DIRFA:只需音频和照片即可创建逼真的说话脸部动画
划重点:
👉 研究人员开发了一个计算机程序,只需音频和一张照片即可创建反映说话者面部表情和头部动作的逼真视频。
👉 这个名为 DIverse yet Realistic Facial Animations(DIRFA)的人工智能程序能够根据音频和照片生成3D 视频,显示人物与所说的音频同步的逼真而一致的面部动画。
👉 DIRFA 可应用于各个领域,包括医疗保健,它能够改进用户体验,使虚拟助手和聊天机器人更加复杂和逼真,同时对于有言语或面部残疾的个人来说,它也能帮助他们通过表情丰富的化身或数字形象来传达他们的思想和情感,增强他们的沟通能力。
新加坡南洋理工大学(NTU Singapore)的一支研究团队开发了一个计算机程序,只需音频和一张照片,即可创建反映说话者面部表情和头部动作的逼真视频。
这个名为 DIverse yet Realistic Facial Animations(DIRFA)的人工智能程序能够根据音频和照片生成3D 视频,显示人物与所说的音频同步的逼真而一致的面部动画。该程序改进了现有方法,解决了姿势变化和情感控制等问题。

为了实现这一目标,研究团队训练 DIRFA 使用了来自一个名为 The VoxCeleb2Dataset 的开源数据库的超过6000人的100多万个音频视频片段,以预测语音中的线索并将其与面部表情和头部动作联系起来。
研究人员表示,DIRFA 可能在各个行业和领域中产生新的应用,包括医疗保健。它可以使虚拟助手和聊天机器人更加复杂和逼真,从而改善用户体验。此外,它还可以作为一种强大的工具,帮助言语或面部受损的人通过表情丰富的化身或数字形象来传达他们的思想和情感,提高他们的沟通能力。
该研究的的研究人员表示:“我们的研究影响可能是深远的,因为它通过结合人工智能和机器学习等技术,彻底改变了多媒体通信的领域。我们的程序在之前的研究基础上进行了改进,只使用音频记录和静态图像,就能生成具有准确的嘴唇动作、生动的面部表情和自然的头部姿势的视频。”
研究人员还介绍称:“语音表现出多种变化。在不同的语境下,个体对相同的词语发音可能会有不同的方式,包括持续时间、幅度、音调等方面的变化。此外,除了语言内容,语音还传达了有关说话者情感状态和性别、年龄、种族甚至个性特征等身份因素的丰富信息。我们的方法在音频表示学习和人工智能机器学习方面进行了开创性的努力。” 研究结果于8月份发表在《Pattern Recognition》科学期刊上。
研究人员表示,通过音频驱动逼真的面部表情呈现是一个复杂的挑战。对于给定的音频信号,可能有许多可能的面部表情是合理的,而在处理随时间变化的一系列音频信号时,这些可能性可能会增加。
由于音频通常与嘴唇动作有很强的联系,但与面部表情和头部位置的联系较弱,研究团队的目标是创建能够展示精确的嘴唇同步、丰富的面部表情和与提供的音频相对应的自然头部动作的说话脸部。
为了解决这个问题,研究团队首先设计了他们的人工智能模型 DIRFA,来捕捉音频信号和面部动画之间复杂的关系。他们使用来自一个公开可用的数据库的超过6000人的100多万个音频和视频片段对模型进行了训练。
研究人员介绍:“具体而言,DIRFA 模型根据输入的音频来建模面部动画(如挑起眉毛或皱鼻子)的可能性。这种建模使得该程序能够将音频输入转换为多样而逼真的面部动画序列,从而指导说话脸部的生成。”
研究人员还补充说:“广泛的实验表明,DIRFA 能够生成具有准确的嘴唇动作、生动的面部表情和自然的头部姿势的说话脸部。然而,我们正在努力改进程序的界面,使得用户能够对某些输出进行控制。例如,DIRFA 目前不允许用户调整某种表情,比如将皱眉改为微笑。”
除了向 DIRFA 的界面添加更多选项和改进外,NTU 的研究人员还将使用更广泛的数据集来微调其面部表情,包括更多种类的面部表情和声音音频片段。
论文地址:
https://www.ntu.edu.sg/docs/default-source/corporate-ntu/hub-news/realistic-talking-faces-created-from-only-an-audio-clip-and-a-person-s-photo-using-ntu-singapore-computer-program.pdf?sfvrsn=41d32b2a_1
被偷跑的《黑神话:悟空》们,拿什么回击泄密者?
和近年来的所有热门游戏一样,万众瞩目的《黑神话:悟空》也没能逃过泄密。就在正式发售前夕,几段几十秒长度的游戏视频开始在互联网上传播,四散于各个群聊和视频平台。尽管游戏科学针对相关泄密采取了一定补救手段,但想要彻底阻断其民间传播,放在网络环境无比复杂的当下恐怕并不容易。站长网2024-08-22 08:57:400000谷歌前 CEO:2024 年选举 AI 生成虚假信息将会泛滥成灾
谷歌前首席执行官、SchmidtFutures的联合创始人埃里克·施密特表示,由于新工具使先进的人工智能更易获取,围绕2024年选举的虚假信息将会泛滥成灾。站长网2023-06-28 09:26:560000他们利用ChatGPT将1.5万卢比的投资变成1亿卢比
🔍划重点:1.两个创业者在数月内使用ChatGPT将1.5万卢比的投资变成1亿卢比2.他们开发了DimeADozen,一个用于测试商业创意的AI研究工具3.他们的AI工具在短时间内超越传统分析机构和搜索引擎,吸引了15,000美元的收购交易站长网2023-10-25 20:02:390000剪映海外版CapCut推文生视频功能 每人每天可免费生成5个视频
剪映海外版CapCut推出了一项新的功能,即文字生成视频(AI影片),它允许用户通过输入文字描述来自动转换成短视频。该功能旨在帮助各类用户提高视频制作的效率和便捷性。官方入口:https://top.aibase.com/tool/capcutwenshengshipin主要功能特点:支持AI自动转换:用户只需输入文字提示,系统就能自动生成对应的视频内容。站长网2024-02-23 14:21:3200095分钟生成漫威3D数字人 渐进式3D生成框架“DreamFace”来了!
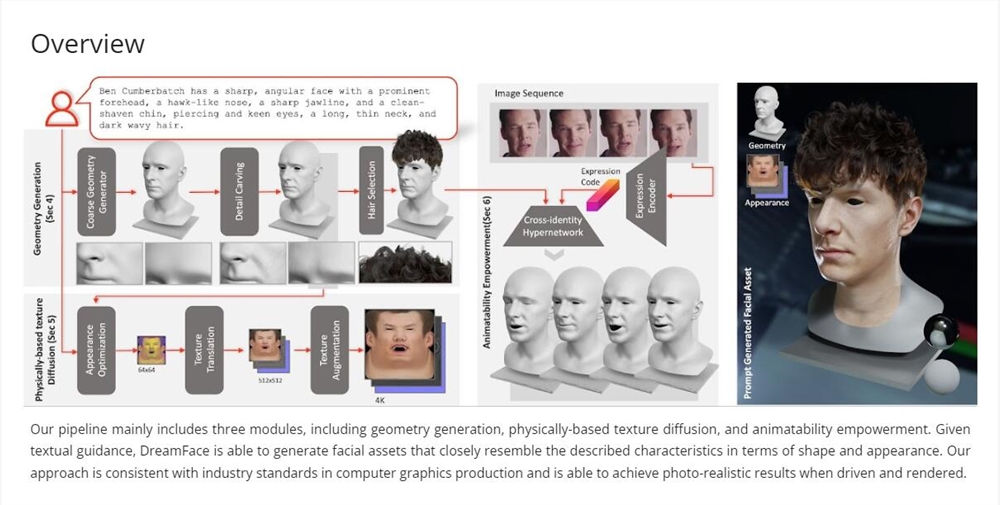
最近,影眸科技与上海科技大学的研发团队提出了一种文本指导的渐进式3D生成框架——DreamFace,结合了视觉-语言模型、隐式扩散模型和基于物理的材质扩散技术,可以生成符合计算机图形制作标准的3D资产。项目网站:https://sites.google.com/view/dreamface预印版论文:https://arxiv.org/abs/2304.03117站长网2023-05-04 10:30:510000