内容生产商担心谷歌新的人工智能搜索引擎可能会损害网站的流量
在本周三的 I/O 大会上,谷歌预览了可能是其历史上最大的搜索引擎变革之一。

谷歌将使用人工智能模型在响应搜索查询时从互联网上汇总并概述信息,该产品称为「搜索生成式体验」。
谷歌将向一些用户展示生成 AI 的文本段落和少量链接,而不是「十个蓝色链接」,这是描述谷歌通常的搜索结果的短语。
新的基于 AI 的搜索正在针对一小部分用户进行测试,尚未广泛推出。但网站站长们已经担心,如果这成为谷歌呈现搜索结果的默认方式,可能会通过减少访问者访问他们的网站并让他们停留在 Google.com 上伤害他们的利益。
这场争议凸显了谷歌与它所索引的网站之间长期存在的紧张关系,并添加了新的人工智能元素。网站站长一直担心谷歌在其自己的网站上以片段的形式重复使用他们原始的内容,但现在谷歌正在使用高级机器学习模型从大量网页中抓取信息,从而「训练」软件生成类似人类的文本和回应。
聚焦游戏新闻和评测的网站 TechRaptor 的首席执行官 Rutledge Daugette 表示,谷歌的举动没有考虑网站的利益,而谷歌的人工智能等同于抄袭内容。
Daugette 告诉 CNBC:「他们的重点是零点击搜索,该搜索使用发布者和撰写高质量内容的作家的信息,而没有提供任何除潜在点击之外的好处。目前,人工智能很快地复用其他人的信息,对他们没有任何好处,而在谷歌这样的情况下,Bard 甚至没有注明该信息的来源。」
Yelp 的公共政策主管和长期的谷歌批评者 Luther Lowe 表示,谷歌的更新是为了将用户留在自家网站上更长时间,而不是将他们引导到最初承载该信息的网站。
Search Engine Land 是一家密切跟踪谷歌搜索引擎变化的新闻网站,据该网站报道,到目前为止,人工智能生成的结果显示在迄今为止测试的自然搜索结果上方。该网站此前报道了谷歌计划重新设计搜索结果页面以促进生成的 AI 内容的计划。
在搜索中,SGE 出现在不同颜色的框中,例如绿色框,并在右侧显示三个网站的链接。在谷歌的主要示例中,所有三个网站的标题都被截断了。
谷歌表示,该信息并非来自网站,而是通过链接进行协作的。Search Engine Land 称,SGE 方法是一种改进和比谷歌的 Bard 聊天机器人更「健康」的链接方式,后者很少链接到原始信息来源的网站。
一些发布者正在思考他们是否可以阻止像谷歌这样的 AI 公司抓取其内容以训练其模型。数据所有者的公司,如 Stable Diffusion 背后的公司已经面临诉讼,但有关 AI 抓取 Web 数据的权利仍然是一个未决的领域。其他公司,如 Reddit,已宣布计划收费以获得对其数据的访问权限。
在出版界领先的是 IAC 的主席 Barry Diller,该公司拥有 All Recipes、People Magazine 和 The Daily Beast 等网站。
Diller 在上个月的一个会议上说:「如果所有的世界信息都能够被吸入这个漩涡,然后重新打包,在所谓的聊天中——但这并不是聊天——而是用任意数量的信息嫁接,25 个任意主题——这样就不会有网站了,因为这是不健康的。」
Diller 继续说:「你必须让行业说,在你解决了网站获得某些收益途径的系统之前,你不能抓取我们的内容。」
Diller 表示,他相信发布者可以根据版权法起诉 AI 公司,并且需要重新定义当前的「合理使用」限制。据《金融时报》报道,Diller 正在领导一个内容商的团体,「如果必要,他们将改变版权法。」IAC 的一位发言人拒绝了接受 Diller 采访的请求。
内容商面临的一个挑战是确认他们的内容是否正在被 AI 使用。谷歌没有透露其支撑 SGE PaLM 2 的大型语言模型的训练来源,Daugette 表示,虽然他已经看到竞争对手的引用和评论分数的例子被没有进行归属的复用在 Bard 上,但没有直接链接的来源时很难判断信息是否来自他的网站。
谷歌的举动令独立出版商的生存变得困难。Daugette 说:「我认为我们的行业必须担心我们辛勤工作的成果被剽窃,而许多同行正在被裁员。这是不好的。」
宾大最新研究:AI 在创造力方面的表现比人类更出色
最新的研究表明,人工智能在创造力方面的表现比人类更出色。一项由康奈尔科技学院和宾夕法尼亚大学沃顿商学院共同完成的研究发现,与就读于精英大学的学生相比,AI(ChatGPT4)在创造新产品创意方面的效率提高了40倍,创意质量也相当不错。论文地址:https://www.hbritalia.it/userUpload/ebook_Generative_AI_inglese.pdf站长网2023-08-14 11:06:270001中国AI平台最新格局出炉!百度综合得分第一,第二梯队竞争激烈,大模型加速云厂商进化
大模型趋势,给与之相关的一切来了亿点“小震撼”。人工智能/机器学习平台正是其中之一。它与大模型趋势紧密相关,能直接反映出各大云厂商的AI技术研发储备水平,以及对最新趋势的洞察和理解能力。究竟谁家实力更强?正被业内所津津乐道。而技术风向剧变之下,AI/ML平台也有了新的评价标准。国际权威机构Forrester最新发布的“首份中国人工智能/机器学习平台报告”,恰逢其时给出参考。站长网2023-10-30 10:14:150001苹果最新AI研究或彻底改变iPhone体验 比如可从视频生成逼真3D头像
**划重点:**1.🎥**3D动态头像技术:**苹果提出HUGS技术,从短视频中生成逼真的3D动态头像,训练速度是之前方法的100倍以上,为更沉浸的视觉体验打开新可能。2.🧠**内存优化:**苹果研究人员攻克在有限内存设备上运行大型语言模型的难题,通过降低数据传输量和优化读取方式,实现在iPhone等设备上高效运行复杂的AI系统。0000360智脑大模型全面接入360全家桶 正式面向公众开放
360宣布,360智脑大模型全面接入360全家桶,正式面向公众开放。用户可通过ai.360.com一站式登录体验360智脑app、360搜索、360安全浏览器、LoRA360、AI数字员工等大模型服务。站长网2023-09-21 09:29:590000华为云盘古大模型通过金融大模型标准符合性验证
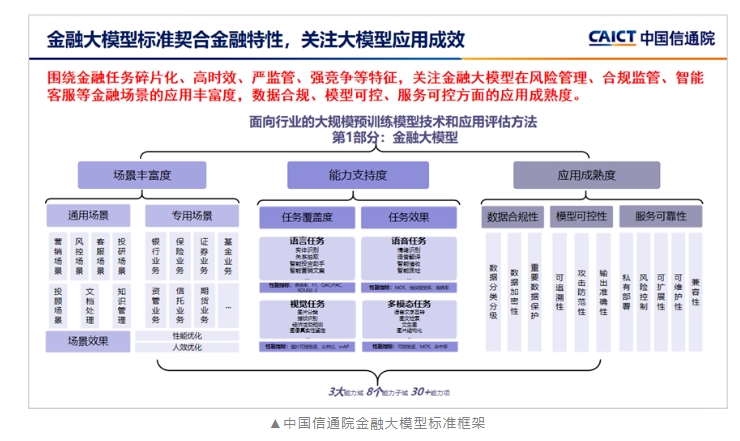
据华为官方消息,2023年12月,在中国信通院组织的可信AI大模型标准符合性验证中,华为云盘古大模型成功完成了金融大模型的验证,并获得了优秀级(4级)评分。这一成绩不仅突显了华为云盘古大模型在金融领域的卓越性能,还使其成为首批通过金融大模型及行业大模型标准符合性验证的产品。站长网2024-03-04 19:34:000000