MIT最新研究:纯文本模型也能训练出视觉表征 用代码就能作画
要点:
MIT的研究团队通过对语言模型的系统评估,展示了使用纯文本模型训练视觉概念表征的可能性,通过代码生成图像,实现视觉学习系统。
虽然语言模型无法直接处理像素形式的视觉信息,但通过对字符串关系的建模,研究人员成功训练出能够理解和生成复杂视觉概念的模型。
研究结果表明,语言模型在生成复杂场景方面表现出色,但在捕捉视觉细节如纹理、精确形状等方面仍有改进空间,通过文本纠错可进一步提升模型的视觉生成能力。
最近,MIT计算机科学与人工智能实验室的研究人员进行了一项有趣的研究,通过评估语言模型的视觉能力,揭示了纯文本模型训练视觉概念表征的新可能性。
他们使用代码而非图像进行渲染和表示,成功地教会语言模型生成和理解复杂的视觉概念。虽然生成的图像可能不像自然图像,但通过模型的自我纠正,研究人员证明了对字符串和文本进行精确建模可以教会语言模型有关视觉世界的多种概念。
论文地址:https://arxiv.org/pdf/2401.01862.pdf
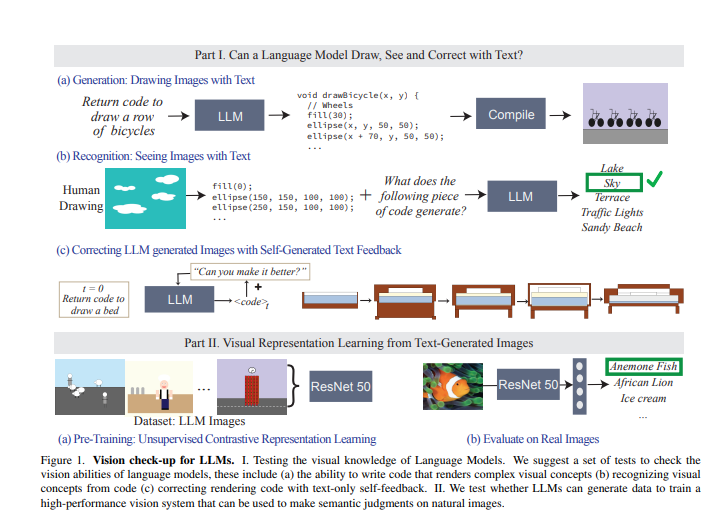
研究人员构建了三个不同复杂度的文本描述数据集,从简单的形状和组合到复杂的场景,评估了模型在生成、识别和修改图像渲染代码方面的能力。
实验结果显示,语言模型在生成由多个物体组成的复杂视觉场景方面表现出色,但在捕捉视觉细节方面有一些局限。通过文本纠错,研究人员成功地改善了模型的视觉生成能力,为使用纯文本模型训练视觉系统提供了新的思路。
研究中的一个关键发现是,语言模型在生成代码方面表现出相当高效的能力,但在识别以代码表示的视觉概念方面较为困难。与人类相反,模型在生成复杂场景方面表现出色,但在解释代码内容上存在难题。通过使用自身生成的自然语言反馈,研究人员成功地通过迭代过程改善了模型的视觉效果。
综合而言,这项研究拓展了我们对语言模型的理解,展示了它们不仅可以理解视觉概念,还能够通过文本生成和纠错进行视觉学习。这为未来发展更强大的纯文本模型提供了启示,有望推动语言模型在视觉领域的更广泛应用。
半年多过去了,ChatGPT的排名快“垫底”了
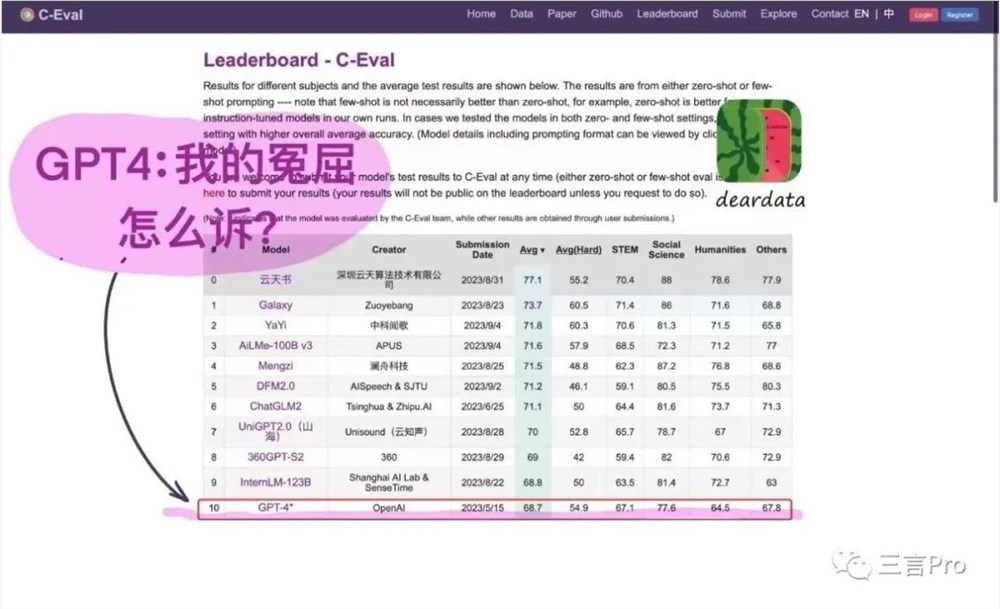
今天,笔者无意中刷到一张图片。据该图片显示,OpenAI的GPT-4在11个大模型中(第一名序号为0),已经排到了最后。还有网友配上了“GPT4:我的冤屈怎么诉?”的字样。这不禁让人好奇,今年年初,ChatGPT爆火以后,其他公司才开始提大模型的概念。这才半年多,GPT就已经“垫底”了?于是,笔者想看看GPT排名到底咋样了。测试时间不同测试团队不同GPT-4排第十一站长网2023-09-08 11:12:020000Altman力推GPT-4新应用:让GPT-4能穿梭时空,过目不忘的私人AI助理
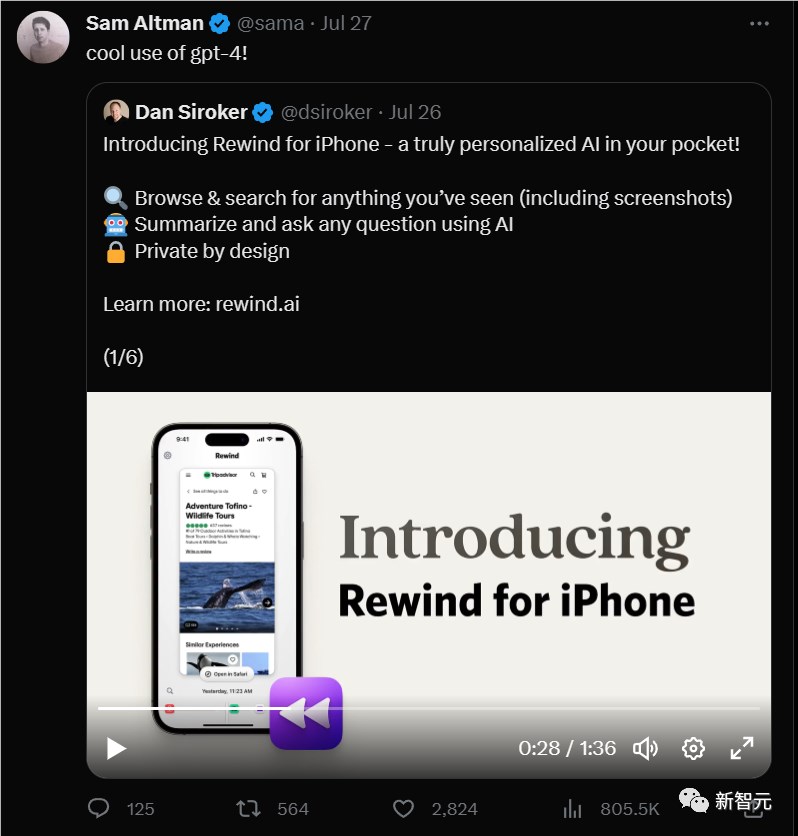
【新智元导读】Rewind是一款结合了GPT-4能力的时空搜索工具。每个月只要12刀,就能获得一个过目不忘的AI助理。最近一个GPT-4的应用火了!甚至Altman本人都亲自给他站台!这是一款名叫Rewind的应用。网友给它起了一个略显中二的名字「人生搜索引擎」。简单来说,这个APP最主要的功能就是帮你寻找到自己在iPhone和Mac上以前看过的所有数据,并以此为基础回答你的所有问题。站长网2023-08-16 11:28:450000IBM加入战局!任意大模型低成本变ChatGPT方法开源,个别任务超GPT-4
科幻中有机器人三原则,IBM说不够,要十六原则。最新大模型研究工作中,以十六原则为基础,IBM让AI自己完成对齐流程。全程只需300行(或更少)人类标注数据,就把基础语言模型变成ChatGPT式的AI助手。更重要的是,整个方法完全开源,也就是说,任何人都能按此方法,低成本把基础语言模型变成类ChatGPT模型。站长网2023-05-08 09:14:520000研究发现,ChatGPT 能理解和回应人类情感
划重点:-研究发现,ChatGPT能理解和回应人类情感,当提示中包含情感因素时,聊天机器人的回答效果更好。-该研究表明,LLMs(大型语言模型)如ChatGPT可能能够“理解和回应情感暗示”。-如果ChatGPT确实能够理解人类情感,并且在提示中包含情感角度时能够更好地回应,那么我们可能离AGI更近一步了。站长网2023-11-16 17:55:550000麒麟990老旗舰重生!荣耀30、荣耀V30等8款设备喜提HarmonyOS 4
快科技11月15日消息,根据HarmonyOS官方最新公布,华为、荣耀共8款老设备已经推送HarmonyOS4正式版系统。分别是荣耀30、荣耀V30、荣耀30Pro、荣耀V30PRO、荣耀30Pro、荣耀Play4Pro。华为则是两款路由器设备:华为路由AX3、华为路由AX3Pro。升级方式:手机:打开设置系统和更新软件更新,检查更新站长网2023-11-15 20:31:040000