以搜索增强对抗幻觉,百川智能拿出了实现大模型商业化的最后一块拼图
12月19日,百川智能宣布开放基于搜索增强的Baichuan2-Turbo系列API,包含Baichuan2-Turbo-192K及Baichuan2-Turbo。这是9月末Baichuan2-53B第一次向外界打开API之后,百川智能在B端的进一步动作。
7月,以搜狗CMO身份加入这家大模型创业公司的洪涛,第一次与王小川同时出现在自己商业化产品的发布现场。这家在7月刚迈过100人的公司,现在快到200人规模。
百川智能在B端的布局正在提速,搜索能力融入更深,并且具备长文本能力的Baichuan2-Turbo API比起前者有了更多的现实意义。
金融、医疗等一些行业与大模型的需求已经开始形成。统计显示目前国内超过超过230款的大模型群落里,有15%是服务于金融领域的。
洪涛与客户接触下来的体验是,B端经常会遇到有客户不知道大模型能做什么的情况,或者想象力大到超过了大模型的能力范围。
这本身是大模型自己的问题,它看起来有讨论问题的能力,很多时候却无法给出精确可靠的解决方案。人们期待它能独自解决所有问题,对它的定义却是空心的。缺少明确的角色定位,这让大模型进入实际场景时变得障碍重重,大模型本身幻觉和时效性的问题也凸显出来。
在王小川看来,搜索增强能力是大模型在企业落地的前提。但进一步,搭配搜索增强能力之后,大模型在实际场景中需要一个更灵活的外接数据库来做补充。
此次与Baichuan2-Turbo系列的发布同时,百川智能发布了新的搜索增强知识库能力,这意味着企业现在可以从私有化部署到云端把自己的知识上传上来,做一个外挂的资料库,跟Baichuan2大模型做对接,来为基础大模型加入行业知识。但区别于原来的行业大模型,这种方式没有对基础大模型本身做训练,理论上是一个成本更低的方式,而在时效性上更灵活,也不会增加出现幻觉的概率。
而从搜索增强能力注入到现在知识库功能的上线,百川智能的在B端的商业化道路正式开始了。
在长度与广度里找平衡
最近Andrej Karpathy的一番言论,似乎重新定义了“幻觉”。
Andrej Karpathy是OpenAI的创始人之一。他在人工智能领域地位颇高,也是特斯拉前 AI 总监,他在今年2月从特斯拉回归OpenAI。Karpathy近日发推表达了一种观点:大语言模型的全部工作恰恰就是制造幻觉,大模型就是“造梦机”。
图源:X
“大模型就是在做梦,这是幻觉问题的原因。相比之下搜索引擎完全不做梦,所以它存在创造力问题——因为它的逻辑是根据输入的提示,直接返回其数据库中最相似的“训练文档”,也就是说它永远不会提供新的回应。”
如何定义幻觉,在理论层面仍然是一个开放问题,但可以确认的是,ToB不喜欢幻觉。
金融、医疗和法律这些相对明确的AI实践场景需要极高的严谨性,而这种严谨又建立在巨大的文本体量上——研报、医疗报告或者法律卷宗。在这些大模型最先探入的场景里,避免幻觉有一个隐形的前提条件,是要在输入和输出两端上下文长度和知识广度之间找到平衡。
如果将大模型 搜索增强看作是大模型时代的新计算机,那么大模型类似于计算机的CPU,通过预训练将知识内化在模型内部,然后根据用户的Prompt生成结果;上下文窗口可以看做计算机的内存,存储了当下正在处理的文本;互联网实时信息与企业完整知识库共同构成了大模型时代的硬盘。
这次Baichuan2Turbo系列API的发布背后,一个完整的延续着相似逻辑的大模型技术栈逐渐搭建完成。
王小川第一次提出类似技术栈的思路,是在今年7月:
“讲个最简单的例子,做模型肯定会遇到幻觉问题,时效性问题。幻觉和时效性都是光靠大模型本身能解决的。有人用扩大参数,扩大到万亿,十万亿来解决幻觉;或者用强化学习。但其实最直接的做法就是把搜索和信息检索带进去。大模型和这些结合在一块,才能形成一个更完整的技术栈。”
他认为现在美国对于应用层比较迷茫,中国现在的问题是模型能力不足。今天很多做模型的创业公司,也是把自己的视角局限在大模型上,对其它技术栈没那么了解。那时候的百川智能刚刚发布了130亿参数开源大模型Baichuan-13B。
这之后,这家大模型公司的整体进展或许可以描述成对这整个技术栈的补全。
今年8月王小川第一次在Baichuan-53B身上提出了搜索增强的概念。Baichuan模型中的搜索增强系统融合了包括指令意图理解、智能搜索和结果增强等关键组件的多个模块,并且王小川表示,相比其他大模型的检索增强,“(Baichuan-53B中)搜索跟模型的结合从非常底层的地方就开始去融合 ”。
一个月后百川智能表示,Baichuan2-53B已经是国内幻觉处理能力最优秀的模型。
到了10月,百川智能将Baichuan2的上下文窗口长度高达扩展到192K,可以一次吃掉一本35万字的《三体》,其在长文本测评基准LongEval中的10项评测集中拿到7项SOTA(最优模型)。
在搜索能力和长文本能力之后,知识库能力在此时推出则是这整个技术栈的最后一块拼图。
而要打开B端市场,还有成本这个重要考量维度。知识库与搜索的结合逐渐被验证会是容量、成本、性能、效率的最佳选择,而推崇这两者,也意味着行业大模型的概念开始被放弃。
图源:百川智能官网
不要动基础模型
大模型是一个参数化的知识容器,知识内化在模型内部,道不清说不明,是提炼之后的跨学科通用知识。
但实际场景需要实时更新。在垂直领域,尤其是领域知识不易公开获取的场景,模型本身的领域知识严重不足。这使得大模型必须与企业数据结合才能解决实际应用。而大模型如何补充时效性,在B端发挥作用,有两条路线。
此前的路线是做一个行业大模型,也就是用行业知识来预训练或者微调训练大模型。
但是基于特定数据预训练或微调垂直行业大模型需要高密度的技术人才团队、大量的算力支持,并且每更新一次数据都要重新训练或微调模型,不仅成本高昂、灵活性差,更关键的是不能保证训练的可靠性和应用的稳定性,多次训练后仍会出现问题。
“此外,大部分企业数据都是结构化的数据,也不适合SFT,模型无法准确记忆结构化信息,会带来幻觉。”王小川表示。
另一条道路是不碰基础模型,用搜索能力搭配外置的数据库,这种更轻巧的技术路径逐渐在大模型开发者中成为一种新的共识。
2021年,OpenAI发布了WebGPT,首次展现了搜索能力加入后对大模型能力的增益。WebGPT是基于GPT-3模型的一种创新,它通过使用互联网来响应开放式查询,大大提高了回答的准确性和可靠性。这是人工智能领域的一个重要转折点,展示了AI在提供更透明、更可靠的回答方面的未来可能性。
WebGPT的工作过程类似于人类在线查询回答的方式。它首先提交搜索查询,然后跟踪链接并浏览网页以收集信息。这种独特的方法有效地提高了回答的准确性,在减少幻觉的同时,WebGPT开始能够在长篇问答任务中达到与人类相当的表现。
今年11月,OpenAI 开始提供一款RAG(Retrieval-Augmented Generation)产品Retrieval检索工具,在不修改底层模型本身的基础上让使用者能够引用额外的数据源,而不仅仅局限于ChatGPT原始的训练集,从而提高输出的准确性和相关性。
搜索能力与外置数据库的结合,也有机会将国内的AI公司从此前NLP、CV殊途同归的项目制泥潭里挣脱出来。
“我们今天发布的知识库是产品。用知识库这种用可配置可调整的方式,其实是希望用产品的方式实现企业低成本的定制,来解决过往高成本的项目制的问题,这是我们的思路”,百川智能技术联合创始人陈炜鹏说。
但目前企业构建自己大模型知识库的主流方法仍然是向量检索,向量模型的效果过于依赖训练数据的覆盖,在训练数据未覆盖的领域泛化能力会有明显折扣,并且用户prompt和知识库中文档长度的差距也给向量检索带来了很大挑战。
百川智能在向量数据库和长窗口的基础上融合了稀疏检索和ReRank模型,实现了稀疏检索与向量检索并行。向量检索在语义上会更加贴近,但在embedding之后会存在很多漂移和漏召的情况,稀疏检索在召回、语义漂移问题等问题上相比反而有优越性,这种独特的并行检索方式的实现仰仗于对稀疏检索的技术积累,后者则源自这支从搜索引擎转身的技术团队在基于符号的搜索方式方面的经验。
这种并行的检索方式能够让Baichuan2模型的目标文档召回率提升到95%,目前市面上主流开源向量模型的召回率在80%。
对于大模型在回答过程中由于引用资料不准确以及与大模型不匹配,导致模型的“幻觉”加重的现象。百川智能在RAG技术基础上首创了Self-Critique大模型自省技术,该技术能够让大模型基于Prompt对检索回来的内容从相关性、可用性等角度进行自省,筛选出最优质、最匹配的候选内容,有效提升材料的知识密度和广度,并降低检索结果中的知识噪声。
ToB,局限在文本上吗?
在GPT-4之后,无论是Meta的AnyMAL还是谷歌最新的Gemini都开始体现出对多模态模型能力的重视,国内的百度也是,与百川智能同在一座大楼的智谱AI早在今年5月已经开源了多模态大模型VisualGLM-6B。
百川智能目前所展示出的场景示例中,有包括问答、信息提取、咨询分析等多达20个细分场景,但仍然完全集中在文本生成这个领域。多模态能力目前仍然没有在Baichuan系列模型中出现。
从语言跨向多模态这一步,百川智能显得克制。
王小川看来,最终还是文本能力代表了大模型智力化的水平,这是百川智能目前唯一聚焦的方向。
“我们认为在追求模型智力或者追赶全球最领先的大模型时,把文本放在第一位的公司是在往长远走的。所以今天如果公司首先考虑音频、图像、视频等等,反而已经不在这条追赶道路里了。
文本能力的追赶是大家最应该关注的事情,而多模态反而是离应用最近的一件事,反而后者可以用更小的模型来推动。”
近段时间出现的,Phi-22.7B和Mistral7B用非常小的尺寸击败了Llama2-7B和13B,甚至Mistral7B在数学和代码生成方面的表现超越了Llama-34B,这也让人重新考虑模型参数和模型能力之间的关系。
从4月成立至今,百川智能打造大模型产品的速度很快,模型参数规模从7B和13B起跳,迅速扩展到53B,突破100B(千亿)的大模型研发计划也在之前就有所透露。对于百川智能来说,模型的参数规模仍然是一座要攀的高山。
“对ToB来说,由于私有化的必要性,太大参数的规模对企业的成本是过高的,这方面因为有外挂知识库的技术,其实现在已经不是很担心参数规模对模型能力的影响”,王小川说。
“在整体规划上,我们做7B和13B的模型就是用来做开源的,但主力的模型还是会往百亿、千亿上走。”
蔚来宣布五一期间高速公路提供24小时换电免费
蔚来宣布自4月28日至5月4日,全国共362座高速公路换电站向所有蔚来车辆提供不限次数的免费换电服务(不包括营运车辆),在其中的高速服务区换电站更将24小时不停歇地提供服务,以为用户在五一节期间的出行提供更加便捷的支持。截至4月25日,蔚来在全国已累计建成362座高速公路换电站,完成6纵3横8大城市群高速换电网络布局:站长网2023-04-25 15:40:040001MoA:用于图片合成的混合注意力架构 可实现风格参考和人物融合
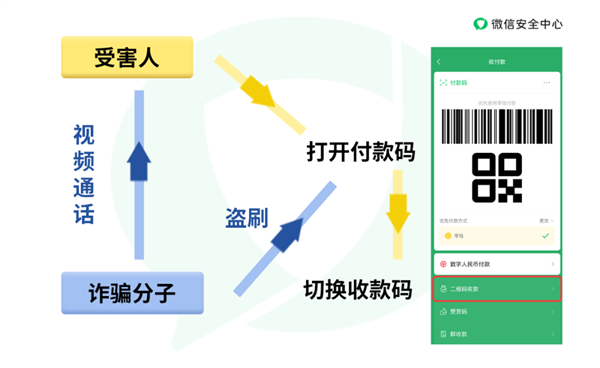
划重点:🔍引入了一种新的架构,名为注意力混合模式(MoA),用于个性化文本到图像扩散模型。🎨MoA通过将生成工作负载分配给两个注意力路径来实现给定主题和背景的分离生成。🖼MoA能够生成高质量、个性化的图像,使得主题和背景的控制更加分离。在最新的研究中,提出了一种名为注意力混合模式(MoA)的新架构,旨在个性化文本到图像扩散模型,可以实现风格参考和人物融合的效果。站长网2024-04-22 09:59:320000微信提醒:视频通话出示收款码 小心收款变付款
快科技10月12日消息,微信110提醒,骗子再出新花招”,小心收款变付款!据了解,该骗局主要针对商户老板,诈骗分子先是通过网络平台寻找目标受害人,以有交易需求为由,与受害人添加好友。随后以付款、支付定金等理由向受害人索要收款码。当受害人提供收款码的图片后,诈骗分子便会谎称无法识别收款码或收款码失效,并且提出与受害人进行视频通话,让受害人用另一台手机,在视频通话中展示收款码。站长网2024-10-14 18:33:420000文心一言率先全面开放!百度宣布文心一言向全社会全面开放
8月31日,文心一言宣布率先向全社会全面开放。广大用户可以在应用商店下载“文心一言APP”或登陆“文心一言官网”(https://yiyan.baidu.com)体验。据悉,百度还将开放一批经过全新重构的AI原生应用,让广大用户充分体验生成式AI的理解、生成、逻辑、记忆四大核心能力。今年3月16日,文心一言开启邀测,近期升级的文心大模型3.5也持续在十余个国内外权威测评中位居第一。站长网2023-08-31 08:05:040000“99元做一次脸”的医美直播被紧急喊停!从业者们何去何从
医美直播被紧急按下刹车键。2月23日晚,央视《焦点访谈》曝光了医美直播乱象,指出大部分医美直播间开展的“带货”行为均涉嫌违法发布医疗广告。该节目一经播出,抖音、快手多个平台的医美直播间随即都被紧急关停,有医美达人感叹:“我仿佛见证了一个行业的覆灭。”目前抖音、快手平台已经不显示医美直播内容在此之前,内容平台曾对医美内容进行过多次治理。站长网2024-03-03 21:41:110000