阿里出品!DreaMoving:图片+文字提示就能生成高质量舞蹈视频
**划重点:**
1. 🌐 **框架介绍:** DreaMoving是一种基于扩散模型的可控视频生成框架,基于图文就能制作高质量定制的人类跳舞视频视频。
2. 🔄 **架构解析:** 文中提出了Video ControlNet和Content Guider两大关键组件,分别负责运动控制和身份保留,可适用于各种风格化的扩散模型。
3. 🎬 **成果展示:** DreaMoving通过姿势序列和简单的内容描述,如文本和参考图像,生成高质量、高保真度的定制视频。
DreaMoving由阿里巴巴集团的一组研究人员倾力打造,一种基于扩散模型的可控视频生成框架,。该框架的核心目标基于图文就能生成高质量、定制化的人类舞蹈视频。
DreaMoving以其出色的扩散模型为基础,能够根据人物的身份和姿势序列生成目标身份在任何地方跳舞的视频。
DreaMoving 可以生成高质量和高保真度的视频,给定指导序列和简单的内容描述,例如文本和参考图像作为输入。具体来说,DreaMoving 通过人脸参考图像、通过姿势序列进行精确运动操作以及由指定文本提示提示的综合视频外观控制来展示身份控制的熟练程度。
比如你“投喂”一张人像,以及一段prompt就能生成对应的视频,而且改变prompt,人物背景和身上的衣服也会跟着变化。
为实现这一目标,该技术引入了Video ControlNet和Content Guider两个关键组件。
Video ControlNet:这是一个图像ControlNet,通过在每个U-Net块后注入运动块,处理控制序列(姿势或深度)以产生额外的时间残差。这有效实现了对运动的控制。
Content Guider:该组件负责将输入文本提示和外观表达,如人脸(衣物是可选的),转换为内容嵌入,实现跨注意力的传递。

值得一提的是,目前DreaMoving项目并没有开源代码。点击前往DreaMoving官网体验入口
项目网址:https://dreamoving.github.io/dreamoving/
论文网址:https://arxiv.org/abs/2312.05107
 正在请求数据,请稍候!
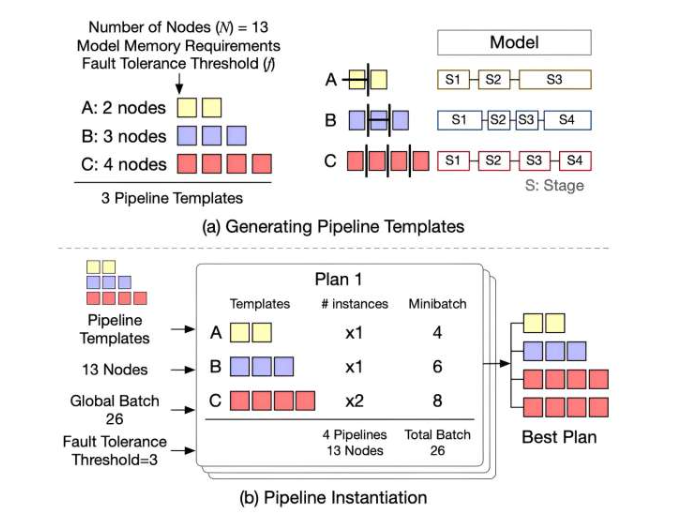
正在请求数据,请稍候!研究团队开发开源大模型训练框架 Oobleck 提供快速且有保障的故障修复
要点:密歇根大学的研究团队开发了一种名为Oobleck的开源大型模型训练框架,利用管道模板的概念,提供了快速而有保障的故障恢复,避免训练吞吐量下降。Oobleck的设计核心是管道模板,这是针对给定节点数量的训练管道执行的规范,用于实例化管道副本。这些模板在逻辑上等效(可以一起用于训练相同的模型),但在物理上是异构的(使用不同数量的节点),从而在保障容错性的同时提供高吞吐量和快速恢复。站长网2023-12-19 18:57:280008日本音乐作家团体联盟 FCA 呼吁保护创作者权益:推进 AI 技术和谐共存
FCA是由13个音乐作家团体组成的日本唯一的音乐作家团体联合组织。该组织于6月15日代表音乐作家发表意见,就生成AI使用著作物的问题提出了看法。该组织认为,在生成AI技术不断进步的当下,关于创作者权利保证的讨论仍被搁置,法制和社会制度并未跟上AI技术的进步,因此该组织要求政府重新审视现行的著作权法的权利限制规定,达到在推进AI技术发展的同时与创作者权利保护和谐共存的目的。站长网2023-06-16 14:38:580000创造新纪录,他们打响抖音电商“双11”第一枪
“有多少人是冲着胶原棒来到直播间的?”“今天下午3点,我们已经打破了次抛的吉尼斯世界销售记录!”“从它默默无闻,到现在大火,我一直在推荐,感谢品牌今天愿意给我地板价。”10月29日,抖音电商作者@搭搭进行了一场长达12小时的可复美专场带货直播,在众多用户和吉尼斯官方的见证下,成功打破次抛销量的世界纪录。搭搭只是众多勤奋经营、在抖音电商“双11”期间收获优异成绩的电商主播之一。站长网2023-10-31 18:19:480000马斯克:正在撰写史诗般的特斯拉“秘密宏图”第四篇章
快科技6月18日消息,埃隆马斯克最近在其社交账号上宣布,他正在撰写特斯拉秘密宏图”的第四篇章,这引起了广泛关注。自2006年首次公布其宏大计划以来,马斯克已成功引领特斯拉实现了多个关键目标。第一篇章(2006年):创建高性能电动跑车:Roadster的推出标志着特斯拉的诞生。利用跑车利润开发平价电动汽车:ModelS上市。站长网2024-06-18 20:40:310000首相苏纳克:英国必须抓住人工智能的机遇 才能保持科技之都的地位
英国首相里希·苏纳克将在周一对科技领袖发表讲话,敦促他们抓住人工智能的机遇和挑战,英国必须迅速行动以保持科技中心地位。站长网2023-06-12 16:57:400000