MIT斯坦福Transformer最新研究:过度训练会让中度模型“结构顿悟”
要点:
经过过度训练,中度模型如Transformer表现出结构性泛化能力,被称为"结构顿悟"(Structural Grokking)。
研究发现,对于Transformer类模型,长时间训练后,模型在泛化到新结构输入时能够有效地捕捉到句子的层级结构。
结果显示,模型的深度对结构顿悟呈倒U形缩放,中深度模型的泛化能力较深度和浅度模型更强。
最新研究指出,经过过度训练,中度的Transformer模型能够展现出结构性泛化能力,这一现象被称为"结构顿悟"。在自然语言处理中,先前的研究认为像Transformer这样的神经序列模型在泛化到新的结构输入时难以有效地捕捉句子的层级结构。

论文地址:https://arxiv.org/pdf/2305.18741.pdf
然而,斯坦福和MIT的研究人员发现,通过对Transformer类模型进行长时间的训练,模型能够获得这种结构性的泛化能力。他们将这一现象命名为"结构顿悟",形容为神经网络经历了一个"aha moment",在训练的某一刻忽然实现了对层级结构的理解。这种现象的发生被证明在不同数据集上呈现出倒U形的深度缩放,中深度模型的泛化能力表现最佳。
研究进一步指出,提前停止训练会导致泛化性能被低估,而中度深度的Transformer模型在泛化到新结构输入时呈现出显著的优势。研究还分析了结构顿悟的内部属性,包括参数权重的L2norm、注意力稀疏性和模型的树结构性。结果显示,中度深度模型在这些属性上表现出最佳的结构顿悟,而权重范数和注意力稀疏性的动态变化与模型的泛化性能密切相关。
这项研究为理解神经序列模型的泛化机制提供了新的视角。通过揭示结构顿悟的存在,研究强调了模型深度与泛化性能之间的关系,并为改善自然语言处理模型的泛化能力提供了有价值的启示。这一发现有望在未来的深度学习研究中引起更多关注,为模型设计和训练策略提供指导。
马斯克:特斯拉目标年产200万辆Cybercab无人驾驶出租车
特斯拉今日发布了2024年第三季度的财报,数据显示该季度营收达到251.8亿美元,净利润为25.05亿美元,同比增长8%。在随后的财报电话会议上,特斯拉首席执行官马斯克透露了公司的未来计划,包括在2025年上半年交付更多经济型汽车,并预计明年的销售增长率将在20%到30%之间。0000Persistent 与 Google Cloud 合作推出生成式 AI 解决方案
站长之家(ChinaZ.com)8月1日消息:Persistent宣布加强与谷歌云的合作伙伴关系,推出了一套由谷歌云驱动的生成式人工智能解决方案。这些解决方案将为客户提供帮助,让他们在AI的旅程中,从AI探索者到生成式AI颠覆者,通过理解如何成功地识别和实施这些先进技术,使其业务具备规模。站长网2023-08-01 10:43:360000分享榨果汁,竟然卖了50W单。
各位村民好,我是村长。今天要来分享一个水果榨汁杯账号,每天分享用各种水果、蔬菜、坚果等食材来榨果汁,最终竟然卖了50多万单,把一款榨汁机带成了爆款。我们一起来看看这个账号做对了什么,又有什么地方需要完善的。01单一产品精准定位这是一个单品账号,几乎所有的视频都在分享用榨汁机榨果汁。一方面对于博主本人来说,可以集中精力做内容,不想去想其他产品的创意。站长网2023-08-30 09:07:350000女子注销号码未解绑网盘致照片泄露 客服回应:建议开启登录保护
10月12日,广州的伍女士表示,她注销的手机号未在百度网盘解绑,导致新号主能够登录她的账户,查看包括照片、隐私信息及通讯录在内的敏感数据,并且对她进行了多次骚扰。对于账号被他人登录的问题,客服建议,如果用户发现非本人登录记录,可以查看详情并踢出其他设备的登录状态。同时,为了账号安全,用户可以开启登录保护,这样在异地或通过网页登录时会需要进行身份验证。0000挑战OpenAI!Claude 2.1 LLM长下文窗口可达200K
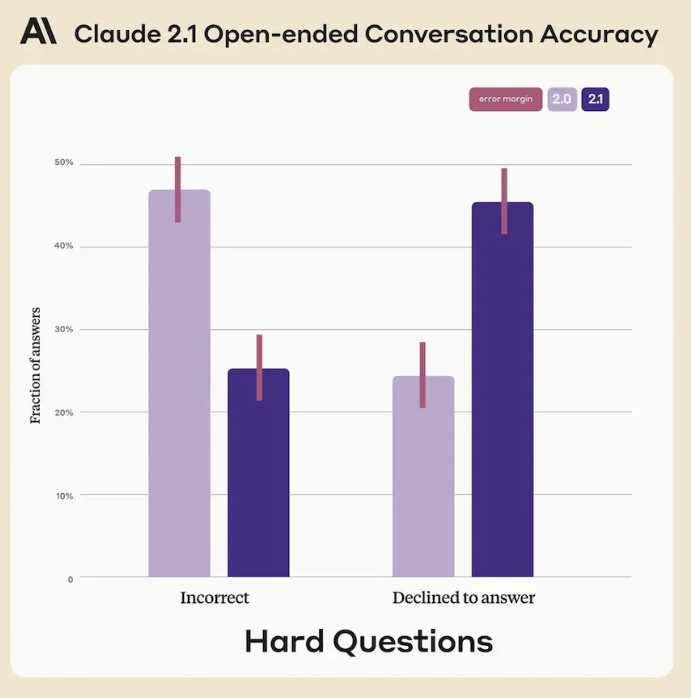
Anthropic最新发布的大型语言模型Claude2.1LLM引起了广泛关注,该模型的上下文窗口长度可达200K,是对当前市场主流模型的一次重要突破。这一消息是在OpenAI推出128K上下文窗口的GPT-4之后发布的,导致超过100个企业OpenAI用户周末纷纷向Anthropic寻求支持,以解决对LLM提供商的过度依赖问题。站长网2023-11-22 10:44:090000