作者指控 Meta 不顾自己律师的警告,将受版权保护的书籍用于人工智能训练
Meta 在一起夏季提起的版权侵权诉讼中的最新提交文件显示,尽管律师警告使用数千本盗版书籍训练其 AI 模型的法律风险,该公司仍然这样做了。
周一晚间提交的新文件整合了针对 Facebook 和 Instagram 所有者的两起诉讼,由喜剧演员 Sarah Silverman、普利策奖得主 Michael Chabon 以及其他著名作者提起。他们指控 Meta 未经许可使用他们的作品训练其人工智能语言模型 Llama。
上个月,加州法官驳回了 Silverman 诉讼的一部分,并表示将允许作者修改他们的指控。Meta 尚未对这些指控作出回应。
周一提交的新起诉包括 Meta 关联研究员在 Discord 服务器上讨论数据集采购的聊天记录,这可能是一个重要证据,表明 Meta 知道其使用这些书籍可能不受美国版权法保护。
在起诉中引用的聊天记录中,研究员 Tim Dettmers 描述了他与 Meta 法律部门就使用书籍文件作为训练数据是否「合法」进行的讨论。
Dettmers 在 2021 年写道,他提到 Meta 承认用来训练 Llama 第一版的一个数据集「The Pile」,「在 Facebook,有很多人有兴趣使用 (The Pile),包括我自己,但以其当前形式,我们因法律原因无法使用它。」
根据起诉,Dettmers 在前一个月写道,Meta 的律师告诉他「如果数据被用来训练模型或发布,则不能使用该数据」。
尽管 Dettmers 没有详细描述律师的担忧,但聊天中的其他人指出,「仍在享有版权的书籍」可能是最大的担忧来源。他们表示,对数据的训练应该「属于合理使用范畴」,这是一种保护版权作品某些未经许可使用的美国法律原则。Dettmers 表示,他目前无法立即对这些指控发表评论。
今年,科技公司面临了一系列来自内容创作者的诉讼,他们指控这些公司剽窃受版权保护的作品,以构建在全球引起轰动并引发投资热潮的生成型 AI 模型。
如果这些案件成功,可能会抑制生成型 AI 的热潮,因为它们可能会通过迫使 AI 公司补偿艺术家、作者和其他内容创作者使用其作品而提高构建数据密集型模型的成本。
同时,欧洲新的临时人工智能法规可能会迫使公司披露用于训练模型的数据,从而可能使它们面临更多法律风险。
Meta 在 2 月发布了其 Llama 大型语言模型的第一个版本,并公布了用于训练的数据集列表,包括「ThePile」的 Books3 部分。根据起诉,组建该数据集的人称其包含 196,640 本书。
该公司并未透露其最新版本模型 Llama 2 的训练数据,该模型已于今年夏天投入商业使用。
Llama 2 对月活跃用户少于 7 亿的公司免费使用。其发布在科技领域被视为生成型 AI 软件市场的潜在游戏规则改变者,威胁到像 OpenAI 和 Google 这样的主导者,后者对其模型的使用收费。
School AI:为每个学生创建自己的聊天机器人
圣地亚哥的托勒小学正在试行一项名为SchoolAI的创新计划,为每个学生提供一个定制的聊天机器人作为个人人工智能学习助手。SchoolAI旨在为学生打造个性化的学习体验,激发他们的好奇心和积极性。站长网2024-04-19 12:15:150000MIT惊人再证大语言模型是世界模型!LLM能分清真理和谎言,还能被人类洗脑
【新智元导读】MIT等学者的「世界模型」第二弹来了!这次,他们证明了LLM能够分清真话和假话,而通过「脑神经手术」,人类甚至还能给LLM打上思想钢印,改变它的信念。大语言模型是世界模型,又添新证据!前不久,MIT和东北大学的两位学者发现,在大语言模型内部有一个世界模型,能够理解空间和时间。最近他们又有了新发现,LLM还可以区分语句的真假!站长网2023-10-20 18:19:070001在抖音只卖桶装面,销量100万单!
各位村民好,我是村长。一个只卖桶装面食的账号,拍了960多个视频,涨粉80万、销量100万。今天和大家分享的这个账号很有意思,对于大家做抖音带货账号特别有启发。01受众广方便面、粉丝、米线等产品,作为大众产品有许多受众。其一、从几岁的小孩到七八十岁的老人,都会消费。其二、这种产品不仅是外出工作时食用,同样在日常生活、娱乐中也都会食用。站长网2023-06-03 16:23:220000大模型生成提速2倍!单GPU几小时搞定微调,北大数院校友共同一作丨开源
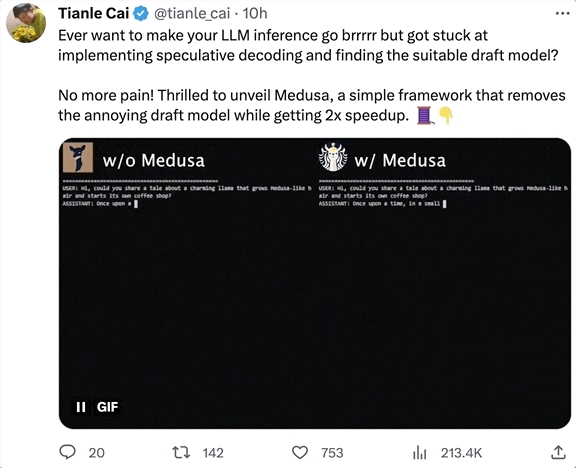
只需给大模型“加点小零件”,推理速度立刻提升2倍!不需要额外训练一个模型,也不需要对计算硬件做优化,单张A100最快几小时就能微调完成。这项新研究名叫Medusa(美杜莎),来自普林斯顿、UIUC、CMU和康涅狄格大学,FlashAttention作者TriDao也在其中。目前,它已经成功部署到伯克利70亿参数的“骆马”Vicuna中,后续还会支持其他大模型,已经登上GitHub热榜:站长网2023-09-18 09:05:520000视频重绘工具DomoAI 不用SD视频一键就能转动漫
要点:DomoAI是一款免费的人工智能艺术生成器,通过预设模型和简便操作,加速用户创作过程,提供高质量的视觉效果。DomoAI提供多样化的预设人工智能模型,帮助用户轻松实现在所有项目中保持一致而统一的绘画风格。DomoAI承诺在20秒内将文本转化为艺术品,从动漫梦境到现实奇观,快速实现创意想法。站长网2023-12-15 10:20:190004