清华大学提出全新加速训练大模型方法SoT
要点:
研究人员提出了一种名为“Skeleton-of-Thought(SoT)”的创新方法,旨在加速大型语言模型(LLMs)的生成速度,以解决其处理速度较慢的问题。
与传统方法不同,SoT不对LLMs进行复杂的修改,而是将其视为黑匣子,专注于优化输出内容的组织,通过引入独特的两阶段过程来提高响应速度。
通过对12个不同领域的模型进行测试,使用Vicuna-80数据集,研究团队观察到SoT在八个模型上实现了1.13x到2.39x的速度提升,而不牺牲答案质量。
近日,微软研究和清华大学的研究人员共同提出了一种名为“Skeleton-of-Thought(SoT)”的全新人工智能方法,旨在解决大型语言模型(LLMs)生成速度较慢的问题。
尽管像GPT-4和LLaMA等LLMs在技术领域产生了深远影响,但其处理速度的不足一直是一个制约因素,特别是在对延迟敏感的应用中,如聊天机器人、协同驾驶和工业控制器。SoT方法与传统的性能提升方法不同,它不对LLMs进行复杂的修改,而是将其视为黑匣子,并侧重于优化输出内容的组织结构。
项目地址:https://github.com/imagination-research/sot/
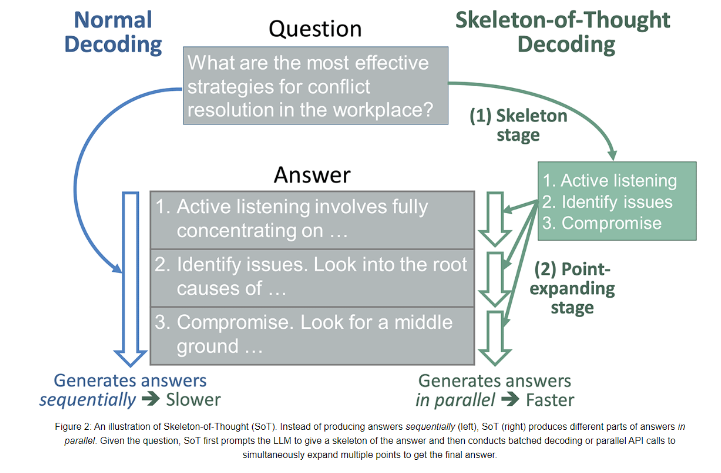
SoT引入了一个独特的两阶段过程,首先引导LLM构建答案的骨架,然后在第二阶段使LLM同时扩展骨架中的多个要点。这一方法不仅提高了LLMs的响应速度,还在不需要对模型架构进行复杂调整的情况下实现了这一目标。
为了评估SoT的有效性,研究团队对12个不同领域的模型进行了广泛测试,使用了Vicuna-80数据集,其中包含了来自编码、数学、写作和角色扮演等各个领域的问题。
通过使用FastChat和LLMZoo的度量标准,研究团队观察到SoT在八个模型上实现了1.13x到2.39x的速度提升,而且这些提升并没有牺牲答案质量。这表明SoT不仅可以显著提高响应速度,还能够在各种问题类别中保持或提升答案质量。
因此,SoT方法为解决LLMs速度较慢的问题提供了一种有前景的解决方案。研究团队的创新方法将LLMs视为黑匣子,并专注于数据级别的效率优化,为加速内容生成提供了新的视角。通过引导LLMs构建答案的骨架,然后进行并行扩展,SoT有效地提高了响应速度,为人工智能领域的动态思维过程开辟了新的探索方向,鼓励向更高效、更多才多艺的语言模型发展。
字节跳动澄清“实习生破坏大模型训练”:公司大模型不受影响
快科技10月19日消息,今天下午,字节跳动发布了关于实习生破坏大模型训练”的事实澄清公告。公告称,近期有媒体称字节跳动大模型训练被实习生攻击”,经公司内部核实,确有商业化技术团队实习生发生严重违纪行为,该实习生已被辞退。字节跳动表示,相关报道也存在部分夸大及失实信息,特说明如下:站长网2024-10-20 08:53:370000AI前哨|谷歌CEO最新专访实录:十个AI问题 事关人类生存发展
凤凰网科技讯《AI前哨》北京时间6月13日消息,面对来势汹汹的ChatGPT,谷歌CEO桑达尔皮查伊(SundarPichai)周一在接受采访时称,在某些人工智能(AI)领域,公司确实落后了。但是,他并不急于快速推进公司的前进步伐,因为谨慎很关键。以下是皮查伊的采访摘要:1.和竞争对手的进展相比,你对谷歌聊天机器人巴德(Bard)的现状满意吗?0000百度搜索发布违规低质页面问题说明 站长需注意低质采集、功能异常等问题
百度搜索发布违规低质页面问题说明称,鼓励网站站长生产优质的页面,包括快速打开的页面、内容与标题一致、丰富有深度且真实鲜活、具有一定权威性的内容。同时,百度搜索也会定期监控和清理违规低质的页面,如低质采集、色情、功能异常等。站长网2023-09-01 10:47:430000小米集团一季度营收755亿元 同比增长27%
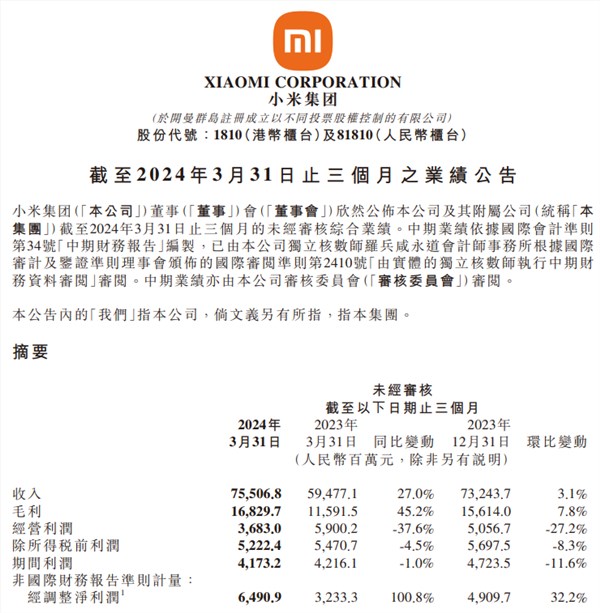
今日,小米集团公布了其2024年第一季度的财务报告,报告显示,该季度小米集团的营收达到了755.1亿元,较去年同期增长了27%,同时,经过调整后的净利润达到了64.9亿元,同比增长更是高达100.8%。站长网2024-05-24 10:42:490000创新视频制作平台Pipio:简单的文字脚本即可生成真人化的数字角色
Pipio是一个创新的视频制作平台,能够通过简单的文字脚本,使用真人化的数字角色,在几分钟内制作出高质量的视频。Pipio视频制作简单高效,无需考虑演员选择、场景取景、昂贵的设备和复杂的后期编辑。用户只需要输入文字脚本,选择数字角色和语音,Pipio即可自动生成视频。平台拥有多种语言和种族的数字角色可供选择,提高视频的多样性和可观性。站长网2023-09-05 14:38:240000