中国团队开源大规模高质量图文数据集ShareGPT4V
要点:
中国团队开源大规模高质量图文数据集ShareGPT4V,基于GPT4-Vision构建,训练了一个7B模型,在多模态性能上超越同级模型。
ShareGPT4V数据集包含120万条图像-文本描述数据,涵盖世界知识、对象属性、空间关系、艺术评价等多方面,超越现有数据集在多样性和信息涵盖度方面。
使用ShareGPT4V数据集进行实验,研究者展示了其在多种架构和参数规模的多模态模型中的有效性,最终得到了在多模态基准测试上表现优异的ShareGPT4V-7B模型。
中国团队最近开源了一个引人瞩目的图文数据集,命名为ShareGPT4V,它基于GPT4-Vision构建,训练了一个7B模型。这一举措在多模态领域取得了显著的进展,超越了同级别的模型。
该数据集包含了120万条图像-文本描述数据,涵盖了世界知识、对象属性、空间关系、艺术评价等多个方面,在多样性和信息涵盖度上明显优于现有数据集。

论文地址:https://arxiv.org/abs/2311.12793
Demo演示:https://huggingface.co/spaces/Lin-Chen/ShareGPT4V-7B
项目地址:https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V
多模态模型的性能在很大程度上受制于模态对齐的效果,而现有工作中缺乏大规模高质量的图像-文本数据。为了解决这一问题,中科大和上海AI Lab的研究者们推出了ShareGPT4V,这是一个开创性的大型图文数据集。
通过对GPT4-Vision模型产生的10万条图像-文本描述数据进行深入研究,他们成功构建了这一高质量的数据集,涉及的内容丰富多样,包括世界知识、艺术评价等。
这一数据集的推出为多模态研究和应用奠定了新的基石。在实验中,研究者们展示了ShareGPT4V数据集在多种架构和参数规模的多模态模型中的有效性。通过等量替换实验,他们成功提升了多种模型的性能。
最终,通过在预训练和有监督微调阶段同时使用ShareGPT4V数据集,他们得到了ShareGPT4V-7B模型,在多模态基准测试中取得了优异的成绩。
这一研究为未来的多模态研究和应用提供了有力支持,也促使多模态开源社区关注高质量图像描述的开发,预示着更强大、智能的多模态模型的出现。这一成果对于推动人工智能领域的发展具有积极的意义。
沙特阿美CEO警告生成式人工智能的新威胁
划重点:1.🚨能源行业面临新威胁:沙特阿美首席执行官警告,随着产生式人工智能等新技术的出现,能源行业变得更加脆弱。2.🤝全球合作呼吁:沙特阿美CEO呼吁全球合作,建立国际标准以应对人工智能的负面影响。3.💼跨行业合作必要:他指出,各方需要共同合作,以确保集体安全,并建立国际标准和最佳实践,以防范潜在威胁。站长网2023-11-03 16:25:200000Discord 封禁涉及大规模信息窃取及出售的账户
划重点:🛡️Discord封禁Spy.Pet相关账户,该网站涉嫌窃取并出售来自1.4万个Discord服务器的用户信息。💬Spy.Pet网站使用机器人从14,000个Discord服务器中获取信息,包括约6.2亿用户的消息。🔍Discord对此进行了调查,并封禁了多个与该网站相关的账户,考虑采取法律行动。站长网2024-04-28 16:57:240001梁建章喊话携程员工来领育儿补贴:每生一个孩子发5万元奖励
在2024年ESG全球领导者峰会上,携程集团董事局主席梁建章宣布了一项重大的员工福利政策:为每位员工生育的子女提供5万元人民币的奖励。为此,携程已经预备了高达10亿元人民币的资金。梁建章表示,他期望这一措施能够吸引政府的关注,并促进政府推出更多鼓励生育的政策。梁建章还提出了推广居家办公的建议,认为这样做可以实现社会、员工和公司三方的共赢局面。0000小米汽车APP在苹果App Store上架
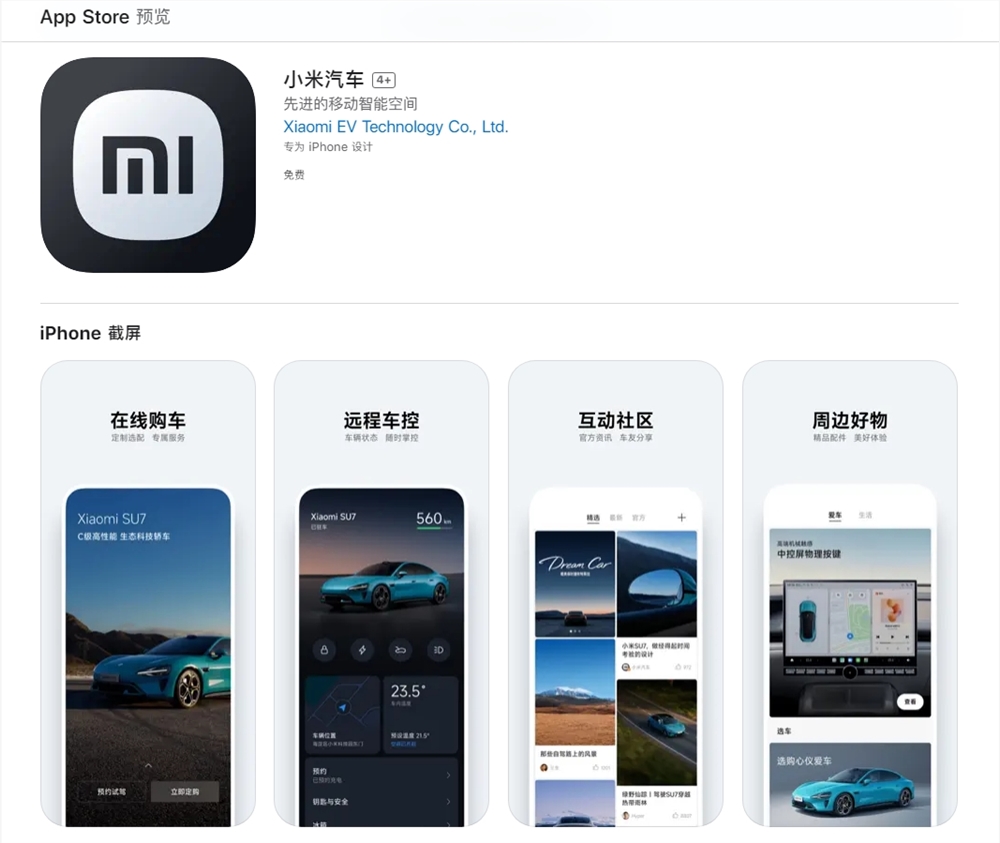
今日,“小米汽车”APP已上架苹果AppStore。据介绍,“小米汽车”是一款专为iPhone设计的先进移动智能空间应用。该应用提供了以下主要功能:1.购车:用户可以了解小米汽车的核心亮点和技术参数,预约试驾、配置订购自己的小米汽车,并支持在线处理提车待办事项。2.社区:用户可以获取小米汽车品牌资讯,与其他用户交流用车体验,分享精彩的车生活。站长网2024-03-25 12:35:100000抖音电商向卷低价、仅退款开刀
日趋激烈的竞争下,电商行业围绕商品力、价格力、服务力进行着全方位比拼,带来短期增长的同时,也催生出卷低价带来劣币驱逐良币,卷服务导致的仅退款被滥用,虚假营销带来的不公平竞争等情况。平台的「好初心」变成了「真问题」。恶性循环下,消费者的长期利益无法得到保障,商家的经营复杂度日渐提升,行业的健康发展也受到了很大影响。0000