视频生成模型Stable Video Diffusion1.1发布 清晰度质量有所改进
站长网2024-02-05 10:52:342阅
Stable Video Diffusion (SVD) 模型1.1已经发布,通过测试视频展示了其令人瞩目的性能。SVD1.1模型是一个生成图像到视频的扩散模型,通过对静止图像的条件化生成短视频。
模型下载地址:https://top.aibase.com/tool/stable-video-diffusion-1-1-image-to-video

相较于前一代,SVD1.1主要变化包括:
微调优化: 通过在特定条件下进行微调,提高了视频输出的一致性和质量。
改进的生成性能: 在生成视频的清晰度、分辨率以及帧数方面可能有所改进,提供更为流畅和高质量的视觉体验。
固定条件下的性能提升: 通过在固定条件下进行微调,SVD1.1在特定设置下展现出比先前版本更优的性能。这包括更好的运动一致性和视觉效果,同时保持了条件的可调整性,以适应不同的应用需求。
适应性和局限性:模型的生成视频较短,可能存在一些局限性,如生成视频中可能没有运动或摄像机移动缓慢。建议模型仅用于研究目的,不适合用于生成真实人物或事件的内容。
这一版本的发布旨在提供更加稳定且高效的视频生成体验,使用户能够在不同的应用场景中更灵活地应用该模型。
0002
评论列表
共(0)条相关推荐
AI视频类工具又出黑马!Tonic可自动选择并转换视频中的片段
近日,一款名为Tonic的AI视频平台引起不少用户的关注,它在结合AI视频和内容消费方面表现出色。这一平台具有极低的视频AI转换成本,同时呈现出卓越的效果。Tonic的独特之处在于,它能够自动选择并转换视频的一小段,实现与原视频内容的完美融合。下载地址:https://apps.apple.com/cn/app/tonic-ai-video-editing/id6448806466站长网2023-12-20 11:09:560000被低估的AI生成PPT工具——Decktopus:内置表单收集、语音录制等功能
Decktopus是一种全新的在线演示工具,让您在最短的时间内打造完美的演示,而无需任何设计技巧。它利用人工智能丰富您的演示文稿,并为您提供图像和图标建议,使您无需花费数小时浏览库存照片网站。只需点击一个按钮,Decktopus就能为您找到所需的素材。站长网2023-08-15 15:10:340000国产开源MoE指标炸裂:GPT-4级别能力,API价格仅百分之一
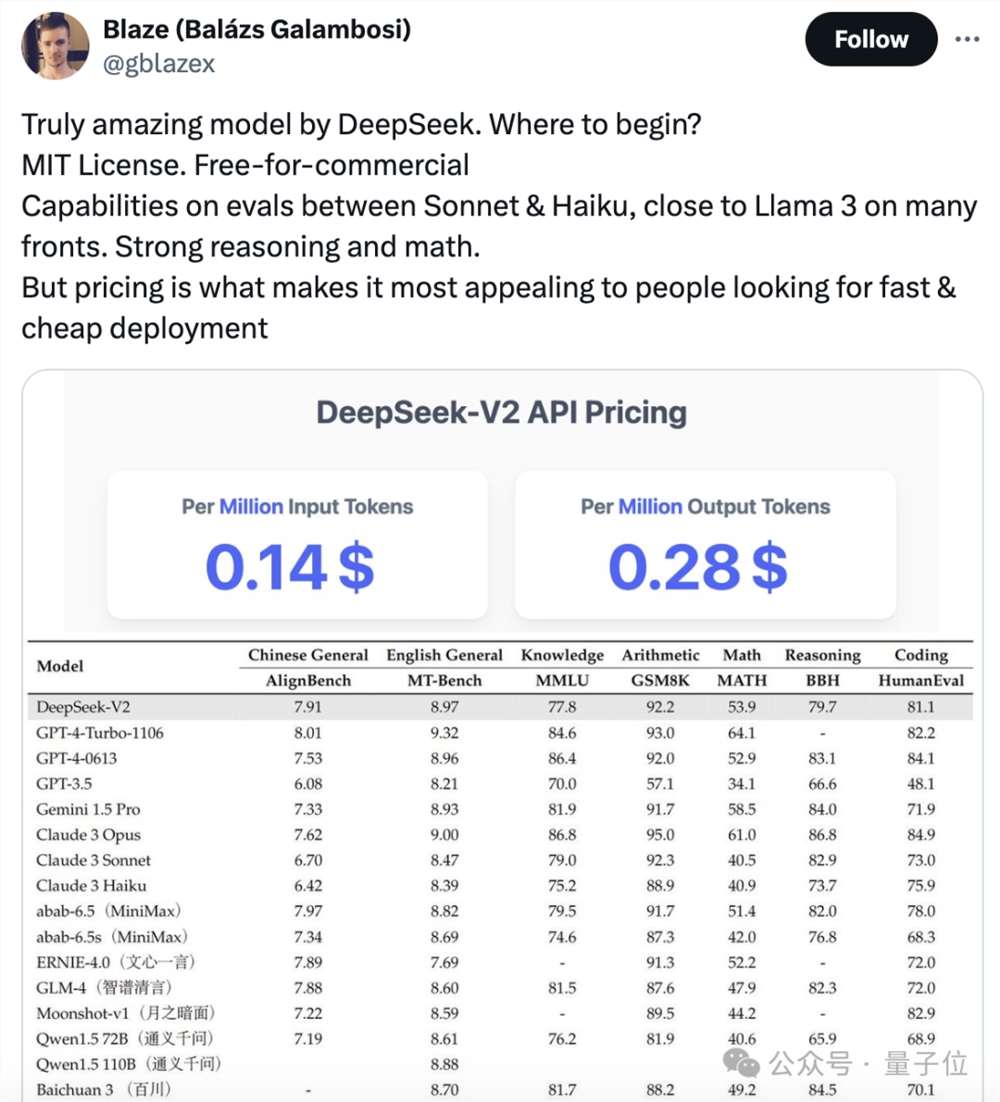
最新国产开源MoE大模型,刚刚亮相就火了。DeepSeek-V2性能达GPT-4级别,但开源、可免费商用、API价格仅为GPT-4-Turbo的百分之一。因此一经发布,立马引发不小讨论。从公布的性能指标来看,DeepSeek-V2的中文综合能力超越一众开源模型,并和GPT-4-Turbo、文心4.0等闭源模型同处第一梯队。站长网2024-05-08 07:15:070001高通激进!骁龙8 Gen4定版:超大核飙至4.32GHz 远高于A18 Pro
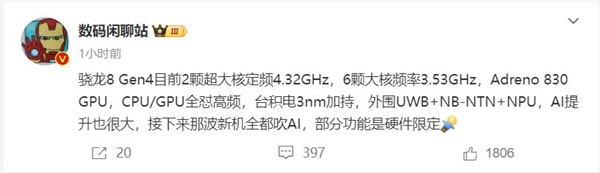
快科技9月11日消息,数码闲聊站爆料,高通骁龙8Gen4的两颗超大核频率最终敲定为4.32GHz,6颗大核的频率最终锁定为3.53GHz,对比上代的3.3GHz提升巨大,同时高于苹果A18Pro的4.04GHz。根据Geekbench公布的跑分数据,骁龙8Gen4的单核成绩是3236,多核成绩是10049,作为对比,A18Pro单核成绩是3018,多核成绩是7751。站长网2024-09-12 03:53:010000StopNCII 帮助打击 AI 生成的裸照
本文概要:1.StopNCII是一个全球可用的在线平台,帮助受害者解决被AI生成的深度伪造色情照片问题。2.通过上传原始和修改版本的照片,StopNCII确保修改后的图像从所有在线平台中被删除。3.StopNCII使用哈希生成技术为图像创建安全的数字指纹,确保原始图像保留在用户的设备上。站长网2023-08-08 17:07:360006