CommonCanvas:一种使用创意共享图片训练开放扩散模型的方法
核心要点:
研究团队提出了一种使用创意共享图片训练开放扩散模型的方法,以克服高质量数据和版权问题的挑战。
他们使用迁移学习技术创建了合成标题,与精选的创意共享图片匹配,用于训练生成模型,将文字转化为图像。
这一方法大大提高了生成模型的质量,创建了称为CommonCanvas的一组模型,可与SD2相媲美。
近年来,人工智能在文本到图像生成领域取得了显著进展。将书面描述转化为视觉表现具有广泛的应用,从创作内容到帮助盲人和讲故事。然而,研究人员面临着两个重大障碍,即缺乏高质量数据和从互联网抓取的数据集涉及的版权问题。
为了克服这些问题,一支研究团队提出了一个创新的方法,他们创建了一个创意共享许可(CC)的图像数据集,用于训练开放扩散模型,这些模型可以胜过Stable Diffusion2(SD2)。

论文地址:https://arxiv.org/pdf/2310.16825.pdf
这个方法有两个主要挑战:首先,高分辨率的CC照片虽然是开放许可的,但它们经常缺乏文本描述,这对于文本到图像生成模型的训练至关重要。
其次,与像LAION这样的大型专有数据集相比,CC照片数量较少,尽管它们是重要的资源。这引发了是否有足够的数据可以有效训练高质量模型的问题。
为了解决这些问题,研究团队采用了迁移学习技术,使用预训练模型创建了出色的合成标题,并将其与精心选择的CC照片相匹配。这种方法利用了模型从照片或其他输入生成文本的能力,通过创建一个照片和虚构标题的数据集,用于训练生成模型,将文字转化为视觉内容。
此外,他们还制定了一种既节约计算资源又高效利用数据的训练方法,以解决第二个挑战。这意味着有足够的CC照片可供训练高质量模型。最终,研究团队培训了多个文本到图像生成模型,这些模型被称为CommonCanvas系列,并在生成质量上媲美SD2。
通过该方法,他们克服了数据集大小的限制和使用人工标题的问题,实现了高质量的图像生成。总之,他们的研究为创意共享图像的利用提供了新方法,为生成模型的进一步发展提供了有力支持。同时,他们还将训练好的CommonCanvas模型、CC照片、人工标题和CommonCatalog数据集免费提供在GitHub上,以鼓励更多的合作和研究。
读书郎将推出 AI 学习机或搭载梦想教育大模型
国内知名教育科技智能硬件品牌读书郎在其官方微博上发布了三张图片,并配以话题标签“读书郎梦想教育大模型”和“AI学习机”,此举可被视为读书郎公司即将开始研发自己的大模型的公开声明。站长网2023-09-13 09:18:490000独家:曾经APP Store下载第一的逗拍关停
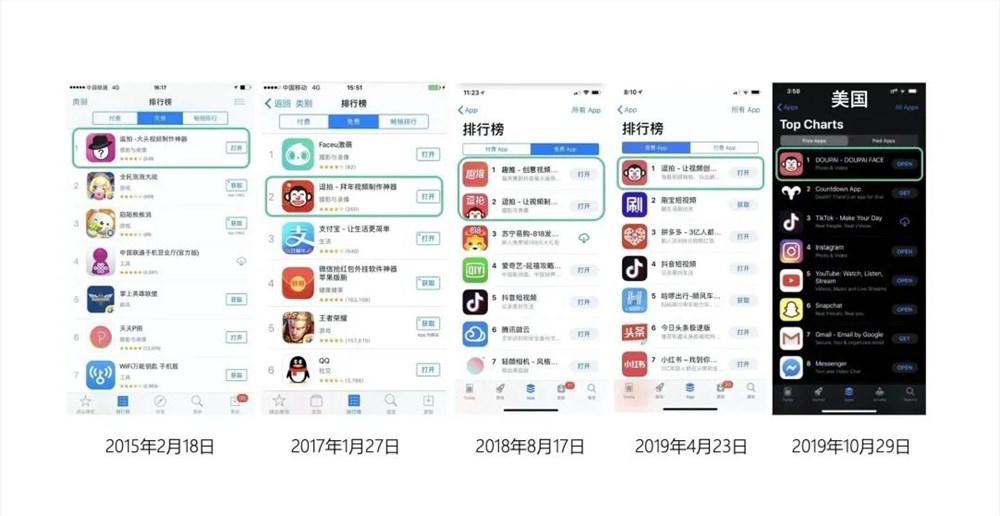
逗拍计划于今年6月30日停止运营。这个曾经流出一天的公告,很快就被删去,运营团队似乎仍有些不舍。不过,眼尖的业界仍然留意到了,由此引发讨论纷纷。要知道,这款APP曾数次冲上苹果appstore中国榜下载排行第一。当2013年推出之时,一度和美拍、秒拍、微视等产品争雄——这些产品都曾于斯时一领短视频浪潮数载。如今,短视频的高峰被抖音所统治,其下是追赶的视频号和快手。站长网2023-05-24 11:38:390000萨姆·奥特曼带火Airchat,硅谷对语音社交念念不忘
2021年春季,当时在硅谷科技圈处于绝对C位的马斯克,带火了一款语音社交应用Clubhouse,甚至一时间Clubhouse的邀请码呈现出“洛阳码贵”的景象,全球诸多用户更是为了参与硅谷最潮流的圈子选择一掷千金。然而三年时间过去后,随着特斯拉股价暴跌导致财富缩水,以及在X上的“倒行逆施”,马斯克让出了这个位置,如今硅谷的“新王”变成了人工智能巨头OpenAI的CEO萨姆·奥特曼。站长网2024-05-03 01:00:130000男子高铁吸烟狂言:不差钱随便罚 工作不顺心情郁闷
近日,一则关于男子在高铁上违规吸烟并嚣张叫嚣的新闻引发了广泛关注。据报道,本月26日,在从杭州东开往厦门的G1679次列车上,一名男子公然在车厢连接处吸烟,严重违反了高铁禁烟的规定。0000谷歌折叠屏手机Pixel 9 Pro Fold上架:新功能来了!
谷歌旗舰折叠屏手机Pixel{tag_keyurl_9}ProFold已经上市,除了带来丰富的软件新功能外,还新增了一项备受用户喜爱的折叠屏手机功能——应用配对。通过这个功能,用户可以将两个并排运行的应用程序保存为一个组合,以便快速访问。例如,在使用浏览器和微信时,可以将这两个应用程序组合保存为一个快捷方式放在主屏幕上。只需点击该快捷方式即可并排启动这两个应用程序。0000