用2D图像补全3D场景,谷歌发布NeRFiller
在许多3D场景捕获中,由于网格重建失败或者缺乏观测,例如,物体接触区域或难以触及的区域,场景中的某些部分经常会出现缺失的情况。
谷歌和加州大学伯克利分校的研究人员提出了NeRFiller框架,可通过2D图像来修复残缺的3D场景,同时发现当图像形成2x2网格时,会生成更多3D一致性的修复效果。
测试数据显示,研究人员通过多个评估指标对比原始数据与重建效果,如PSNR、SSIM等。同时记录不同数据集每个迭代循环耗时,发现NeRFiller重建的效果更出色,并将重建效率提升了10倍左右。
即将开源地址:https://github.com/ethanweber/nerfiller
论文:https://arxiv.org/abs/2312.04560

通常3D修复目标是完成一个包含缺失区域场景,例如,由多视图重建方法获得的场景,其中可能存在由于网格重建失败导致的“空洞”。NeRFiller则是要填充这些缺失区域,生成一个完整的3D场景。
所以,NeRFiller的整体修复思路主要分为两大块:使用联合多视角图像补全一致性的3D模型,以及通过对3D场景表示的迭代优化,将这些2D图像补全整合到全局一致的3D场景中。
联合多视角图像补全
使用独立的2D补全模型进行多视角图像的补全存在一致性问题,因此NeRFiller提出了网格先验和联合多视角补全两种策略,来提高一致性。
1)网格先验
研究人员发现,将四幅图像缩放到较低分辨率后以2x2网格形状提供给补全模型,可以获得更加一致的补全结果。可能这是由于在补全模型的训练数据中,存在很多视图示例。
方法是将4幅图像的潜在表示缩放到1/4分辨率,拼接成2x2网格后提供给扩散模型,对网格进行联合预测和采样。
最后再还原到原分辨率。这与最近的视频编辑方法使用的延长注意力机制有相似之处。
2)联合多视角补全
直接将大量图像制作成网格会降低分辨率。为了保持分辨率,NeRFiller使用了一种将网格先验推广到任意数量图像的策略。
该策略类似于MultiDiffusion的方法,每次迭代时随机将图像分组到2x2网格中,重复多次后对每个图像的噪声预测进行平均。这样可以在不降低分辨率的情况下增加有效的网格大小。
3D场景重建
上述的联合多视角图像补全,还无法更好的保证3D场景一致性。所以,NeRFiller使用了一种将2D补全结果整合到3D场景表示的迭代方法。整体流程如下:

渲染训练视角子集;
对渲染图像添加噪声,进行联合多视角补全;
用补全结果更新训练数据集中对应图像。
不断重复该流程,直到重建结果达到目标。此外,为了优化3D场景的几何形态,NeRFiller在室内场景中可加入了相对深度的监督,补全后预测深度,只对补全区域施加排序损失。
本文素材来源NeRFiller论文,如有侵权请联系删除
特斯拉Cybertruck北美正式交付 售价60990美元起
今日,特斯拉在得克萨斯州举办交付活动,正式将首批Cybertruck电动皮卡交到了消费者手中,起售价为60990美元。特斯拉配置页面显示了三种不同版本的Cybertruck,:后驱、四驱和Cyberbeast。后驱版本的预计售价为60,990美元,预计续航里程为250英里,0-60英里/小时加速时间为6.5秒。站长网2023-12-01 08:41:210000ChatExcel AI 办公辅助工具:通过文字聊天操控 Excel 表格
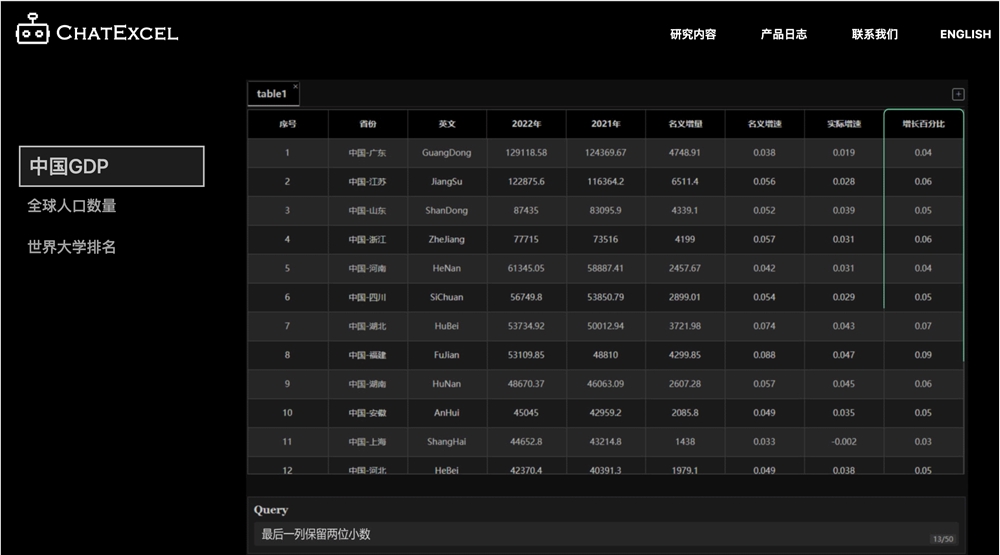
站长之家(ChinaZ.com)4月19日消息:最近,一支团队在北京大学深圳研究生院信息工程学院研发出了一款名为ChatExcel的AI办公辅助工具。站长网2023-04-19 10:10:450000微信:从严治理卖惨诱导打赏、虚假贫困摆拍等行为
微信发布《关于加强网络不良信息治理的公告》称,为进一步规范自媒体行为,平台持续对各类网络不良信息开展深入治理。平台针对散布虚假谣言信息,卖惨诱导打赏,虚假贫困摆拍等行为进行从严治理,并进一步加强对宣扬鼓吹“丧文化”和散布不良价值观等内容的治理。站长网2023-06-09 20:57:080000还充电焦虑吗?今年全国充电桩暴增243.2万台 累计达764.2万台
快科技10月11日消息,中国充电联盟公布了2023年9月全国电动汽车充换电基础设施运行情况。数据显示,2023年1-9月,充电基础设施增量为243.2万台,新能源汽车销量627.8万辆,桩车增量比为1:2.6,充电基础设施建设能够基本满足新能源汽车的快速发展。0000麒麟影像之王!华为Pura 80 Ultra堆料前所未有 全新自研技术落地
快科技1月5日消息,进入2025年后,一大波超大杯影像旗舰将陆续登场,其中,最受关注的自然是华为Pura80Ultra。日前,数码博主数码闲聊站”爆料称,华为Pura80Ultra不仅拥有前所未有的豪华硬件堆料,还搭载了不少自研的新技术。不过,该机发布进度要稍晚于其他厂商,今年的影像之王”归属依然充满悬念。站长网2025-01-05 10:07:450002