GPU推理提速4倍!FlashDecoding++技术加速大模型推理
要点:
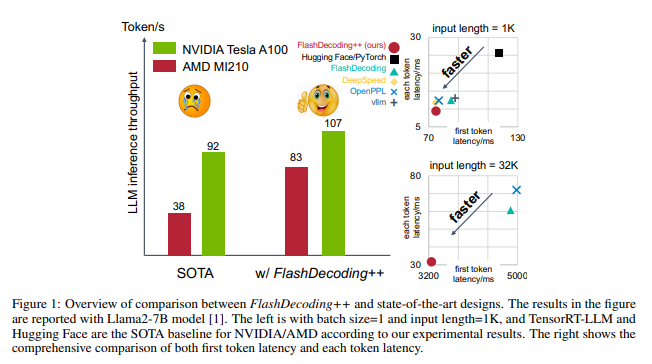
1. FlashDecoding 是一种用于加速大模型(LLM)推理任务的新方法,可以将GPU推理提速2-4倍,同时支持NVIDIA和AMD的GPU。
2. FlashDecoding 的核心思想包括异步方法实现注意力计算的真正并行以及优化"矮胖"矩阵乘计算,以降低LLM的推理成本并提高推理速度。
3. 无问芯穹是一家创立于2023年5月的公司,旨在打造大模型软硬件一体化解决方案,他们已经将FlashDecoding 集成到其大模型计算引擎"Infini-ACC"中,实现了256K上下文的处理能力。
推理大模型(LLM)是AI服务提供商面临的巨大经济挑战之一,因为运营这些模型的成本非常高。FlashDecoding 是一种新的技术,旨在解决这一问题,它通过提高LLM推理速度和降低成本,为使用大模型赚钱提供了新的可能性。
论文地址:https://arxiv.org/pdf/2311.01282.pdf
FlashDecoding 的核心思想包括异步方法实现注意力计算的真正并行以及优化"矮胖"矩阵乘计算。这些技术可以将GPU推理提速2-4倍,同时支持NVIDIA和AMD的GPU。这意味着LLM的推理任务将更加高效,可以在更短的时间内完成。
无问芯穹是FlashDecoding 的背后力量,他们是一家创立于2023年5月的公司,旨在打造大模型软硬件一体化解决方案。他们已经将FlashDecoding 集成到其大模型计算引擎"Infini-ACC"中,实现了256K上下文的处理能力,这是目前全球最长的文本长度。
FlashDecoding 的出现为使用大模型赚钱提供了更好的机会,因为它可以降低运营成本,提高效率,同时支持多种GPU后端。这对AI服务提供商和大模型创业公司都是一个重要的突破。
微软Copilot新增重磅功能!文本直接生成超逼真音乐
12月20日,微软在官网宣布与文生音乐领导者Suno合作,将其功能集成在copilot中,用户通过文本就能生成摇滚、流行、古典、朋克、民谣等多种类型音乐。Suno平台生成的音乐没有浓重的机器人味儿,效果比谷歌的Lyria、Meta的MusicGen更好,与真人演唱几乎一模一样。无论你是否懂乐器、能制作乐谱,现在只需要把你的想法,用文本输入到微软copilot中便能快速生成。站长网2023-12-20 09:15:340000阿里云免费开源数据库AI算法PilotScope
站长之家(ChinaZ.com)12月20日消息:现有的数据库系统非常复杂,要求非常稳定,即使将单一的AI算法与数据库进行匹配调试,也需要工程师们数周甚至数月的紧密配合,效率低下,效果不佳,导致业界迟迟无法将AI算法应用到数据库中。站长网2023-12-20 15:29:250000卢伟冰:小米不会像Open AI一样做通用大模型
在昨日的财报电话会议上,针对组建AI实验室大模型团队一事,小米总裁卢伟冰表示,会积极拥抱大模型,但不会像OpenAI一样做通用大模型,而是会深度和业务结合协同,利用AI技术提升内部效率。同时,针对造车相关问题,卢伟冰称,小米造车业务会按照原计划进行,在时间进度上将符合或略超预期。站长网2023-05-25 08:39:370000马斯克旗下 AI 初创公司 xAI 计划融资10亿美元
据报道,马斯克旗下xAI正寻求从股权投资者处筹集10亿美元资金。根据周二提交给美国证券交易委员会(SecuritiesandExchangeCommission)的一份文件,该公司已筹集了大约1.35亿美元。埃隆·马斯克(ElonMusk)在去年11月的一份声明中指出,X(之前称为Twitter)的股权股东将持有xAI25%的股份。站长网2023-12-06 08:41:050000马云前助理回应“马云进军预制菜”:马家厨房肯定不做预制菜
日前,马云前助理陈伟在朋友圈称,马家厨房不做预制菜。国家企业信用信息公示系统显示,11月22日,杭州马家厨房食品有限公司注册成立,经营范围包括:食品销售(仅销售预包装食品)、货物进出口、食用农产品批发、日用品批发、酒店管理、技术服务等。股权穿透显示,该公司由杭州大井头贰拾贰号文化艺术有限公司全资持股,后者由马云持股99.9%。该消息被解读为为“马云入局预制菜”的信号。站长网2023-11-26 13:25:050001