Meta开源最新模型——Llama Guard-7b
全球社交、科技巨头Meta在官网开源了全新模型——Llama Guard。
据悉,Llama Guard是一个基于Llama2-7b的输入、输出保护模型,可对人机会话过程中的提问和回复进行分类,以判断其是否存在风险。可与Llama2等模型一起使用,极大提升其安全性。
Llama Guard也是Meta推出的“Purple Llama”安全评估项目中,输入、输出保障环节的重要组成部分,这也是首个在输入输出防护中区分用户与AI风险的模型。
Llama Guard地址:https://huggingface.co/meta-llama/LlamaGuard-7b
Purple Llama地址:https://github.com/facebookresearch/PurpleLlama
论文地址:https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/
Llama Guard简单介绍
研究人员设计了一个包含法律和政策风险的安全风险分类体系。分类体系包含6大类可能的安全风险:暴力与仇恨、色情内容、非法武器、犯罪计划等。
此外还详细说明了每个风险类别中的易犯错误。
通过使用Anthropic提供的人机对话数据集,对数据进行标记。标记内容包括对话提问与回应中的风险类别及是否存在安全隐患。最终收集了近14000条标注好的对话样本。
再以Llama2-7b作为基础模型,采用指令式学习框架进行训练。此框架将分类任务表述为一个接一个的指令任务。
使Llama Guard根据输入指令和数据学习进行多类分类。研究人员为用户提问和机器回复分别编写指令,实现对其语义结构的区分。
还采取数据增强方法,强化模型只考虑给定输入中的分类信息。
测试数据
首先在内部测试集上进行验证,Llama Guard在整体和每个单独分类上的表现都超过了其他内容监管工具。
然后,研究人员采用零样本和少量实例学习的方法,将Llama Guard迁移到其他公开测试集上进行验证。
测试结果显示,在ToxicChat数据集上,Llama Guar的平均准确率高于所有基线方法;在OpenAI评估数据集上,Llama Guard在零样本的情况下与OpenAI内容监管API表现相当。
此外,Llama Guard使用了指令调优,可以适配不同的AI分类法或政策。用户可以通过零样本或小样本的方式便可实现指令迁移,以适配不同的应用场景需求。
AI视野:自定义ChatGPT商店下周上线;小冰克隆人正式上线;美图大模型上线;普林斯顿大学提出GEO;英伟达发布文生图模型TrailBlazer
新鲜AI产品点击了解:https://top.aibase.com/📰🤖📢AI新鲜事自定义ChatGPT商店下周上线OpenAI宣布将上线自定义GPT商店,用户可以将自己开发的自定义ChatGPT助手进行分享的平台。这一商店的功能类似于苹果的AppStore,在大模型领域提供了新的商业机会。【AiBase提要:】站长网2024-01-05 15:53:510000荣耀MagicBook Art官宣定档7月12日:轻薄刷新行业纪录
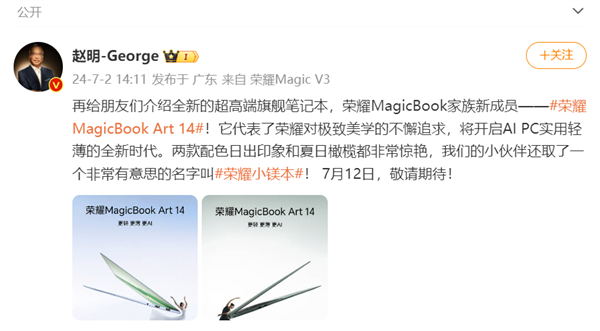
站长之家(ChinaZ.com)7月2日消息:荣耀今日正式宣布,荣耀Magic旗舰新品发布会将震撼登场,其中最为瞩目的莫过于荣耀MagicBookArt14笔记本旗舰新品。这款被内部亲切称为“荣耀小镁本”的杰作,不仅以其不足980克的极致轻盈,成功超越华为MateBookXPro,更一举刷新了PC轻薄领域的行业纪录,宣告了荣耀对极致美学与便携性的不懈追求。站长网2024-07-02 18:04:570000微软与美国劳工联合会 AFL-CIO 达成中立协议,共同探索人工智能的未来
站长之家(ChinaZ.com)12月12日消息:微软公司和美国劳工联合会(AFL-CIO)于当地时间周一宣布,他们达成了一项协议,这家美国软件巨头将在工会鼓励工人成为成员的努力中保持中立。此外,双方还将共同研究人工智能的未来,这是商业和劳工界在应对该技术影响时,首次就AI和劳动力的未来建立的合作伙伴关系。0000Meta推大模型记忆增强方法MemWalker 靠prompt就能完成,无需额外训练
要点:1.研究团队开发了名为MemWalker的树形记忆策略,使大型语言模型能够突破窗口长度限制,实现长文本的阅读和回答问题,而无需额外训练。2.MemWalker的工作原理分为记忆树构建和导航检索两个阶段,其中长文本被分割成小段,大模型对每段进行总结形成"叶子节点"和"非叶节点",非叶节点用于定位答案,叶子节点用于推理答案。站长网2023-10-25 12:56:330001抖音:打击利用虚假人设将用户引流至第三方平台变现行为
抖音发布《关于虚假人设的治理公告》称,近期平台发现,有少数“自媒体”策划虚假人设,在个人简介和发布内容中,自称为名企高管、专家或者自封不可查证的“大师”,以夸张或虚假的身份,博取用户信任,进而将用户引流至第三方平台变现。站长网2024-07-23 10:25:270001