一言不合就跑分,国内AI大模型为何沉迷于“刷榜”
“不服跑个分”这句话,相信关注手机圈的朋友一定不会感到陌生。诸如安兔兔、GeekBench等理论性能测试软件,由于能够在一定程度上反映手机的性能,因此备受玩家的关注。同理在PC处理器、显卡上,同样也有相应的跑分软件来衡量它们的性能。
既然“万物皆可跑分”,当下最热的AI大模型也开始玩起了跑分,特别是在“百模大战”打响后,更几乎是天天都有突破、各家的都宣称自己是“跑分第一”。
然而国产AI大模型虽然在跑分上几乎没有输过,可体验方面却从未赢过GPT-4。那么问题就来了,大促节点时各手机厂商总能拿到“销量第一”,靠的是不断增加定语,将市场细分再细分来让人人都有第一拿,可AI大模型领域就不太一样了,毕竟它们的评估基准基本是统一的,其中包括MMLU(用于衡量多任务语言理解能力)、Big-Bench(用于量化和外推LLMs的能力),以及AGIEval(用于评估应对人类级任务的能力)。
目前被国内厂商经常引用的大模型评测榜单是SuperCLUE、CMMLU和C-Eval,其中CMMLU和C-Eval是由清华大学、上海交通大学和爱丁堡大学合作构建的综合性考试评测集,CMMLU则是MBZUAI、上海交通大学、微软亚洲研究院共同推出,至于SuperCLUE,则是一帮各大高校的AI专业人士攥出来的。
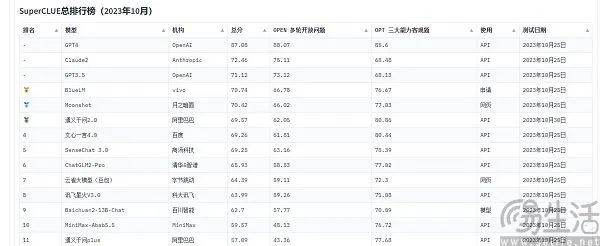
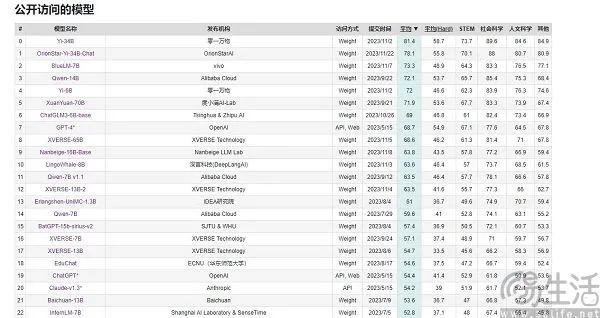
以C-Eval为例,在9月初的榜单上,云天励飞大模型 " 云天书 " 排在第一、360排第八,GPT-4却只能排在第十名。既然标准是可量化的,为什么会出现反直觉的结果呢?大模型跑分榜单之所以会呈现出“群魔乱舞”的景象,其实是目前评价AI大模型性能的方法有局限性,它们是用“做题”的方式来衡量大模型的能力。
众所周知,智能手机的SoC、电脑的CPU和显卡为了保护自身寿命,会在高温的情况下自动降频,反之低温则会使得芯片性能得到更好的发挥。因此将手机放进冰箱、或是为电脑配备更强悍的散热来跑分,通常就会得到一个比正常状态下更高的成绩。更别提针对各类跑分软件进行“专属优化”,也早就成为了各大手机厂商的标准操作。
同理,AI大模型的跑分既然是以做题为核心,自然就会有题库。没错,国内部分大模型在“刷榜”上一个赛一个的原因,就出现在了这里。由于种种原因,目前各大大模型榜单的题库几乎对厂商是单向透明,也就是出现了所谓的“基准泄露”。例如C-Eval榜单在上线之初就有13948道题目,并且由于题库有限,就出现过直接让某些不知名大模型用刷题的方式“通关”的情况。
大家不妨设想一下,如果在考试前机缘巧合看到了试卷和标准答案,突击背题的结果就是考试成绩会大幅度提高。所以将大模型榜单预设的题库加入训练集,这样一来大模型也就变成了拟合基准数据的模型,而且目前的LLM本身就以出色的记忆力著称,背标准答案简直就是小菜一碟。
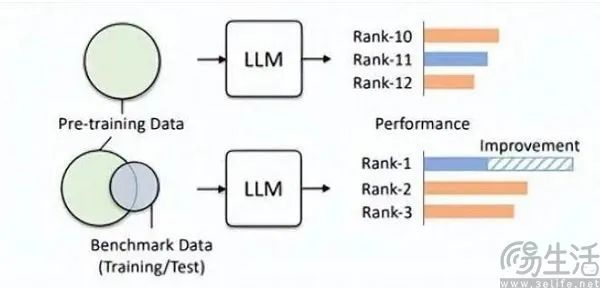
通过这一方式,小尺寸模型在跑分中也能拥有比大尺寸模型更好的结果,部分大模型取得的高分就是在这样的“微调”下实现。人大高瓴团队在论文《Don't Make Your LLM an Evaluation Benchmark Cheater》中,就直白地指明了此类现象,而且这种投机取巧的做法对于大模型的性能反而是有害的。
高瓴团队的研究人员发现,基准泄漏会导致大模型跑出夸张的成绩,例如1.3B的模型可以在某些任务上超越10倍体量的模型,但副作用就是这些专门为“应试”设计的大模型,在其他正常测试任务上的表现会受到不利影响。毕竟想想也能知道,AI大模型本来应该是“做题家”、却变成了“背题家”,为了获得某榜单的高分,去使用该榜单特定的知识和输出样式,肯定就会误导大模型。

训练集、验证集、测试集的不交叉显然只是理想状态,毕竟现实很骨感,数据泄露问题从根源上就几乎不可避免。随着相关技术的不断进步,当下大模型的基石Transformer结构的记忆和接收能力在不断提升,今年夏季微软研究院General AI的策略就已经实现了让模型接收1亿Tokens、而不会产生无法接受的遗忘。换而言之,未来AI大模型很有可能具有读取整个互联网的能力。
即使抛开技术进步,单纯以当下的技术水平,数据污染其实也难以规避,因为优质数据总归是稀缺、且产能有限的。AI研究团队Epoch在今年年初发表的论文就表明,AI不出5年就会把人类所有的高质量语料用光,而且这一结果是其将人类语言数据增长率,即全体人类未来5年内出版的书籍、撰稿的论文、编写的代码都考虑在内,所预测的结果。
一个优质的数据集如果适合作为评测用途,那么它肯定就同样在预训练上有更好的发挥,例如OpenAI的GPT-4就使用了权威推理评测集GSM8K的数据。所以这就目前大模型评测领域的尴尬之处,大模型对于数据的无止境需求导致了相关评测机构必须比AI大模型厂商跑得更快、更远,可如今评测机构却根本就没能力做到这一点。
至于说为什么某些厂商会在大模型跑分上格外上心,纷纷去操作刷榜呢?其实这一行为背后的逻辑,就与App开发者给自家App的用户量注水一模一样。毕竟App的用户规模是衡量其价值的关键要素,而在当下这个AI大模型的起步阶段,评测榜单的成绩几乎就是唯一一个相对客观的评判标尺,毕竟在大众的认知里跑分高就等于性能强。
当刷榜可能带来强烈的宣传效应,甚至可能会为融资打下基础的情况下,商业利益的加入就必然会驱使AI大模型厂商争先恐后去刷榜了。
6.4mm同档最轻薄!华为MatePad Air正式发布:2899元起
快科技5月18日消息,华为在今晚的夏季新品发布会上推出了全新平板。从名字中的Air”就能看出来,这款新品主打的是轻薄机身,整机厚度只有6.4mm,重量也仅有508g,是同档位最轻薄的产品,拿在手上非常轻巧,即便外出携带也不会太过负担。站长网2023-05-18 20:26:280000报道称小红书内测“笔记带货”功能
据Tech星球报道,小红书近期推出电商新功能“笔记带货”,商家可以利用KOL合作笔记带动电商交易。目前,该功能正在测试阶段,收到小红书定向邀请的核心商家才可以体验这一功能,后续“笔记带货”将全面开放。据悉,拥有“笔记带货”权限的商家,可以在平台内挑选达人进行挂链合作。同时,平台设立独立笔记带货选品中心,达人可以在发布笔记时直接关联商品,单篇笔记支持多品挂链接。站长网2023-05-05 16:40:580000通用汽车招聘高级驾驶辅助系统新任副总裁,并推出人工智能网站
通用汽车(GM)公司软件执行副总裁MikeAbbott表示,该公司已聘请Meta的AnanthaKancherla担任高级驾驶辅助系统新任副总裁。GM网站截图站长网2023-12-14 10:09:230000腾讯否认微信将推出公务员专供版:这玩笑开大了
最近有传言称,微信将推出“公务员专供版”,撤回时间将由原本的两分钟延长至两小时,部分领导的撤回时间甚至可延长至两天。7月18日,腾讯公关总监张军在朋友圈明确否认了这一传闻的真实性,并表示这只是一个玩笑。他调侃说:“还真有人信。”站长网2023-07-19 11:02:4500001000亿GMV下,在抖音做团购的商家
抖音这条鲶鱼,成功搅动了本地生活市场。据《晚点LatePost》报道,抖音生活服务上半年的支付交易总额超过了1000亿元。而在去年,抖音生活服务的全年交易额接近900亿元,来势汹汹的抖音,用半年时间就超过了去年一年的成绩。耀眼的交易额和超过7亿的日活用户,吸引到了众多线下商家。站长网2023-08-19 16:06:470000