AI视野:ChatGPT和API发生重大中断;GPTs分阶段推出计划延迟;中国第二批11个大模型备案获批;阿里将开源720亿参数大模型
📰🤖📢AI新鲜事
ChatGPT和API发生重大中断!
11月9日凌晨,OpenAI在官网发布,ChatGPT和API发生重大中断,导致全球所有用户无法正常使用,宕机时间超过2小时。OpenAI已经找到问题所在并进行了修复,但仍然不稳定,会继续进行安全监控。

【AiBase 提要】
⚠️ 宕机持续时间超过2小时
🔍 OpenAI已找到并修复问题
🔄 系统仍然不稳定,继续进行安全监控
OpenAI CEO宣布GPTs分阶段推出计划延迟
OpenAI CEO称GPTs的分阶段推出已延迟,因为工具需求超出预期,但人们渴望其服务。在首次DevDay活动中发布了新服务,如GPT Builder,支持ChatGPT,新工具需求超出预期,原计划11/13分阶段推出的GPTs被延迟。此举显示人们对OpenAI服务的渴望,部分用户已被授予提前访问权限。
【AiBase 提要:】
🚀 OpenAI在活动中发布了GPT Builder,支持ChatGPT,新工具需求超出预期,原计划11/13分阶段推出的GPTs被延迟。
💡 用户可创建定制ChatGPT版本,满足特定需求,显示OpenAI在人工智能领域不断进步。
👩💻 GPTs推出被延迟显示用户对OpenAI服务渴望,部分用户已获提前访问权限,表明对其服务有需求。
GPT-5爆料:多模态Gobi将在2024年初发布
根据爆料,OpenAI 的 GPT-5模型,即多模态模型 Gobi,将在2024年初发布。Gobi 支持文本、图像和视频,并且据称已初现自我意识。目前,多个政府机构正在测试最新模型。OpenAI 正在进行下一轮重大创新,即将发布 GPT-5。
【AiBase提要:】
🔹2024年初GPT-5将亮相,据说Gobi就是GPT-5。
🔹Gobi将支持文本、图像、视频,拥有自我意识。
🔹GPT-5或许即将出现,OpenAI在AI领域地位难有直接竞争对手。
中国第二批,11个大模型备案获批
报道,国内第二批通过备案的AI大模型包括11家公司,部分已面向全社会开放服务。加上首批的10余个大模型,目前已有超过20个大模型获得备案。
【AiBase提要:】
😊 国内第二批AI大模型备案包括11家公司【分别为网易有道("子曰"大模型)、面壁智能("面壁露卡Luca")、出门问问("序列猴子")、昆仑万维("天工"大模型)、美团、知乎("知海图AI"模型)、月之暗面(moonshot)、金山办公(WPSAI)、好未来(MathGPT大模型)、蚂蚁集团百灵大模型、360“奇元大模型”】
😊 部分大模型已向全社会开放服务
😊 面壁智能、出门问问、网易有道、昆仑万维已官宣消息
Hugging Face组建H4团队,开源开发类似ChatGPT的AI模型
人工智能初创企业 Hugging Face 近日宣布,其由两人组成的 H4团队正致力于开发工具和「配方」,以帮助 AI 社区构建类似于 ChatGPT 的人工智能聊天机器人。H4已推出多个大型开源语言模型,包括最近发布的聊天专用模型 Zephyr-7B-α。
【AiBase 提要:】
🔍 AI 初创公司 Hugging Face 组建 H4团队,开源开发类似 ChatGPT 的 AI 模型。H4的目标是提供工具和 “配方”,以便 AI 社区能够构建类似 ChatGPT 的 AI 聊天机器人。
🔍H4团队的主要研究重点是对齐技术,使语言模型能够根据人类反馈行为进行学习。
🔍H4团队已发布多个开源大型语言模型,包括聊天型 Zephyr-7B-α 和改进型 Falcon-40B。
天玑9300拿下生成式AI最强移动芯
在移动芯片领域,联发科的天玑9300以其强大的生成式AI能力引领潮流。首先,芯片支持最大330亿参数的大模型,并通过端侧LoRA融合实现本地扩展,能在手机上即时生成虚拟数字分身。其全新全大核CPU架构不仅提升40%性能,还节省33%功耗,成为移动AI性能的领跑者。
【AiBase提要:】
🔹 联发科天玑9300移动芯片支持最大330亿参数的大模型。
🔹 芯片通过端侧LoRA融合实现本地扩展,能在手机上即时生成虚拟数字分身。
🔹 天玑9300移动AI性能领跑,支持快速文本、图像生成、视频实时个人分身等多方面创新体验。
亚马逊训练比GPT-4参数多两倍的大型语言模型Olympus
亚马逊正在秘密开发一个代号为“Olympus”的大型语言模型,参数高达惊人的2万亿个,是OpenAI最新推出的GPT-4参数的两倍。这将使Olympus成为当前公开的模型参数最多的之一。
【AiBase 提要】
1. 亚马逊正在训练一个代号为Olympus的大型语言模型,参数达到惊人的2万亿个。
2. 相比之下,OpenAI的GPT-4参数仅为1万亿个,Olympus参数是其两倍之多。
3. 亚马逊拥有强大的云计算资源,有望通过Olympus在AI领域掀起波澜。
🤖📈💻💡大模型动态
阿里将开源720亿参数大模型
阿里巴巴集团CEO吴泳铭宣布即将开源720亿参数大模型,阿里云发布了通义星尘等应用模型,阿里云CTO周靖人表示将在11月开源通义千问720亿参数模型。
【AiBase提要:】
⭐ 阿里巴巴集团CEO吴泳铭宣布即将开源720亿参数大模型。
⭐ 阿里云发布了通义星尘等应用模型。
⭐ 阿里云CTO周靖人表示将在11月开源通义千问720亿参数模型。
vivo开源蓝心大模型BlueLM-7B系列
vivoAI开源了BlueLM-7B基础模型和7B对话模型,后续还将开源13B模型和支持多模态的7B-vl模型。
【AiBase提要:】
vivoAI开源了BlueLM-7B基础模型和7B对话模型;
vivo还将开源13B模型和支持多模态的7B-vl模型;
该语料库包含中文、英文以及少量日韩数据。
🤖📱💼AI应用
5个最佳草图到图像AI渲染工具
这些由AI驱动的草图到图像渲染工具不仅加速了创意工作流程,还使艺术创作变得更加民主化,使经验丰富的艺术家和新手都能以前所未有的轻松程度将他们的想法变为现实。
【AiBase 提要】
OpenArt (地址:https://openart.ai/)提供多功能工具,将草图无缝转化为高保真图像;
PromeAI (地址:https://www.ishencai.com/)通过实时渲染功能快速将草图转化为逼真图像;
Vizcom(地址:https://www.vizcom.ai/)拥有丰富的创意工具套件,提供高分辨率渲染和协作功能;
SketchAI(地址:https://sketchai.app/) 利用 AI 算法将草图转化为逼真图像或艺术杰作;
Scribble to Art(地址:https://scribbletoart.com/)提供简化的草图转化工具,方便快速生成图像。
GitHub推出Copilot Enterprise助手
微软 GitHub 推出更昂贵的企业级 Copilot Enterprise 助手,该助手可学习公司的私有代码,对企业价值有所提升。
【AiBase提要:】
🤖微软推出更昂贵的企业级Copilot Enterprise助手
🏢CopilotEnterprise专为公司内部开发者设计,解释和提供有关内部源代码的推荐
🔗GitHubCopilotEnterprise的费用将是企业版的两倍多,每人每月39美元。
Tubi发布Rabbit AI 为观众批量推荐电影
视频平台开始在搜索栏布局 AI 功能,帮助观众改善选择影片的体验。Tubi 平台内置的 Rabbit AI 通过文本问答方式快速推荐影视剧。爱奇艺引入 AI 剧集搜索功能,快速定位高光片段,总结剧集内容。这些 AI 搜索助手可以帮助观众快速找到喜欢的剧集,节省时间。
【AiBase提要:】
😊 视频平台开始利用AI功能帮助观众选择影片,国内爱奇艺视频平台应用生成式AI在剧情搜索等场景,旨在让观众实现“搜索即观看”。
😊 Tubi发布了“Rabbit AI”,允许用户通过简单的提示和问题浏览Tubi的内容库,实现快速找到自己喜欢的影视剧。
😊 生成式AI技术的实际效果还存在一些问题,如无法精确找到相应的影视剧等。
GitHub发布Copilot Workspace 开发者第二大脑来袭
Copilot Workspace 可以帮助开发者完成更大、更复杂的任务,侧重于任务选择、意图表达和与 AI 合作寻求解决方案,结合了AI智能体技术和GitHub Codespaces实现无头、短暂、安全的计算方式。

地址:https://githubnext.com/projects/copilot-workspace
【AiBase 提要】
🤖Copilot Workspace可以帮助开发者完成更大、更复杂的任务。
🎯Copilot Workspace侧重于任务选择、意图表达和与AI合作寻求解决方案。
🔐结合了AI智能体技术和GitHub Codespaces实现无头、短暂、安全的计算方式。
👨💻💡🎯聚焦开发者
Hugging Face研究人员推语音识别模型Distil-Whisper
Hugging Face研究人员最近解决了在资源受限环境中部署大型预训练语音识别模型的问题,提炼出了Whisper模型的较小版本Distil-Whisper,速度和参数均有提高。
项目网址:https://github.com/huggingface/distil-whisper
【AiBase提要:】
⦁ Hugging Face研究人员利用伪标记创建了一个庞大的开源数据集,用于提炼
⦁ Distil-Whisper在挑战性的声学条件下保持了Whisper模型的韧性,同时减轻了长篇音频中的错觉错误。
⦁ 自动语音识别(ASR)系统已达到人类水平的准确度,但由于预训练模型的不断增大,在资源受限的环境中面临挑战。
北大腾讯提出多模态对齐框架LanguageBind
北大腾讯提出多模态对齐框架LanguageBind,并在多个榜单中取得了优异表现。对于多模态对齐,新框架以语言为中心通道实现多模态信息的语义对齐。研究团队构建了VIDAL-10M数据集,这是一个大规模、多模态数据对的数据集。
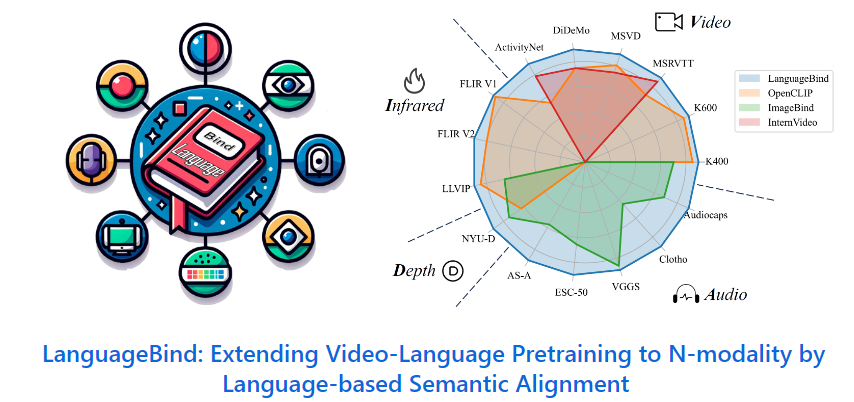
项目地址:https://github.com/PKU-YuanGroup/LanguageBind
【AiBase 提要】
👍 语言作为中心通道实现多模态信息的语义对齐
👍 构建了VIDAL-10M数据集,是一个大规模、多模态数据对的数据集
👍 多模态对齐框架LanguageBind的提出为多模态预训练技术的发展奠定了坚实基础
FACTOR:无需训练即可自动检测深度伪造技术
最新发布的GitHub工具FACTOR采用事实核查技术来检测数字媒体,无需事先进行训练,能够自动检测深度伪造技术。
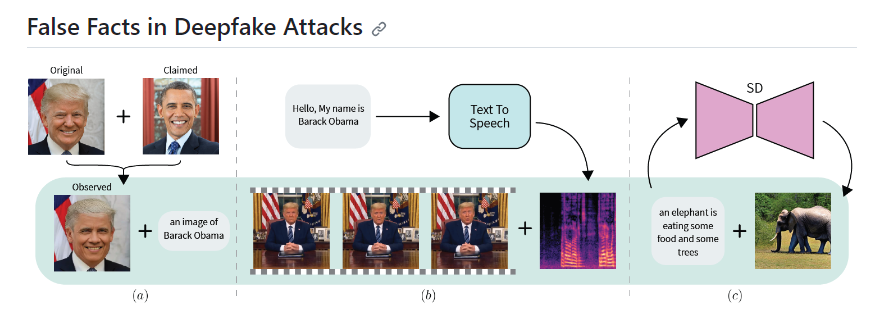
【AiBase 提要】
🤖使用事实核查技术来检测数字媒体。FACTOR无需事先训练,有效区分真实和伪造媒体。
📊能够检测三种深度伪造类型,包括面部伪造、音频-视觉伪造和文本-图像伪造。
🔍利用“真实度分数”,通过余弦相似性来量化虚假事实和深度伪造的不完美合成之间的相似性。
2023快手泛知识报告:2022年“副业”搜索量增长103.5%
快手大数据研究院发布《2023快手泛知识报告》称。根据报告显示,2022年,快手的泛知识视频发布量同比增长了39.6%,直播播放量同比增长了60.6%。此外,拥有万粉以上的创作者在快手发布的视频量达到了1.1亿。2022年,“学会”在快手评论区出现了4400多万次,“有用”出现了3400多万次。而2022年,“副业”这一关键词的搜索量增长了103.5%,其中超过五成的搜索人群是00后。站长网2023-04-24 14:30:440003抖音回应洽谈收购饿了么:无稽之谈 没有这个计划
近日,有传闻称抖音正在与阿里洽谈收购饿了么。对此,饿了么内部人士回应称,双方合作一直在稳步推进,但所谓“收购”完全是无稽之谈。抖音内部人士也回复称,彭博社没有这个报道,抖音也没有这个计划。早在2022年8月,饿了么和抖音就曾宣布达成合作,共同探索本地生活服务的新场景升级。站长网2023-12-19 16:30:180000马斯克真的开始练格斗了!马斯克练习格斗照片曝光
站长之家(ChinaZ.com)6月28日消息:今天,播客主持人LexFridman发布了两张与马斯克练习格斗的照片。此前,Fridman还分享了与扎克伯格一起练习柔术的视频。从曝光的照片来看,马斯克确实非常认真地练习,并展示了一记漂亮的过肩摔。据悉,在本月22日,马斯克在推特上发布了一条消息,表示愿意与扎克伯格进行一场笼斗。站长网2023-06-29 11:34:480003小米手表S4首发搭载小米澎湃OS 2:将于小米15系列同日发布
小米官方宣布,即将在10月29日的发布会上亮相一系列新品,其中包括小米15系列手机、小米SU7Ultra量产版,以及搭载了全新小米澎湃OS2系统的小米手表S4等多款新品。小米手表S4的外观设计已经公布,这款手表将成为首批搭载小米澎湃OS2系统的设备之一。澎湃OS2系统的引入,为小米手表S4带来了全新的融合设备中心,使用户能够通过单一的手表控制汽车和家中的智能设备。00004599元限量抢!Redmi K70 Pro冠军版12月28日再次开售
Redmi市场总经理王腾宣布,备受关注的RedmiK70Pro冠军版将于12月28日上午10:00再次开售。这款RedmiK70Pro冠军版是一款24GB1TB的版本,售价仅为4599元,相比标准版的K70Pro仅贵了200元。如此高性价比的版本,必然引发抢购热潮。0003