只需0.5秒!MobileDiffusion:在手机设备上就能实现快速文本生成图像
**划重点:**
1. 🚀 MobileDiffusion 是一种专为移动设备设计的高效潜在扩散模型,可在半秒内生成高质量512x512图像。
2. 🧠 通过优化模型架构,包括Diffusion UNet和图像解码器,MobileDiffusion展现了在计算效率上的出色表现。
3. 🌐 该技术有望在移动设备上推动快速图像生成体验,拓展了生成模型在提高用户体验和应对隐私问题方面的潜在应用。
在谷歌一项项名为“MobileDiffusion”的研究中,Google的研究员介绍了一种新颖的移动设备上文本生成图像的方法。传统的文本生成图像模型通常需要庞大的参数和强大的计算能力,而MobileDiffusion则专为移动设备设计,具有在半秒内生成高质量图像的潜力。
据了解,文本生成图像模型的相对低效性主要源于两个主要挑战。首先,扩散模型的固有设计要求通过迭代去噪生成图像,需要对模型进行多次评估。其次,模型架构的复杂性导致参数数量庞大,计算成本高昂。
虽然先前的研究主要集中在减少函数评估次数上,但移动设备上即使进行少量评估步骤也可能很慢。因此,MobileDiffusion致力于解决这些问题,通过优化模型架构和采用DiffusionGAN实现一步采样,从而在移动设备上实现快速文本生成图像。
MobileDiffusion的设计遵循潜在扩散模型,包括三个组件:文本编码器、扩散UNet和图像解码器。
文本编码器使用适用于移动设备的小型模型CLIP-ViT/L14。
对于扩散UNet,研究人员深入研究了Transformer块和卷积块的效率,并采用UViT架构来提高计算效率。与此同时,他们通过在UNet的深层段使用轻量级可分离卷积层,优化了卷积块的性能。
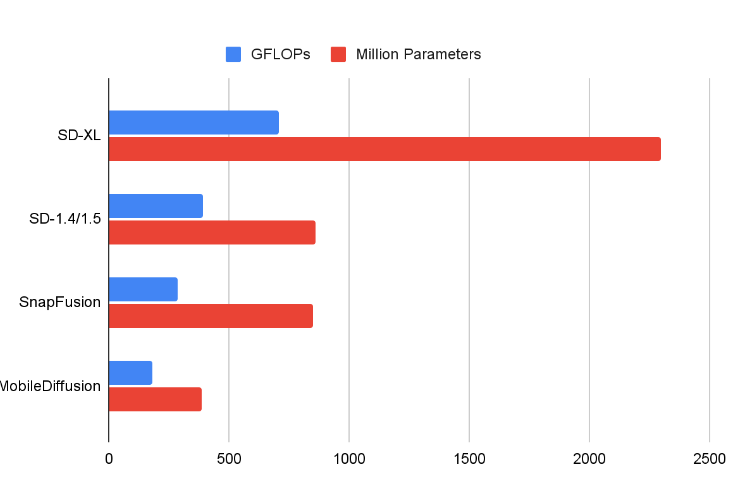
一些扩散 UNet 的比较。
图像解码器方面,他们训练了一个变分自编码器(VAE),通过修剪原始的宽度和深度设计了轻量级解码器架构。

VAE 重建。MobileDiffusion的 VAE 解码器具有比 SD(Stable Diffusion)更好的视觉质量。
为了进一步提高效率,研究人员采用了DiffusionGAN混合模型来实现一步采样。通过使用预训练的扩散UNet初始化生成器和判别器,简化了训练过程。该模型通过在少于10,000次迭代内收敛的微调过程,实现了文本生成图像的高效训练。
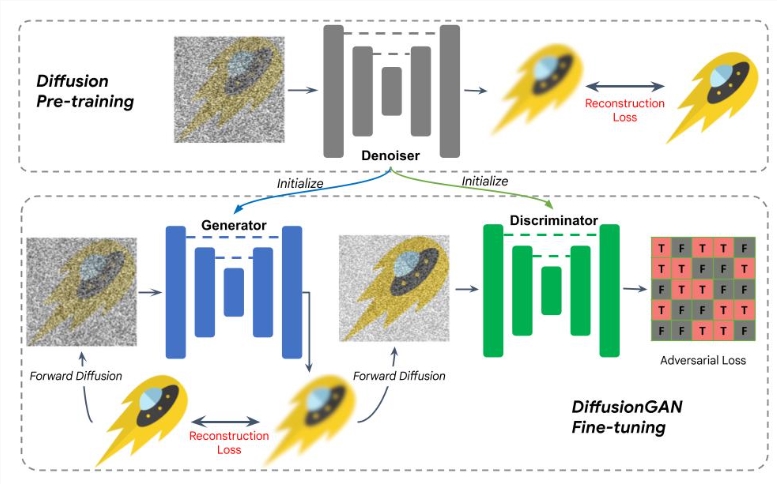
DiffusionGAN 微调的图示。
实验结果显示,MobileDiffusion在iOS和Android设备上表现出色,能够在半秒内生成512x512高质量图像。这种快速的图像生成速度为移动设备上的各种有趣用例提供了潜在可能性。研究人员表示,MobileDiffusion的高效性和小模型尺寸使其成为移动部署的理想选择,有望在用户在输入文本提示时提供快速的图像生成体验。
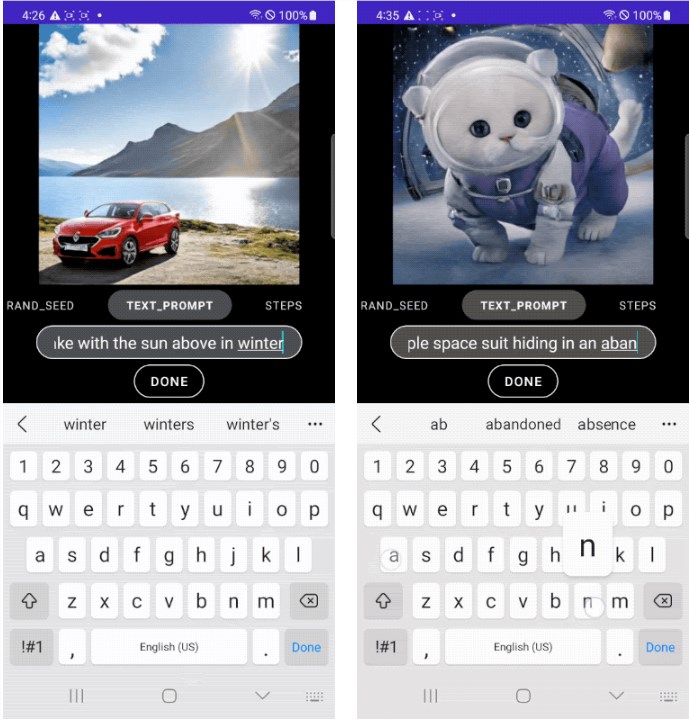
下图展示了 MobileDiffusion 与 DiffusionGAN 一步采样生成的示例图像。凭借如此小型模型(总共5.2亿参数),MobileDiffusion 可以为各个领域生成高质量的多样化图像。

用不同的运行时优化器测量了 MobileDiffusion 在 iOS 和 Android 设备上的性能。下面报告了延迟数字。可以看到MobileDiffusion非常高效,可以在半秒内运行生成512x512的图像。这种速度可能会在移动设备上实现许多有趣的用例。

MobileDiffusion的研究展示了在移动设备上实现快速文本生成图像的潜在前景,并承诺在应用该技术时遵循Google的负责任人工智能实践。
官方博客:https://blog.research.google/2024/01/mobilediffusion-rapid-text-to-image.html
论文网址:https://arxiv.org/abs/2311.16567
产品入口:https://top.aibase.com/tool/mobilediffusion
苹果被曝正开发全新芯片!比M4 Ultra更强:率先登陆Mac Pro
快科技1月15日消息,据媒体报道,苹果正在为其即将推出的新款MacPro开发一款全新的芯片,代号为Hidra”。此前外界普遍预期苹果会使用M4Ultra芯片为MacPro提供动力,但苹果可能会选择采用这款更强大的Hidra芯片,以满足专业级用户对更高计算能力的需求。0000ChatGPT/GPT-4/Llama电车难题大PK!小模型道德感反而更高?
【新智元导读】微软对大语言模型的道德推理能力进行了测试,但在电车问题中大尺寸的模型表现反而比小模型差。但最强大语言模型GPT-4的道德得分依旧是最高的。「模型有道德推理能力吗?」这个问题似乎应该跟模型生成的内容政策挂钩,毕竟我们常见的是「防止模型生成不道德的内容。」但现在,来自微软的研究人员期望在人类心理学和人工智能这两个不同的领域中建立起心理学的联系。站长网2023-10-11 17:28:500000阿里推新项目MotionShop 可将视频中的角色替换为3D
阿里巴巴推出了名为MotionShop的新项目,这一项目可以将视频中的角色替换为3D化身。MotionShop利用先进的视频处理和3D渲染技术,能够高效地将视频中的某个角色替换为3D人物,同时不改变视频中的其他场景和人物。被替换的3D人物能够完整复刻原视频中人物的动作,保持动作一致。项目地址:https://aigc3d.github.io/motionshop/站长网2024-01-17 11:19:010002韩国小游戏在畅销榜攀升3个月,这次国内厂商都看走眼了?
海外市场有一款塔防小游戏悄悄跑了起来。今年一月份,韩国厂商GameDuo(擅长RPG塔防,代表作《ArcherForest》)发布塔防游戏新品《红猪特攻队》。《红猪特攻队》的市场表现谈不上多好,有国内厂商仅在视觉包装上挪用了红猪形象并做出了《口袋宠物猪》《猪猪特攻队》,但在玩法层面并未跟进。在国内厂商看来,这一玩法似乎没什么潜力。0000