带记忆的超级GPT智能体,能做饭、煮咖啡、整理家务!
随着AI技术的快速迭代,Alexa、Siri、小度、天猫精灵等语音助手得到了广泛应用。但在自然语言理解和完成复杂任务方面仍然有限。
相比文本的标准格式,语音充满复杂性和多样性(例如,地方话),传统方法很难适应不同用户的自定义语言,因此,语音助手需要针对固定领域设计语义解析方案,而无法对完全开放的语言进行建模。
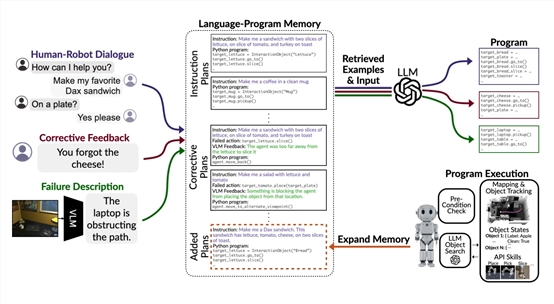
为了解决这一难题,卡内基梅隆大学的研究人员基于大语言模型、视觉模型开发了HELPER。
该模型采用了检索增强的大语言模型提示方法,可以将人机对话、指令和错误纠正转换为一系列参数化的视觉运动。
同时在成功执行指令后,HELPER会将语言指令和执行计划作为记忆进行存储。
当用户再次提出类似请求时,HELPER会自动检索相关记忆并进行适当修改来满足新的要求,从而实现个性化交互。
在TEACh的实验数据显示,从对话中推断步骤的测试中,HELPER的任务成功率和目标条件成功率分别提高了1.7倍和2.1倍,超过了之前最好的模型。在从历史对话中执行任务中,HELPER也取得了绝佳的效果。
开源地址:https://github.com/Gabesarch/HELPER
论文地址:https://arxiv.org/abs/2310.15127
研究人员用物理模拟的方式展示了多个示例,HELPER可以进行洗锅、煮咖啡、做面包、整理卡片、制作饮料等一系列拟人化操作,并且你只需要详细的告诉它一次就能记住你的需求,以后无需多说就能照着做。

从论文内容来看,HELPER的技术架构主要由规划器、执行器和视觉语言模型三大块组成。
规划器
该模块利用检索增强的大语言模型来进行语义解析和生成一系列执行计划,同时配备了一个文本到程序的外部记忆存储器,相当于该模型的“大脑”。
在进行语言解析时,规划器会先基于当前语言的输入,使用大语言模型的编码器计算输入文本的向量表示,然后检索出记忆库中语义最相关的若干条记录,将其中的文本-程序对作为LLM的文本示例,随后让LLM生成新的程序。
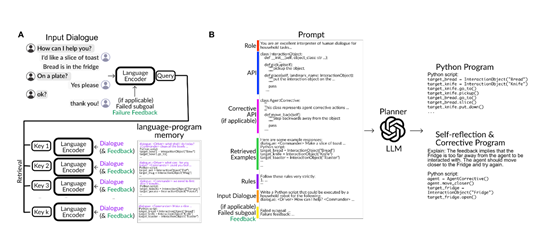
生成的程序使用Python语言描述,涵盖一系列参数化的视觉运动函数,如pickup(X)、goto(X)等,同时也负责处理执行失败后的重新规划。
例如,当某个动作执行失败时,系统会调用外部的视觉语言模型来分析失败原因并生成文本反馈, 规划器随后会根据反馈提示LLM生成修正后的新程序。
此外, 规划器也会在任务成功执行后,将用户指令语言和对应的执行程序加入记忆库中,实现个性化学习。
执行器
该模块主要负责解析规划器生成的程序,并基于当前环境执行指令操作,具体操作如下:
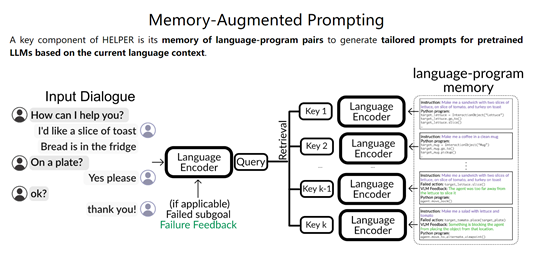
场景解析器:构建环境的语义地图、占用地图,以及通过目标检测跟踪对象信息。
动作执行器:将程序中的函数调用翻译成具体的导航和操作动作执行。
前提检查器:在执行每个动作前,验证必要的前提条件是否满足。
位置检查器:当需要找到不在场景地图中的目标物体时,该模块会提示LLM生成可能的搜索位置。
简单来说,执行器模块相当于HELPER的“四肢”,用来执行具体的内容。
视觉语言模型
当具体计划执行失败时,系统需要分析失败原因。所以,HELPER使用了视觉语言模型ALIGN进行纠错、审查。

方法是将当前视觉输入与一系列预定义的错误文本进行匹配,输出最相似的错误类型,帮助规划器模块快速找到错误所在。这种方法比简单的像素对比判断故障类型更加精准和通用。
阿里云与深圳数据交易所签署战略合作 共同探索大模型
据阿里云官方消息,近日,深圳数据交易所与阿里云签署战略合作框架协议。双方将在数据基础设施建设、数据生态、探索大模型应用等方面展开合作,进一步促进数据要素流通。根据合作框架协议,深圳数据交易所将与阿里云展开广泛合作,其中包括进一步推进数据可信流通和交易的基础设施建设,数据治理和安全合规技术合作,数据质量和资产价值评估研究,共建共享数据开发与服务生态,并探索大模型在数据要素领域的应用等。站长网2023-04-23 16:38:530004“云养老”的年轻人,再次爱上鉴宝直播
“故宫一对我一对”“来靠近点我看看……东西是老的一眼大开门(真货)”最近,抖音平台上的鉴宝直播再次出圈,@海东鉴宝、@听泉寻宝等博主与宝友(指文玩玉石爱好者)直播连线鉴宝,节目效果十足,引起广大网友关注。早在二十多年前,鉴宝节目在电视上就已经有很多忠实观众。王刚主持的《天下收藏》就因为会在“护宝”环节砸掉所谓的“赝品”而噱头十足。站长网2024-02-02 11:07:190000Gartner调查显示,生成式AI已成为企业面临的新兴风险
本文概要:1.生成式AI成为企业风险管理人员最关注的问题之一。2.生成式AI的大规模可用性带来潜在风险,如知识产权、数据隐私和网络安全问题。3.第三方生存能力是企业最重要的新兴风险之一,可能导致供应商中断或倒闭。站长网2023-08-09 20:03:240000剧情低俗!微信:下架微短剧《大佬 你女儿被婆婆家欺负惨了》
快科技6月4日消息,微信珊瑚安全官方公众号今天发布公告称,平台近期已发布专项治理公告,持续打击传播不良价值观等违规微短剧内容。在专项治理期间发现微短剧《大佬,你女儿被婆婆家欺负惨了》存在剧情低俗,台词、画面、情节等涉及使用残忍犯罪手段造成恶劣后果,刻意制造放大和渲染婆媳、男女矛盾。此外还传播违反公序良俗言论,渲染血腥暴力,破坏了平台良好生态,平台已将该剧下架,现予以公示。站长网2024-06-05 12:31:160000人工智能在欺诈检测中的作用:保卫金融安全的强有力工具
随着数字化世界的不断发展,金融交易和商业运营领域也发生了翻天覆地的变化。与此同时,金融欺诈的复杂程度也呈现明显的上升趋势。为了应对这个问题,许多组织开始转向先进的技术手段,而人工智能(AI)被证明是他们武器库中最强大的工具之一。在欺诈检测领域,AI正在革新我们识别和预防金融犯罪的方式。站长网2023-10-30 11:30:240000