AI视野:GPTs商店推迟至2024年发布;抖音AI扩图爆火;阿里推出AI动画生成框架;出门问问推出奇妙助手
【要闻速览】
GPTs商店推迟至2024年发布
OpenAI在中国申请GPT-6、GPT-7商标
抖音AI扩图爆火
谷歌推超快扩散模型MobileDiffusion
阿里推出AI动画生成框架
中国电信成立AI公司
AI视觉字谜爆火!梦露转180°秒变爱因斯坦
字节跳动与中科大联手提出多模态文档大模型DocPedia
哈工深发布多模态大模型九天
krea AI推出实时增强功能
Meta推出家庭机器人学习框架Dobb-E
出门问问推出奇妙助手
📰🤖📢AI新鲜事
GPTs商店推迟至2024年发布
OpenAI宣布将定制化GPT商店的发布时间推迟至2024年初,此举发生在公司首席执行官更迭、员工威胁罢工后,公司继续改进GPT以提高性能和功能。
【AiBase提要:】
🗓️ OpenAI推迟GPT商店发布至2024年初,发生在CEO更迭和员工威胁罢工后。
🔄 公司持续改进GPT,以满足用户反馈,计划让用户定制GPT并赚取收入。
🌐 推迟旨在为公司提供更多时间,确保GPT商店能提供高质量的定制体验。
OpenAI在中国申请GPT-6、GPT-7商标
OpenAI近日在中国积极申请GPT-6和GPT-7商标,显示其对全球人工智能行业的远见,同时展示GPT-4超过1万亿参数的强大性能,预示着GPT-6和GPT-7的创新。
【AiBase提要】
🚀 OpenAI在中国申请GPT-6和GPT-7商标,展现全球化视野,尽管未在中国提供服务。
💡 GPT-4参数超过1万亿,预示GPT-6和GPT-7将引领创新,商标审查仍在进行中。
👥 OpenAI首席执行官Sam Altman强调推动GPT-5研发,寻求微软额外资金,关注人工智能创新中的伦理问题。
中国电信成立AI公司
一家名为中电信人工智能科技有限公司的新公司成立,注册资本30亿元,由中国电信100%控股。该公司的经营范围包括人工智能理论与算法软件开发、基础软件开发、应用软件开发以及人工智能硬件销售。此举是中国电信在人工智能领域的重大举措,与其之前发布的千亿参数大模型星辰语义相关。
【AiBase提要:】
🚀 战略投资: 中国电信成立30亿元AI科技新公司,致力于人工智能理论、算法和应用软件的研发,以及人工智能硬件销售。
🌐 千亿参数大模型: 中国电信发布千亿参数大模型星辰语义,在幻觉抑制、外推窗口、交互体验和多轮理解方面取得显著提升。
🔍 多领域覆盖: 公司计划在未来开源百亿参数和千亿参数大模型,涵盖教育、医疗、旅游等多个行业。
GPT-4惊人表现:文字序列混乱不影响阅读理解
日本东京大学研究发现,GPT-4在处理文字序列乱序时表现出惊人的恢复能力,超越其他大型模型,不仅对乱序句子准确恢复,还展现出优异的分词能力。

论文地址:https://arxiv.org/abs/2311.18805
【AiBase提要:】
😲 研究发现GPT-4在处理乱序文字时表现出惊人的恢复能力,远超其他大型模型。
🧩 通过Scrambled Bench测试,GPT-4在极端情况下保持较高的恢复率和准确性,展现出强大的抗干扰能力。
🔤 GPT-4在分词方面的表现超越其他模型,即使对于连续英文文本的分词也令人惊讶。
抖音AI扩图火出圈 网友创作奇异有趣作品走红
一位博主在抖音上使用AI智能扩图生成的照片走红,引发近40万次点赞和5万多次转发。然而,随着更多网友使用AI智能扩图创作,一系列奇异有趣的作品涌现,展现了AI扩图的创意潜力。尽管取得关注,但也有作品凸显生成图像的不足之处,可能与训练和生成过程中的问题有关。需要注意AI智能扩图在生成图像真实性方面的局限性,未来随技术发展这些问题或有望解决。
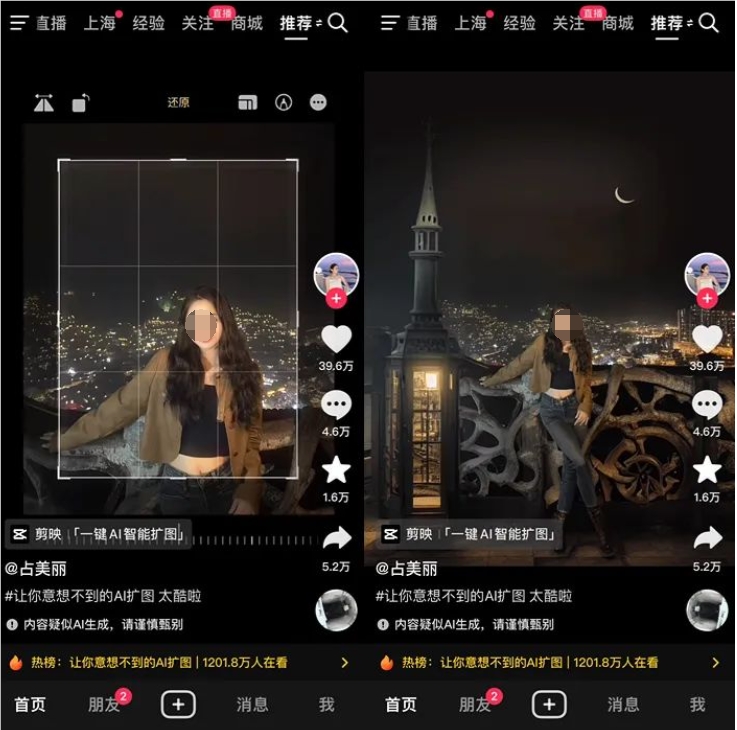
【AiBase提要】
😮 博主在抖音使用AI智能扩图创作走红,引发热潮。
😂 网友创作出奇异有趣作品,展现AI扩图的创意潜力。
🤔 一些作品凸显生成图像的不足,可能与训练和生成过程中的问题有关。
AI视觉字谜爆火!梦露转180°秒变爱因斯坦
最新扩散模型通过视错觉画实现AI绘制,倒转图像可变换主题,受网友热捧,英伟达高级AI科学家盛赞为近期最酷的模型。

论文地址:https://arxiv.org/pdf/2311.17919.pdf
【AiBase提要:】
🎨 扩散模型创新:AI绘制视错觉画,倒转图像即可变换主题。
💡 模型应用广泛:两组提示词随机生成各类画作,对象截然不同也能呈现。
🔬 技术原理深度解析:基于DeepFloyd IF的像素扩散模型,通过噪声平均实现图像变换,展现出多样的视觉效果。
🤖📈💻💡大模型动态
谷歌推超快扩散模型MobileDiffusion 手机上0.2秒出图
MobileDiffusion是谷歌打造的移动端扩散模型,实现了在iPhone15Pro上仅需0.2秒的文生成图速度。通过对UNet核心组件的精简和采样优化,提高了模型效率和参数剪切,为移动端应用提供了亚秒级的出图能力。

论文地址:https://arxiv.org/abs/2311.16567
【AiBase提要】:
🚀 速度突破: MobileDiffusion在移动端实现0.2秒出图,创下当前最快速度。
🔍 模型优化: 通过对UNet核心组件的精简和采样优化,提高了模型效率和参数剪切。
📱 移动应用保障: MobileDiffusion不仅在基准测试中表现出色,还在下游任务测试中展现了出色的微调能力。
字节跳动与中科大联手提出多模态文档大模型DocPedia
字节跳动与中国科学技术大学联手研发的多模态文档大模型DocPedia成功突破了分辨率极限,达到2560×2560的高分辨率,通过感知-理解联合训练策略和频域处理解决了现有模型在解析高分辨文档图像方面的不足。
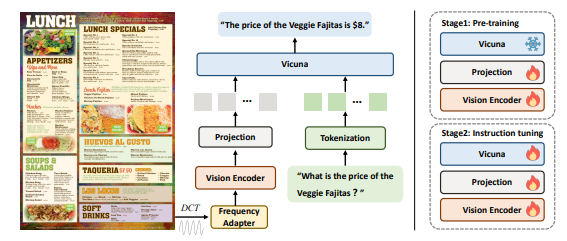
论文地址:https://arxiv.org/pdf/2311.11810.pdf
【AiBase提要:】
🚀 突破分辨率极限: 字节跳动与中科大合作的多模态文档大模型DocPedia成功达到2560×2560的高分辨率,明显超越现有先进模型。
🧠 强大多模态理解: DocPedia不仅准确识别图像信息,还能结合用户需求调用知识库回答问题,展现了强大的多模态文档理解能力。
🔄 训练关键策略: 通过感知-理解联合训练策略和频域处理解决分辨率问题,在微调阶段进行整体优化,显著提高了DocPedia的性能。
哈工深发布多模态大模型九天 性能提升5%
九天是哈尔滨工业大学发布的多模态大语言模型,通过融合细粒度空间感知和高层语义视觉知识,在13个视觉语言任务上实现state-of-the-art性能,尤其在Visual Spatial Reasoning任务上提升了5%。
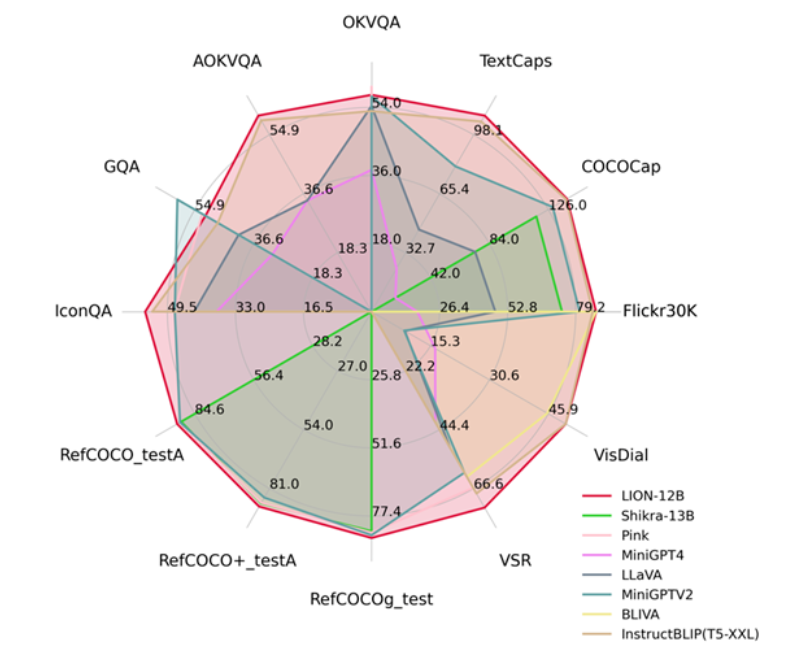
论文链接:https://arxiv.org/abs/2311.11860
GitHub:https://github.com/rshaojimmy/JiuTian
项目主页:https://rshaojimmy.github.io/Projects/JiuTian-LION
【AiBase提要:】
🚀 创新性方法: 九天模型采用双层视觉知识增强,通过渐进式融合细粒度空间感知和高层语义视觉证据,显著提升了视觉理解能力。
🌐 性能突破: 在13个视觉语言任务上取得state-of-the-art性能,尤其在Visual Spatial Reasoning任务上实现了5%的性能提升。
🔗 开源资源: 论文已发布于arXiv,项目代码和主页也在GitHub上公开,为多模态大语言模型领域提供新思路和强大支持。
Perplexity发布两款在线LLM模型
Perplexity AI推出的pplx-7b-online和pplx-70b-online是基于实时互联网数据的在线大语言模型,通过API公开访问,解决了离线模型无法提供即时、精确响应的问题,具备优越的新鲜度、真实性和整体偏好性能。
pplx-api:https://docs.perplexity.ai/docs/getting-started
使用Perplexity Labs免费试用在线模型:https://labs.perplexity.ai/
【AiBase提要】:
🚀 Perplexity AI发布两款在线大语言模型,pplx-7b-online和pplx-70b-online,通过实时互联网数据提供即时、精确响应。
🌐 与传统离线模型不同,这两款模型在新鲜度、真实性和整体偏好方面持续优于同类模型,开发者可通过API体验其独特功能。
📈 这一创新解决方案标志着人工智能驱动的信息检索系统的变革,开发者可通过Perplexity的API立即使用这些模型创建应用程序。
中科院提出全新多视图世界模型和自动驾驶世界模型Drive-WM
中科院自动化所的Drive-WM模型结合多视图世界模型,通过Diffusion模型生成逼真视频场景,为自动驾驶系统提供多视图预测和规划,显著提高安全性。
【AiBase提要:】
🌐 Drive-WM模型整合多视图世界模型,利用生成式世界模型的生成能力,为自动驾驶系统提供多视图预测和规划。
🚗 首次将世界模型与端到端规划结合,通过图像奖励函数全面评估,实现更安全、有效的规划。
📹 在面对Out-of-Distribution场景时,Drive-WM通过生成视频进行微调,提高规划器在复杂场景中的性能。
🤖📱💼AI应用
出门问问推出奇妙助手
奇妙元是出门问问的AI数字人视频创作平台,最近进行全面升级并推出奇妙助手。该功能能快速生成视频所需素材,包括高质量图片、智能文本生成、PPT文件解析等,为短视频创作者提供更多便利和创意可能性。
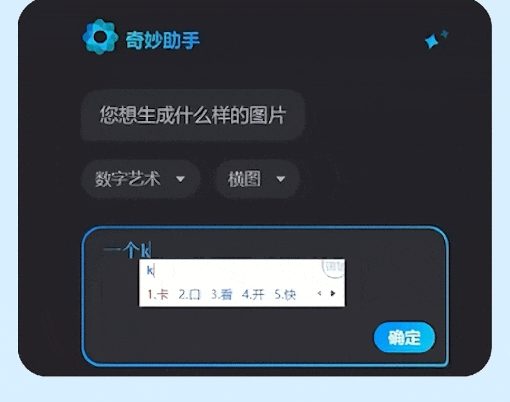
【AiBase提要:】
🌟 全面升级与新功能推出: 出门问问旗下奇妙元平台升级,并推出奇妙助手,为视频创作者提供丰富素材和智能文本生成功能。
🖼️ 多样化的素材选择: 奇妙助手内置了8种风格和3种尺寸比例的高质量图片,同时支持一键生成讲解视频、提取视频台词,准确率高达99%。
💡 数字人商店更新与创意拓展: 平台新增33 形象和海量剪辑模板素材,为短视频创作者提供更多创意可能性。
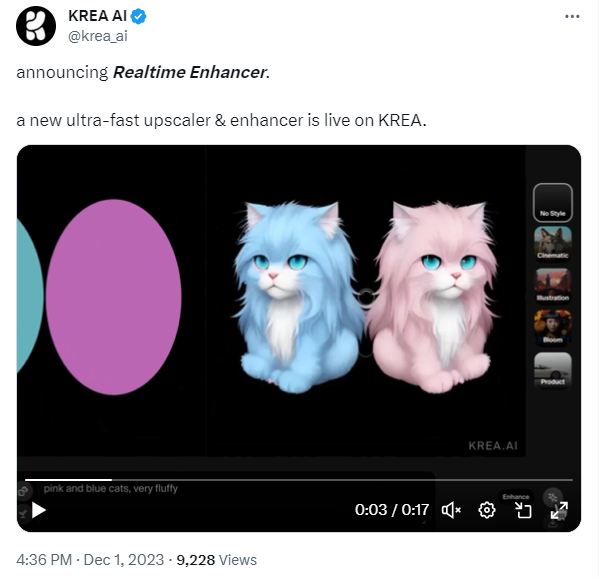
krea AI推出实时增强功能
krea AI发布实时增强功能,允许用户在绘制图像时进行实时放大,提高细节和分辨率,为设计领域带来更高效的创作体验。
【AiBase提要:】
💡 Krea AI实时增强功能支持绘制图像实时放大,提高细节和分辨率,为设计师提供更便捷的创作体验。
🚀 强大的实时生成功能让用户轻松切换多种风格,即使是缺乏绘画基础的用户也能轻松创建精致图像。
🔄 Krea AI不仅支持画板上的创作,还能接入电脑桌面和摄像头画面,为设计师提供更广泛的创作空间。
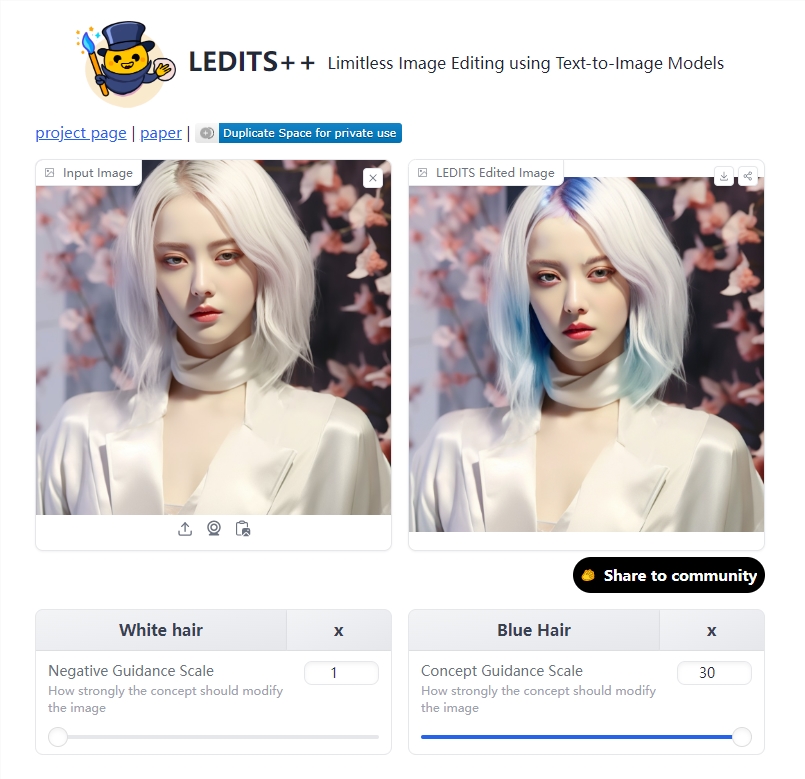
LEDITS :根据文字编辑图像 可对画面进行删除修改
LEDITS 项目通过文本提取概念,以惊人效果编辑图像,具备灵活性、语义基础编辑、通用性,成为图像编辑领域的革命性工具。
试玩地址:https://huggingface.co/spaces/editing-images/leditsplusplus
【AiBase提要】
💡 技术原理与灵活性: LEDITS 基于友好噪声空间的特征推导,以出色的输入重建能力,通过20个扩散步骤实现编辑,展现强大的通用性。
🎨 注重语义基础的编辑艺术: LEDITS 设计强调提升编辑的视觉和上下文连贯性,保持图像自然流畅,提供高水平编辑精度。
🔄 多功能编辑与通用兼容性: LEDITS 不仅是图像编辑工具,更是注重语义基础的编辑艺术,与任何扩散模型兼容,为用户提供广泛适用、高效的图像编辑工具。
👨💻💡🎯聚焦开发者
阿里推出AI动画生成框架
阿里近日推出了名为"Animate Anyone"的视频生成技术,通过引入扩散模型解决图像到视频合成的挑战,特别在角色动画领域。论文详细介绍了创新框架的关键组成部分,包括ReferenceNet、姿势引导器和时间建模方法。该技术不仅在人物角色动画生成领域表现出色,还在时尚视频合成和人类舞蹈生成等多个领域取得了最先进水平。

论文地址:https://humanaigc.github.io/animate-anyone/
【AiBase提要:】
🚀 创新框架设计: "Animate Anyone"引入巧妙设计的ReferenceNet、姿势引导器和时间建模方法,解决图像到视频合成中的细节一致性和运动连贯性问题。
🤖 关键技术组合: 通过姿势引导器、去噪UNet、空间注意力等计算块,结合ReferenceNet和CLIP图像编码器,实现对复杂特征的准确捕捉和生成。
🌐 多领域应用: 经过扩展训练数据,该技术不仅在人物角色动画生成方面卓有成效,还在时尚视频合成和人类舞蹈生成等领域展现出色,达到了最先进水平。
SceneTex: 生成高质量、风格一致的室内场景纹理的新型AI方法
近日,慕尼黑工业大学和Snap Research联合提出的SceneTex是一项新型AI方法,通过深度到图像扩散先验,采用多分辨率纹理和交叉注意力解码器,在室内场景中生成高质量、风格一致的纹理,为自动驾驶、机器人模拟、游戏、电影等多领域提供关键支持。通过创新性应用深度到图像扩散先验,SceneTex成功实现了室内场景的高质量、风格一致的纹理生成,为未来3D内容生成和应用提供了新的方向。

项目网址:https://daveredrum.github.io/SceneTex/
【AiBase提要:】
🌐 关键问题解决: SceneTex采用深度到图像扩散先验,在室内场景中实现高质量、风格一致的3D内容合成,解决了传统方法中的多个问题。
🤖 技术创新: 利用多分辨率纹理和交叉注意力解码器,SceneTex实现了全局样式一致性,提高了室内场景的纹理生成质量。
🚀 实际应用验证: SceneTex在3DFRONT数据集上的用户研究表明,在2D指标方面优于其他基于文本的纹理创建算法,为未来3D内容生成开辟了新的方向。
Meta推出家庭机器人学习框架Dobb-E
纽约大学和Meta合作推出的Dobb-E是一款高度适应性的开源机器人学习框架,通过从用户演示学习,成功率达到81%,在解决家庭环境中机器人操作学习的挑战方面取得显著成功。
项目网址:https://dobb-e.com/
论文网址:https://arxiv.org/abs/2311.16098
【AiBase提要:】
🚀 高度适应性系统: Dobb-E能够从用户演示中学习和适应,成功率达到81%。
🏡 独特家庭数据集: 利用iPhone功能构建的家庭和第一人称机器人交互数据集,突显在真实环境中的高效性。
💡 简单而强大的方法: Dobb-E的成功归功于包括行为克隆和两层神经网络用于动作预测在内的简单而强大的方法。
OPPO发布1+N智能体生态战略 包括AI超级智能体、AI Pro开发平台
OPPO于今日在东莞的OPPOAI滨海湾数据中心举行了盛大的AI战略发布会,此次发布会标志着OPPO正式进入AI手机时代。此前,OPPO已在2月9日宣布向超千万用户推送ColorOSAI新春版,其首席产品官刘作虎亦宣布了OPPO在AI领域的战略布局。站长网2024-02-20 15:36:330000华为畅享60 Pro将于5月18日发布
华为宣布,将在5月18日举行夏季全场景新品发布会,并发布畅享60Pro。据悉该手机采用了直屏设计,后置摄像头采用了“双环”设计,正面则配备了一块中置挖孔屏。此外,华为还将在发布会上一同发布全新华为WATCH4、华为MatePad、华为MateBook等系列。站长网2023-05-15 15:14:030000数据显示:Linux 桌面用户占比份额首次超过 3%
根据Statcounter的数据显示,Linux在桌面用户中的份额首次超过了3%。虽然这个数据可能会有所出入,但从他们的统计趋势来看,Linux的使用率在过去几年里一直在缓慢上升。这个数据并不包括基于Linux的ChromeOS,因为他们单独跟踪了该系统的数据,这个统计仅涵盖了桌面Linux系统。今年以来统计数据显示Linux的份额变化如下:1月-2.91%站长网2023-07-12 16:23:450000










