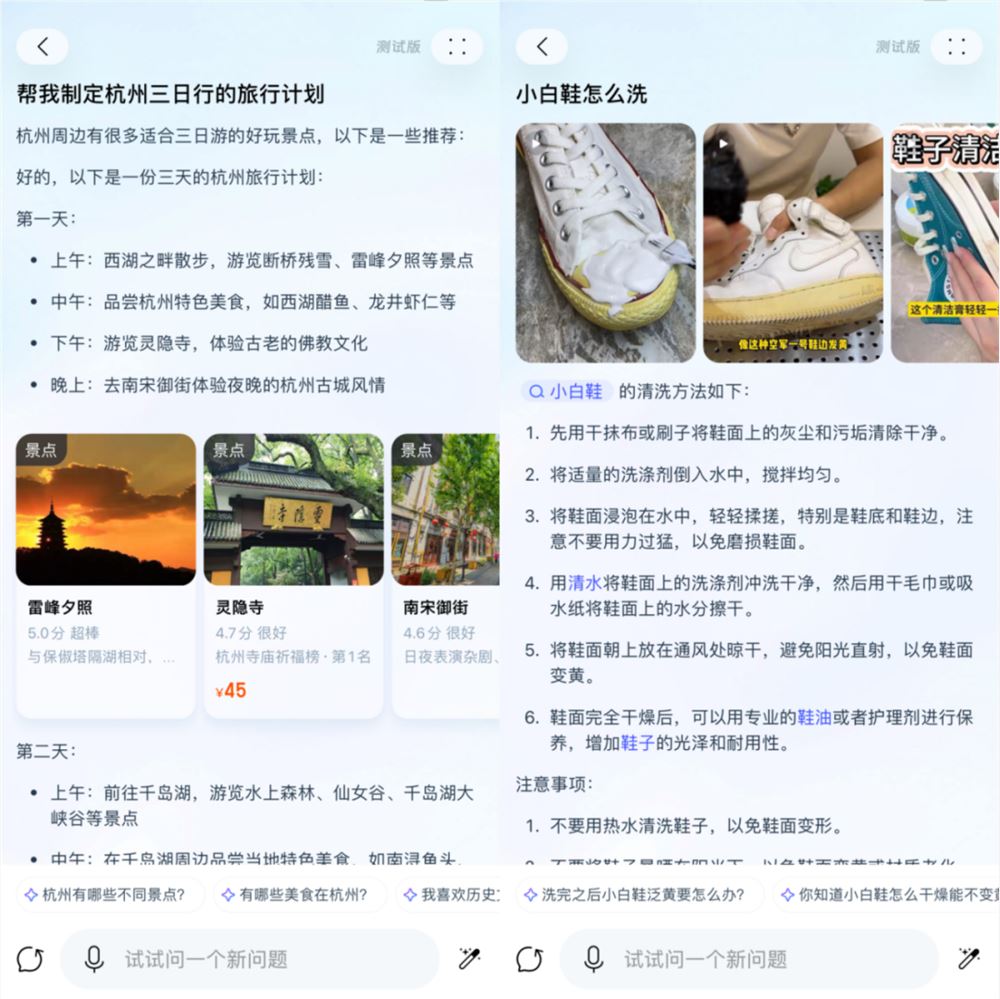
小红书提出创新框架:充分利用负样本提升大语言模型推理能力
要点:
小红书搜索算法团队在AAAI2024上提出了一种创新框架,利用负样本知识来提升大语言模型(LLMs)的推理能力。
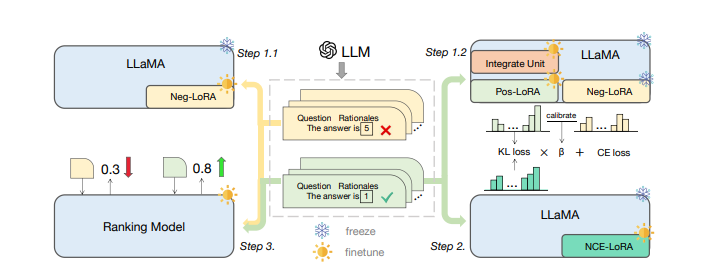
他们设计了一个模型专业化框架,包括负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC)等序列化步骤,全面利用负样本在知识蒸馏中的关键作用。
该框架通过在训练和推理过程中充分利用负样本,使得小模型能够更好地处理复杂的数学推理问题,避免大模型的黑盒属性和庞大参数量的限制。
在AAAI2024上,小红书搜索算法团队推出了一项创新框架,旨在解决大语言模型(LLMs)在推理任务中的黑盒属性和庞大参数量带来的问题。传统研究方法主要关注正样本,而这项工作强调了负样本在知识蒸馏中的价值。通过负向协助训练(NAT)、负向校准增强(NCE)和动态自洽性(ASC)等序列化步骤,他们构建了一个全方位利用负样本的模型专业化框架。
论文地址:https://arxiv.org/pdf/2312.12832.pdf
首先,他们提出了负向协助训练(NAT)方法,通过设计dual-LoRA结构,从正向和负向两方面获取知识。这一步骤在训练中动态地集成正、负LoRA模块的知识,以构建更全面的推理能力。其次,他们设计了负向校准增强(NCE),利用负知识来帮助自我增强过程,通过KL散度来度量正、负推理链路之间的不一致性,以选择性地学习和增强嵌入的知识。
除了训练阶段,他们还在推理过程中利用负向信息,提出了动态自洽性(ASC)方法,通过排序模型在正、负样本上进行训练,为正确答案的推理链路分配更高的权重。整体来说,这一框架通过充分挖掘负样本的宝贵信息,使得小模型能够更有效地进行复杂的算术推理,从而在实际应用中更广泛地部署大语言模型的推理能力。
这一研究为提高大语言模型应用性能提供了新思路,通过引入负样本的知识,弥补了传统研究方法的不足,为推理任务的应用提供了更可靠和高效的解决方案。
淘宝,多了一个“ChatGPT”入口
电商,正在悄然切换,进入AI时代。现在打开淘宝,搜索“淘宝问问”,你可以直接跳转到一个全新的页面。在这个新的页面输入你的问题,可以获得内容回复,包括商品挑选攻略、生活经验百科、外出行程建议等——使用体验类似电商版“ChatGPT”,区别在于,答案中会附上相应的淘宝商品链接。站长网2023-10-07 15:35:350000淘宝网页版直播功能全面优化 APP直播间均已上线
淘宝网页版近日迎来了一场重要的升级——直播功能的全面优化。在网页版淘宝中,原先APP上的所有直播间均已上线,直播间列表整齐排列,方便用户快速浏览和选择。直播间内的布局也经过精心设计,直播画面、宝贝口袋和聊天互动三个区域并行排列,充分利用了PC端的大屏优势。相较于手机端,用户在网页版上可以更加清晰地看到商品细节,更轻松地发表评论,同时也不会错过任何直播内容。站长网2024-05-22 20:33:070000百度:9月份以来清理“网络厕所”相关有害信息10357条
今日,百度发布《关于近期“网络厕所”问题的治理公告》称,近期,在日常巡查中发现,有社交平台账号接收并发布不良导向匿名投稿信息;有账号恶意发布攻击吐槽学校内容,肆意宣泄不满情绪;有账号在简介中注明可以提供匿名投稿、隔空喊话、开口辱骂等服务;还有账号直接曝光当事人照片和隐私信息。站长网2023-09-19 15:00:320000小米Civi 3即将更新小米澎湃OS
小米今日宣布,将在明天发布小米Civi3迪士尼限定版,联名迪士尼人气形象草莓熊。对于本次联名,小米Civi产品经理胡馨心表示,这一次的合作真的非常有趣。此外,胡馨心在回复网友问题时透露,小米Civi3即将更新小米澎湃OS。0000