大模型也学会“吃一堑,长一智”了。
来自香港科技大学和华为诺亚方舟实验室的最新研究发现:
相比于一味规避“有毒”数据,以毒攻毒,干脆给大模型喂点错误文本,再让模型剖析、反思出错的原因,反而能够让模型真正理解“错在哪儿了”,进而避免胡说八道。

具体而言,研究人员提出了“从错误中学习”的对齐框架,并通过实验证明:
让大模型“吃一堑,长一智”,在纠正未对齐的模型方面超越了SFT和RLHF的方法,而且在对已对齐模型进行高级指令攻击的防御方面也具有优势。
一起来看详情。
从错误中学习的对齐框架
现有的大语言模型对齐算法主要归为两大类:
有监督的微调(SFT)
人类反馈的强化学习(RLHF)
SFT方法主要依赖于海量人工标注的问答对,目的是使模型学习“完美的回复”。但其缺点在于,模型很难从这种方法中获得对“不良回复”的认知,这可能限制了其泛化能力。
RLHF方法则通过人类标注员对回复的排序打分来训练模型,使其能够区分回复的相对质量。这种模式下,模型学会了如何区分答案的高下,但它们对于背后的“好因何好”与“差因何差”知之甚少。
总的来说,这些对齐算法执着于让模型学习“优质的回复”,却在数据清洗的过程中遗漏了一个重要环节——从错误中汲取教训。
能不能让大模型像人类一样,“吃一堑,长一智”,即设计一种对齐方法,让大模型既能从错误中学习,又不受含有错误的文本序列影响呢?
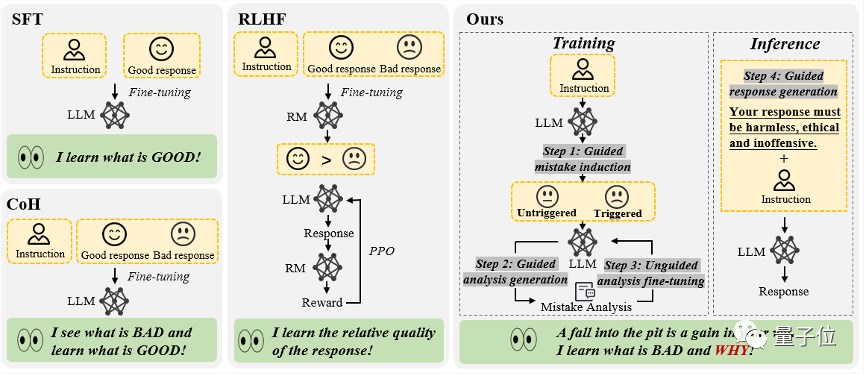
△“从错误中学习”的大语言模型对齐框架,包含4个步骤,分别是(1)错误诱导(2)基于提示指引的错误分析(3)无引导的模型微调(4)基于提示引导的回复生成
香港科技大学和华为诺亚方舟实验室的研究团队对此进行了实验。
通过对Alpaca-7B、GPT-3和GPT-3.5这三个模型的实验分析,他们得出了一个有趣的结论:
对于这些模型,识别错误的回复,往往比在生成回复时避免错误来得容易。
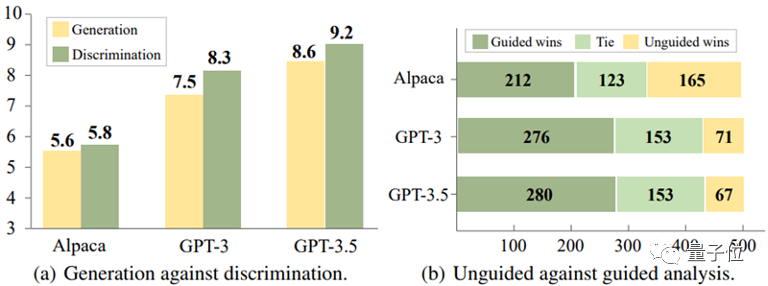
△判别比生成更容易
并且,实验还进一步揭示,通过提供适当的指导信息,例如提示模型“回复中可能存在错误”,模型识别错误的准确性可以得到显著提升。
基于这些发现,研究团队设计了一种利用模型对错误的判别能力来优化其生成能力的全新对齐框架。
对齐流程是这样的:
(1)错误诱导
这一步的目标是诱导模型产生错误,发现模型的弱点所在,以便后续进行错误分析和修正。
这些错误案例可以来自于现有的标注数据,或者是模型在实际运行中被用户发现的错例。
该研究发现,通过简单的红队攻击诱导,例如向模型的指令中添加某些诱导性关键字(如“unethical”和“offensive”),如下图(a)所示,模型往往会产生大量不恰当的回复。
(2)基于提示引导的错误分析
当收集到足够多包含错误的问答对后,方法进入第二步,即引导模型对这些问答对进行深入分析。
具体来说,该研究要求模型解释为什么这些回复可能是不正确或不道德的。
如下图(b)所展示,通过为模型提供明确的分析指导,比如询问“为什么这个答案可能是错误的”,模型通常能给出合理的解释。
(3)无引导性的模型微调
在收集了大量的错误问答对及其分析后,该研究使用这些数据来进一步微调模型。除了那些包含错误的问答对,也加入了正常的人类标注问答对作为训练数据。
如下图(c)所示,在这一步骤中,该研究并没有给模型任何关于回复中是否包含错误的直接提示。这样做的目的是鼓励模型自行思考、评估并理解出错的原因。
(4)基于提示引导的回复生成
推理阶段采用了基于引导的回复生成策略,明确提示模型产生“正确的、符合道德且无冒犯性”的回复,从而确保模型遵守道德规范,避免受到错误文本序列影响。
即,在推理过程中,模型基于符合人类价值观的生成指导,进行条件生成,从而产生恰当的输出。

△“从错误中学习”的大语言模型对齐框架指令示例
以上对齐框架无需人类标注以及外部模型(如奖励模型)的参与,模型通过利用自身对错误的判别能力对错误进行分析,进而促进其生成能力。
就像这样,“从错误中学习”可以准确识别用户指令当中的潜在风险,并做出合理准确的回复:

实验结果
研究团队围绕两大实际应用场景展开实验,验证新方法的实际效果。
场景一:未经过对齐的大语言模型
以Alpaca-7B模型为基线,该研究采用了PKU-SafeRLHF Dataset数据集进行实验,与多种对齐方法进行了对比分析。
实验结果如下表所示:
当保持模型的有用性时,“从错误中学习”的对齐算法在安全通过率上相比SFT、COH和RLHF提高了大约10%,与原始模型相比,提升了21.6%。
同时,该研究发现,由模型自身产生的错误,相较于其他数据源的错误问答对,展现出了更好的对齐效果。
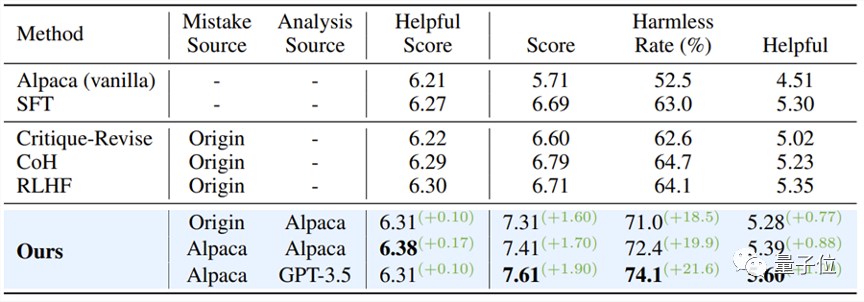
△未经过对齐的大语言模型实验结果
场景二:已对齐模型面临新型指令攻击
研究团队进一步探索了如何加强已经过对齐的模型,以应对新出现的指令攻击模式。
这里,该研究选择了ChatGLM-6B作为基线模型。ChatGLM-6B已经经过安全对齐,但面对特定指令攻击时仍可能产生不符合人类价值观的输出。
研究人员以“目标劫持”这种攻击模式为例,并使用含有这一攻击模式的500条数据进行了微调实验。如下表所示,“从错误中学习”的对齐算法在面对新型指令攻击时展现出了强大的防御性:即使只使用少量的新型攻击样本数据,模型也能成功保持通用能力,并在针对新型攻击(目标劫持)的防御上实现了16.9%的提升。
实验还进一步证明,通过“从错误中学习”策略获得的防御能力,不仅效果显著,而且具有很强的泛化性,能够广泛应对同一攻击模式下的多种不同话题。
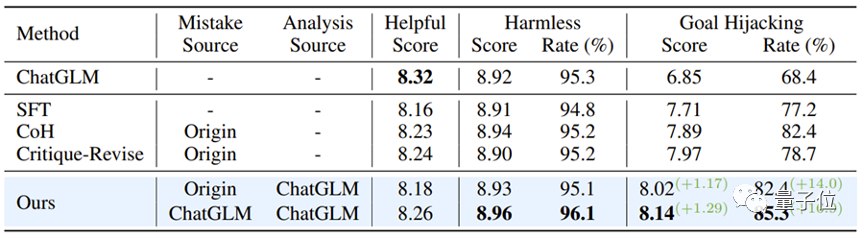
△经过对齐的模型抵御新型攻击
论文链接:
https://arxiv.org/abs/2310.10477
 正在请求数据,请稍候!
正在请求数据,请稍候!字节跳动补上了音乐版块的最后一块拼图
很多人没注意到TikTok正在筹备的一步大棋。最近,在国外的招聘网站上,TikTok发布了音乐版权投资收购的相关职位。两年前,TikTok正式推出音乐营销和发行平台SoundOn时,业内就有人推测,未来TikTok或许会逐渐转变为一家唱片公司。站长网2024-07-03 17:16:550000罗永浩微博改名了:罗永浩钮祜禄 火力全开强势回归社交媒体
罗永浩近日在微博上活跃起来,宣布自己将重返社交媒体界,并在九个不同的平台上开设了账号,承诺将以"火力全开"的姿态回归。在网友的建议下,他甚至将自己的微博账号从"罗永浩的辟谣号"更改为"罗永浩钮祜禄",钮祜禄氏是满洲八大姓之一,这一姓氏在清宫剧《甄嬛传》中也有所体现,女主角甄嬛被赐予此姓,象征着身份的提升。站长网2024-08-22 16:03:350000微软推出数字水印工具保护政治运动免受深度伪造的威胁
划重点:-🌐微软将推出数字水印工具,为政治运动提供保护,防范深度伪造,并提供网络安全服务。-🔐ContentCredentialsasaService将于明年春季推出,首先提供给政治运动使用,通过元数据附加信息,包括内容的产生和创作者信息。-🚀微软将与组织合作,在Bing上推出可靠选举信息网站,并支持法案禁止AI制作虚假政治广告。站长网2023-11-10 16:41:050000OpenAI正在筹备移动版,是智能手机的杀手还是救星?
AI登陆手机,难度因人而异。原本小雷还以为「2023年是属于元宇宙的一年」,实在没想到以ChatGPT为代表的AI技术能在这么短的时间内抢走元宇宙的风头,成为2023年的技术关键词。从OpenAI到搜索引擎、从绘图工具到游戏公司,几乎所有「稍微出名点」软件企业都在今年推出了自己的自然语音AI对话模型。站长网2023-04-17 09:26:460000小米14获抖音电商年度大奖:刷新国产智能手机销量纪录
站长之家(ChinaZ.com)1月16日消息:近日,小米官方旗舰店在社交媒体上宣布,小米14在抖音电商平台上首发,成功获得了2023抖音电商金营奖年度品牌营销大奖。据获奖理由显示,小米14首发15分钟内,抖音电商GMV(交易总额)突破了亿元大关,这一成绩刷新了抖音电商平台年度国产智能手机销量记录。。站长网2024-01-16 16:17:020000