蚂蚁集团CodeFuse-VLM开源 支持多模态多任务预训练/微调
站长网2024-02-05 16:39:370阅
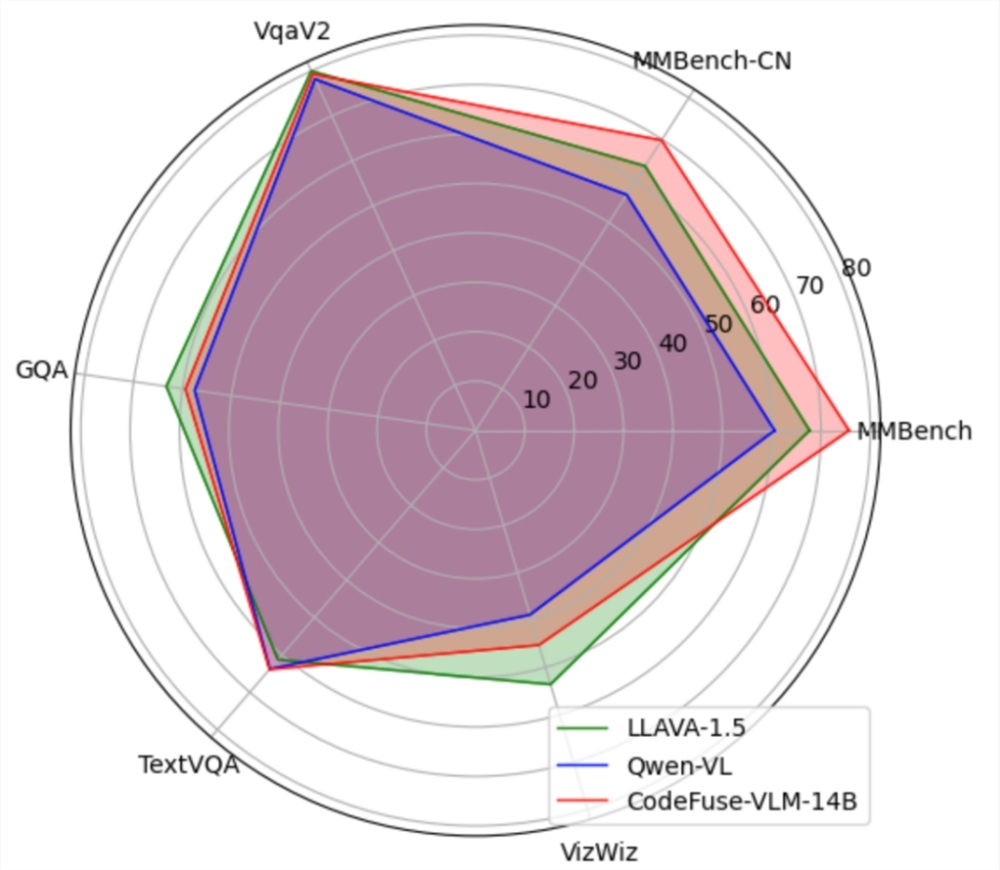
CodeFuse-VLM是一个支持多种视觉模型和语言大模型的框架,用户可以根据自己的需求搭配不同的Vision Encoder和LLM。
CodeFuse-VLM-14B模型在多个通用和代码任务上的性能超过LLAVA-1.5和Qwen-VL。
该框架还支持高效的PEFT微调,能有效提升微调训练速度并降低对资源的需求。
此外,CodeFuse-VLM还被用于训练网页图片到前端代码的多模态大模型,提高了前端工程师的开发效率。
CodeFuse-MFT-VLM 项目地址:
https://github.com/codefuse-ai/CodeFuse-MFT-VLM
CodeFuse-VLM-14B模型地址:
https://modelscope.cn/models/ss41979310/CodeFuse-VLM-14B/files
0000
评论列表
共(0)条相关推荐
谷歌 I/O 公布的人工智能布局让两位创始人财富飙升
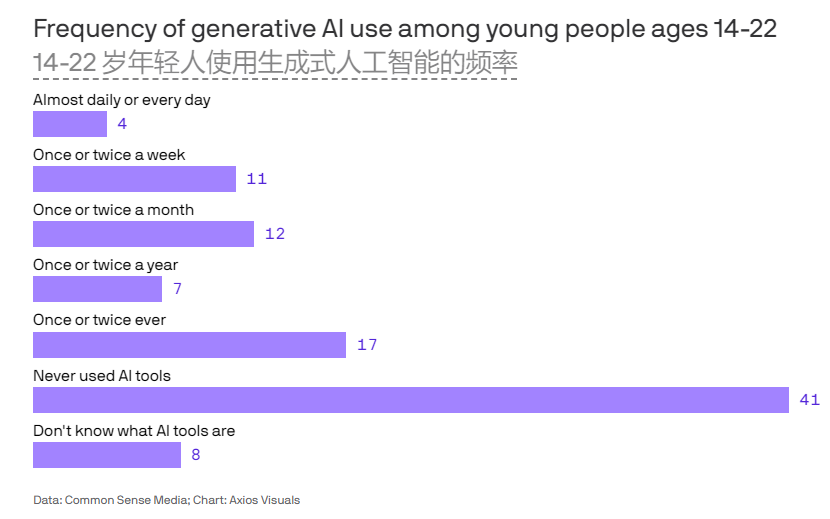
Alphabet公司的联合创始人拉里·佩奇和谢尔盖·布林因旗下谷歌公司的人工智能热潮而财富大幅增长。上周,谷歌在年度开发者大会GoogleI/O上推出了重新设计的搜索引擎,该搜索引擎将AI聊天机器人的响应集成到搜索结果中,并使其聊天机器人更广泛地可用。站长网2023-05-15 11:54:210000调查:仅有4%青少年和年轻人几乎每天使用AI工具
划重点:-📊仅有4%的受访者称他们每天或几乎每天使用人工智能工具-📚AI的两种最常见用途是获取信息和头脑风暴-🌐41%的受访者预计未来10年人工智能将产生积极和消极影响站长网2024-06-03 20:16:330000点评微信更新的9个功能
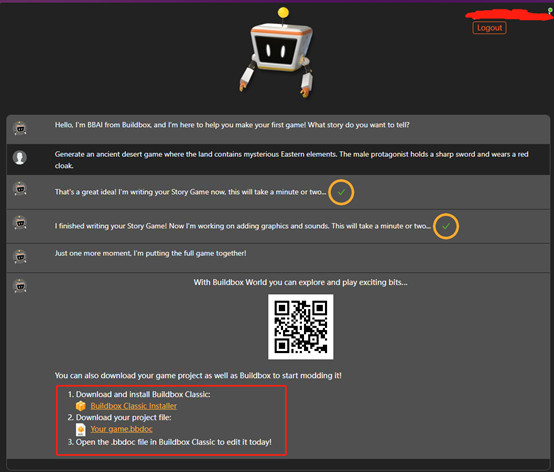
各位村民好,我是村长。以前微信每一次的改版都挺引发期待的,比如上线了红包、小程序、群聊免打扰、朋友圈折叠等。但是现在微信的每一次改版,都让人有种无奈和失望感,感觉微信越改越变成了一个大杂烩,逐渐抖音化、小红书、百度化。今天我们来简单盘点下,微信最近一些小功能的更新带来的影响。01公众号广告互选是鸡肋0000用ChatGPT方式开发游戏:文本直接生成小游戏,StoryGames.AI来了!
知名无代码游戏开发平台buildbox正式发布,集成生成式AI的游戏开发平台StoryGames.AI。用户只需文本提示,5分钟左右就能生成一个10章节的视频小游戏。(免费体验地址:https://storygames.buildbox.com/)站长网2023-08-22 14:14:340000没了工作的中年人,在咖啡馆假装上班
中年人有着太多不得不硬撑的坚强。“周一,星巴克几乎被失业的中年男女占满”,最近,社交平台上一则热帖引发广泛关注。图源/脉脉人到中年,往往在职场上发挥着中流砥柱的作用,在家庭中也扮演着赚钱主力军的角色。然而,就业环境瞬息万变,曾经的精英人士,也许转眼之间便光环不再。一些人为了不把失业的焦虑传递给家人,决定每天照常出门假装上班,把咖啡馆当作暂时的避难所。站长网2023-05-28 10:45:550000