谷歌2024年目标:成为全球最先进、安全、负责任的AI提供商
划重点:
🤖 Google2024年的主要目标是“提供全球最先进、安全、负责任的人工智能”。
🚀 其他目标包括提升知识、学习、创造力和生产力,创建有用的个人计算平台和设备,推动企业和开发者在Google Cloud中创新,交付全球最受信任的产品和平台,以及构建一个“卓越”的Google。
🌐 在云计算业务方面,由于AI能力的不足,可能面临更多的裁员压力。
Google最近内部宣布了其2024年的企业目标,人工智能位居榜首。根据泄露给The Verge的Alex Heath的一份内部文件,Google2024年的主要目标是“提供全球最先进、安全、负责任的人工智能”。

其他目标包括:
- 提升知识、学习、创造力和生产力;
- 创建有用的个人计算平台和设备;
- 授权企业和开发者在Google Cloud中创新;
- 交付全球最受信任的产品和平台;
- 为员工和全球构建一个“卓越”的Google。
列表中的最后一个目标是“提高公司速度、效率和生产力,并实现持久的成本节约”,这暗示可能会有更多的裁员。自一月初以来,据报道,Google在各个领域裁员数千人。
在另一份独立的内部备忘录中,Pichai提到了今年的“宏伟目标”和“重要任务”。为了为投资留出空间,必须做出“艰难的选择”以提高效率。根据备忘录,裁员预计规模将较去年小,去年Google在一月份裁员约1.2万名员工。
在人工智能技术和部署方面,Google目前远远落后于Microsoft和OpenAI。根据基准测试,去年推出的Gemini模型几乎无法与OpenAI的模型媲美,而据报道,OpenAI已经在进行下一个重大升级,将发布GPT-4。
在产品化方面,与Microsoft一样,Google正试图将人工智能整合到现有产品中,如其业务应用、Pixel智能手机和生成式人工智能搜索。
然而,Google尚未推出像ChatGPT这样成功的独立人工智能产品。有传言称,Google正在基于其最强大的Gemini Ultra型号开发一款新的聊天机器人。但迄今为止,Google的Bard聊天机器人在用户数量上远远落后于ChatGPT。
由于OpenAI合作带动Microsoft云业务增长速度超过Google,这可能是Google的一大痛点。大型科技公司将云计算视为下一个增长的地平线。
从Google的角度来看,积极的一面是,一些人在2023年初预期的聊天机器人扰乱其搜索业务的情况也未发生。尽管如此,人工智能垃圾信息给Google搜索的质量带来了压力。
AI在玩一种很新的艺术,700万网友在线围观,ControlNet又立功了
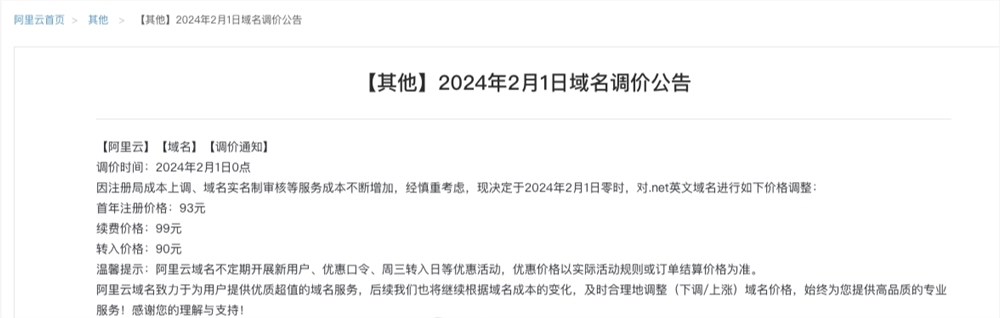
AI又在玩一种很新的艺术。一组“在离谱与合理的边缘反复试探”的图席卷各大平台,最火的一条𝕏已有近700万查看16.8万点赞,到处有人在求教程。除了棋盘样式,还有一种螺旋样式的也很流行。连知名投资机构YCombinator的创始人PaulGraham都来围观:这一刻,AI生成的艺术通过了我的图灵测试。不少网友更是在讨论中提到:这些AI作品给人一种错觉图形大师埃舍尔的感觉。站长网2023-09-19 14:34:310000阿里云.net英文域名2月1日起调价 首年注册价格93元
近日,阿里云在官方网站发布公告,宣布将于2024年2月1日零时起对.net英文域名进行价格调整。此次调价是由于注册局成本上调以及域名实名制审核等服务成本的增加所导致。调整后的价格为:首年注册价格93元,续费价格99元,转入价格90元。这一调整是为了应对不断增长的成本压力,同时保证服务的稳定性和质量。以下为阿里云公告全文:调价时间:2024年2月1日0点站长网2024-01-10 15:23:460000把大模型装进手机,分几步?
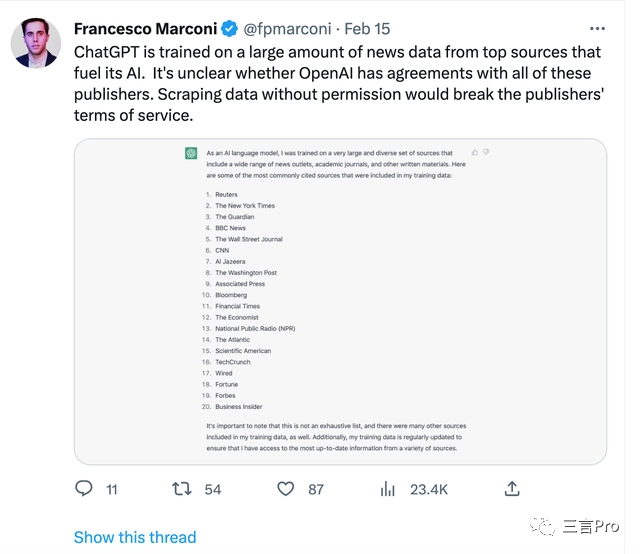
大模型“跑”进手机,AI的战火已经从“云端”烧至“移动终端”。“进入AI时代,华为盘古大模型将会来助力鸿蒙生态。”8月4日,华为常务董事、终端BGCEO、智能汽车解决方案BUCEO余承东介绍,通过盘古大模型的底层技术,HarmonyOS带来了下一代智能终端操作系统。站长网2023-08-08 09:05:220000涉图片侵权、错误信息诽谤等,AIGC将迎来侵权潮?
一直以来,关于AI是否侵权的相关话题的讨论就没有停止。而自从ChatGPT打开了生成式AI(AIGC)新大门,AI侵权的风险被进一步放大。相比于ChatGPT此类的文字大模型,AI绘画似乎存在更大的争议,已经有图库公司和个人发起侵权起诉,还有国内原创平台推出AI绘画惹得不少画手删号退出。ChatGPT侵权争议不断法学教授莫名成“性骚扰者”程序员指控代码被侵权美国新闻集团拟发起版权诉讼站长网2023-04-12 15:44:090003AI误判!美国教授用ChatGPT「证实」论文抄袭 一半学生挂科
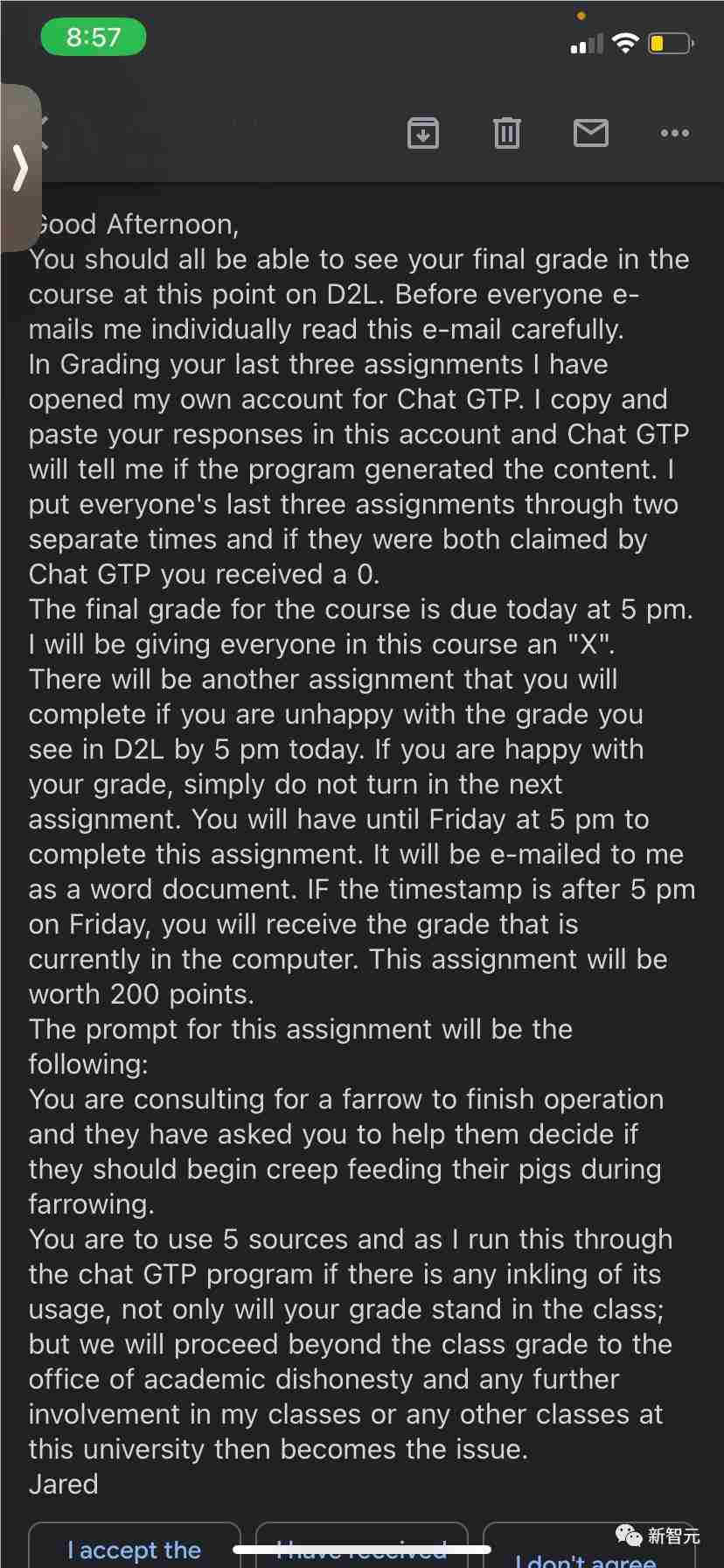
一位得克萨斯农工大学的教授,因为对ChatGPT的原理一窍不通,误以为它可以识别由AI生成的内容,结果导致班上一多半人的论文被ChatGPT误判为抄袭,学校拒发了他们的毕业证。一些学生提供了带有时间戳的GoogleDocs来证明自己没有使用ChatGPT,但教授无视了这些证据。目前,事件正在调查中,个别学生的文凭将被扣留,直到调查完成。站长网2023-05-18 15:23:380000