效果超越SDXL!港中大博士生推出超真实人像合成工具,训练用了3.4亿张图
为了让AI画出的人更加逼真,港中大博士生用了3.4亿张图像专门训练画人。
人物的表情、姿态,环境的空间关系、光线都能合理布局,可谓立体感十足。
就连爆火的SDXL也不是它的对手,话不多说,直接上图!

这个模型的名字叫HyperHuman,主打的就是一个真实立体。
它解决了Stable Diffusion等传统AI绘图工具在画人时图像不连贯、姿态不自然的问题。
而且不仅画得好,也更加“听话”,画出的内容能更好地匹配提示词。

那么下面就来具体看看HyperHuman都能创作出哪些作品吧!
无论是孩子还是老人,各个年龄段的人人物形象HyperHuman都可以画。
人物的动作、表情自然,空间关系看着也很合理。

不仅是图本身看上去真实,和提示文本的匹配也十分精确。

人物之外,HyperHuman能绘制出的场景类型也多种多样。
无论是单人还是多人,是滑雪或者冲浪……

如果和其他模型对比一下的话……
很明显,在这组提示词中,其他模型基本上都没能正确画出停止标志,而HyperHuman则正确地绘制了出来。
A man on a motorcycle that is on a road that has grass fields on both sides and a stop sign.

而在这一组中,其他模型的作品或者不知所云,或者出现各种细节问题,更有甚者画出的人长了三只脚,但HyperHuman依旧是稳定发挥。
Mastering the art of skateboarding is profoundly beneficial.

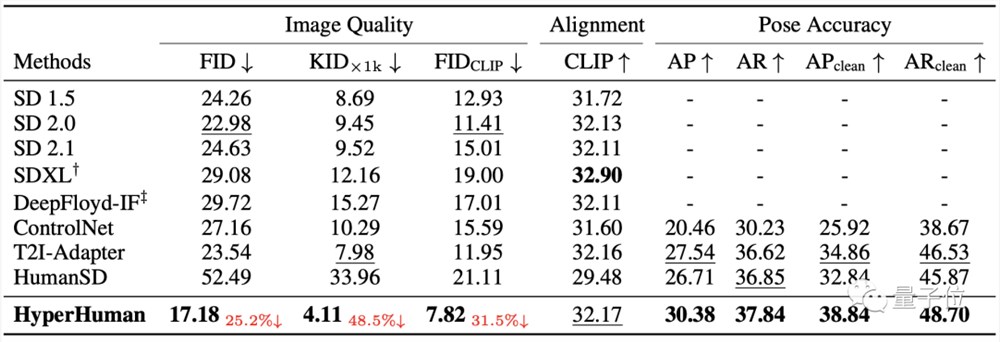
不仅是直观感受,在数据上HyperHuman也是全面碾压包括SD2.0在内的一众竞争对手。
图像质量方面,HyperHuman的FID、KID两项指标(均为数值越低效果越好)都超过了其他模型四分之一以上。
姿势准确度上,HyperHuman的两项评分也明显胜过了ControlNet等其他模型。
那么,HyperHuman又是如何实现的呢?
联合学习,分步生成
为了提高HyperHuman的效果,研究团队一共提出了两个思路。
首先是同时学习图片的颜色、深度图和法线图。
颜色反映外观,深度图反映物体位置,法线图反映表面角度。将它们一起学习,可以让模型更好地理解图片内容。
第二点则是分阶段生成,先使用文本和骨架点作为条件,生成颜色、深度和法线三者的初步合成结果。
然后以前面生成的条件作为指引,生成更高分辨率和质量的图片。

具体实现上,HyperHuman和SDXL一样也是采用扩散模型。
具体而言,HyperHuman使用的是“潜在结构(latent structal)”模型。
它的核心包括以下两个模块:
联合去噪模块:具有多个输入输出分支的统一网络结构,在颜色、深度和法线图三个维度同时去除噪声。
结构指导模块:用上一步产生的结果作为条件和指引,实现结构到纹理的精细化生成。
此外,为了提高鲁棒性,模型在生成过程中还会选择的的对一些条件进行取舍。
训练数据方面,开发者将LAION-2B和COYO两个数据集中的公开资源进行整合并处理、标注,得到了约3.4亿张图像的HumanVerse数据集。
结果在基于COCO2014数据集的多个绘图模型横评中,HyperHuman(红色)都取得了最佳成绩,如果考虑文本匹配度,HyperHuman更是一骑绝尘。

△FID数值越低成绩越好
除了测试数据,研究人员还招募了100名用户,调查了他们更青睐于哪种模型的作品。
他们被要求选出更逼真、质量更好的图像,结果和另外多种模型相比,HyperHuman都更受欢迎。

作者简介
HyperHuman论文第一作者是香港中文大学博士生Xian Liu。
HyperHuman是他在Snap公司实习期间完成的,Snap的Sergey Tulyakov等人也参与了本项目。
此外还有香港大学和南洋理工大学的学者对HyperHuman亦有贡献。
AI日报:干翻AI PC!苹果M4芯片首发;GoEnhance可生成粘土风格视频;DeepSeek-V2模型已在魔搭社区开源;苹果将添加AI图片擦除功能
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、干翻AIPC!苹果M4芯片首发新款iPadPro顶配超2万站长网2024-05-09 20:26:230000OpenAI 的 GPT-4 变得「懒惰」和「愚蠢」:或被 MoE 彻底重塑导致性能下降
世界上最强大的人工智能模型似乎变得不那么强大了。这让业内人士开始谈论可能会对该系统进行重大重新设计。最近几周,OpenAI的GPT-4的用户们纷纷抱怨性能下降,有些人将这个模型与以前的推理能力和其他输出进行比较,称其变得「懒散」和「更笨」。站长网2023-07-14 09:50:370000PBT集团表示,数据质量对训练ChatGPT至关重要
划重点:1.🚀ChatGPT在公开发布近一年后迎来了爆炸性增长,但其广泛应用也引发了一系列问题,包括偏见输出、问题误解、答案不一致、缺乏同理心以及安全问题。2.💼在企业环境中,ChatGPT被广泛应用于增强各种业务流程,如客户服务、邮件起草、个人助理任务、关键词搜索和演示文稿制作。文章强调了对ChatGPT提供准确响应的必要性,特别是需要对公司相关、准确且及时的数据进行培训。站长网2023-11-24 15:48:140000科学家利用 AI 发现 60 多年来首个新抗生素:有望对抗耐药性感染
事实证明,人工智能(AI)的使用将改变医学领域的游戏规则,目前该技术正在帮助科学家开发出60年来首个新型抗生素。人工智能(AI)技术的应用在医学领域取得了重大突破,帮助科学家发现了针对抗药性金黄色葡萄球菌(MRSA)的新型抗生素。这一发现有望成为抗击抗生素耐药性斗争的转折点。0000Mamba 模型在视频理解任务中展现出强劲潜力 打败Transformer
划重点:⭐Mamba模型在视频专用和视频-语言任务中展现出强劲的潜力,实现了效率与性能的理想平衡⭐Mamba模型的VideoMambaSuite套件12个视频理解任务中得到全面评估,显示出潜在的优势和多样化角色⭐通过在视频时间任务、多模交互任务等领域的表现,Mamba模型展现出与Transformer不同的优越性能和效率站长网2024-05-01 15:06:520001