谷歌提出全新RLHF方法:消除奖励模型,且无需对抗性训练
效果更稳定,实现更简单。
大型语言模型(LLM)的成功离不开「基于人类反馈的强化学习(RLHF)」。RLHF 可以大致可以分为两个阶段,首先,给定一对偏好和不偏好的行为,训练一个奖励模型,通过分类目标为前者分配更高的分数。然后通过某种强化学习算法优化这个奖励函数。然而,奖励模型的关键要素可能会产生一些不良影响。
来自卡内基梅隆大学(CMU)和 Google Research 的研究者联合提出了一种简单的、理论上严格的、实验上有效的 RLHF 新方法 —— 自我博弈偏好优化(Self-Play Preference Optimization,SPO)。该方法消除了奖励模型,并且不需要对抗性训练。

论文:A Minimaximalist Approach to Reinforcement Learning from Human Feedback
论文地址:https://arxiv.org/abs/2401.04056
方法简介
SPO 方法主要包括两个方面。首先,该研究通过将 RLHF 构建为两者零和博弈(zero-sum game),真正消除了奖励模型,从而更有能力处理实践中经常出现的噪声、非马尔可夫偏好。其次,通过利用博弈的对称性,该研究证明可以简单地以自我博弈的方式训练单个智能体,从而消除了不稳定对抗训练的需要。
实际上,这相当于从智能体中采样多个轨迹,要求评估者或偏好模型比较每对轨迹,并将奖励设置为轨迹的获胜率。
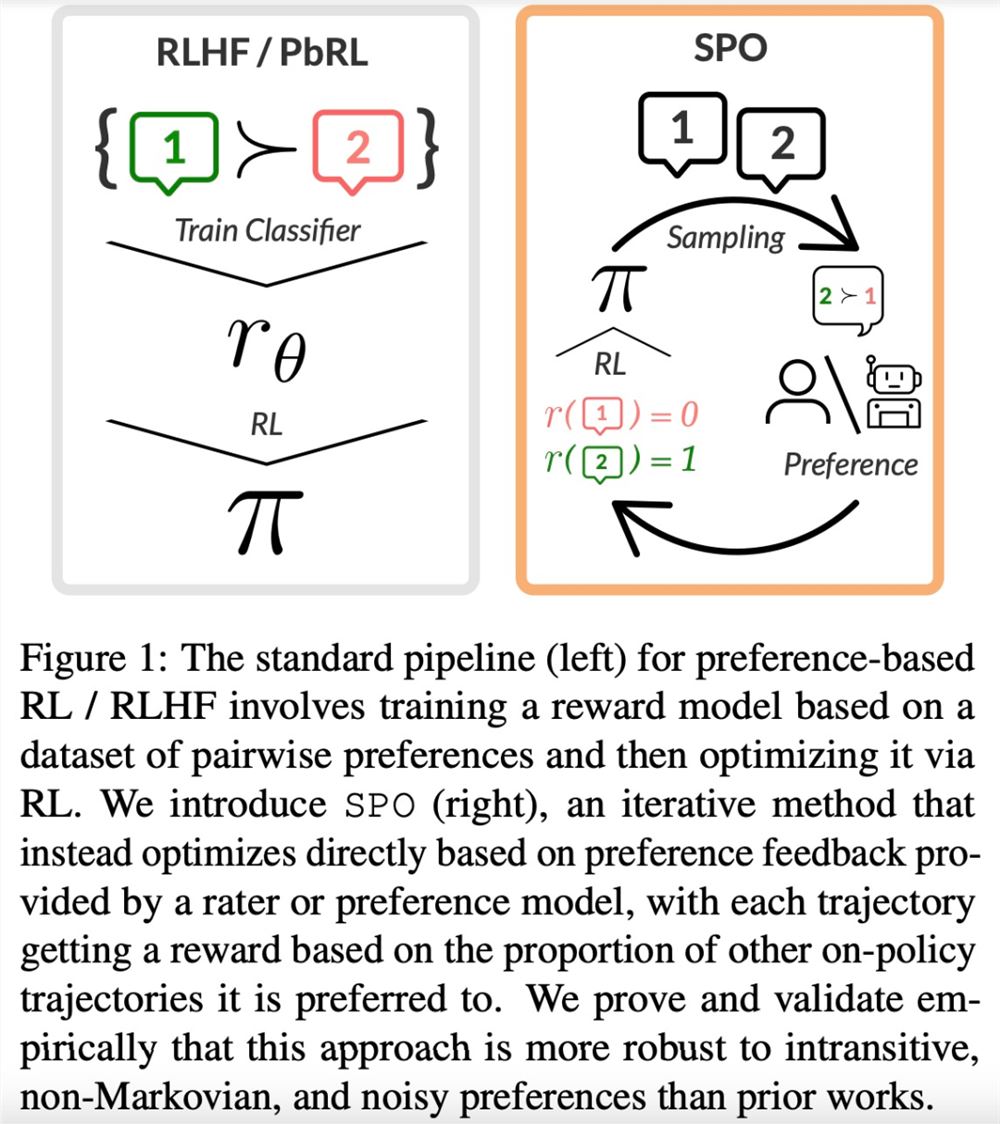
SPO 避免了奖励建模、复合 error 和对抗性训练。通过从社会选择理论(social choice theory)中建立最小最大获胜者的概念,该研究将 RLHF 构建为两者零和博弈,并利用该博弈支付矩阵的对称性来证明可以简单地训练单个智能体来对抗其自身。


该研究还分析了 SPO 的收敛特性,并证明在潜在奖励函数确实存在的情况下,SPO 能以与标准方法相媲美的快速速度收敛到最优策略。
实验
该研究在一系列具有现实偏好函数的连续控制任务上,证明了 SPO 比基于奖励模型的方法性能更好。SPO 在各种偏好设置中能够比基于奖励模型的方法更有效地学习样本,如下图2所示。
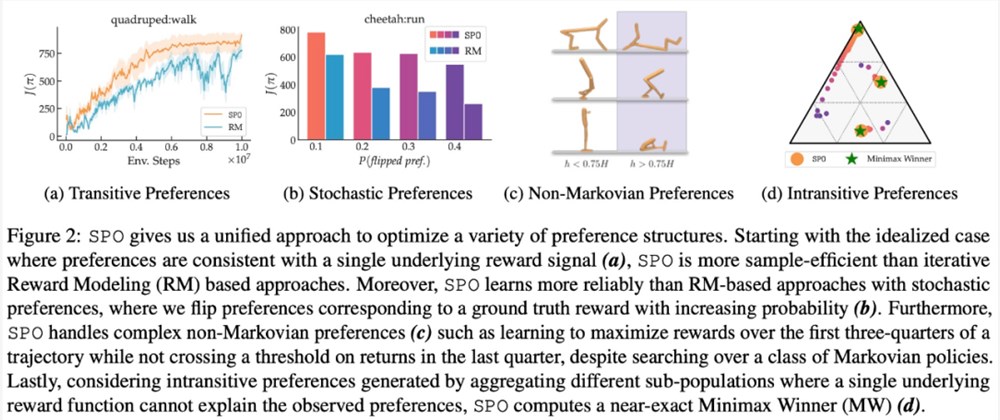

该研究从多个维度将 SPO 与迭代奖励建模 (RM) 方法进行比较,旨在回答4个问题:
当面 intransitive 偏好时,SPO 能否计算 MW?
在具有独特 Copeland Winners / 最优策略的问题上,SPO 能否匹配或超过 RM 样本效率?
SPO 对随机偏好的稳健性如何?
SPO 可以处理非马尔可夫偏好吗?

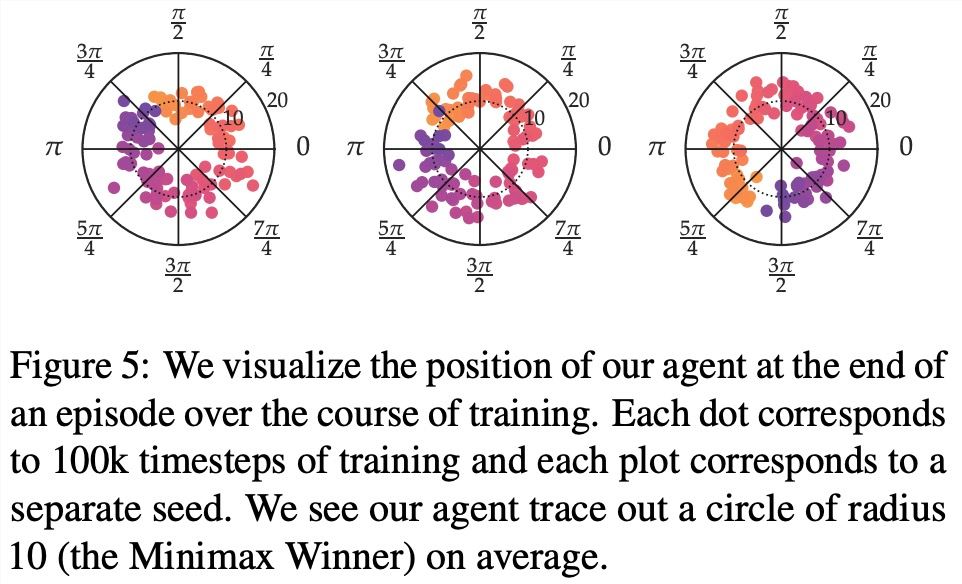
在最大奖励偏好、噪声偏好、非马尔可夫偏好方面,该研究的实验结果分别如下图6、7、8所示:
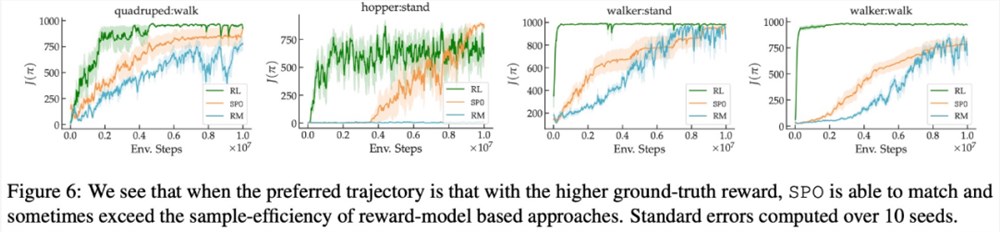
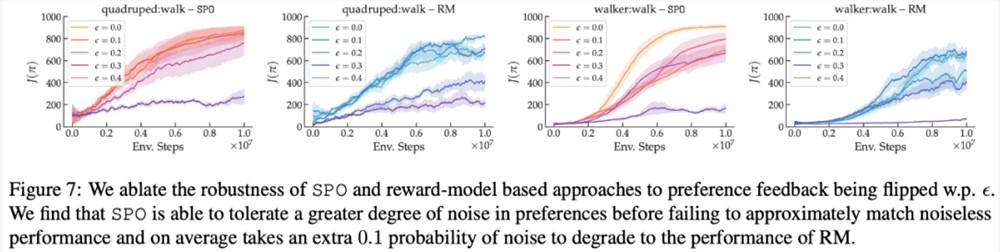
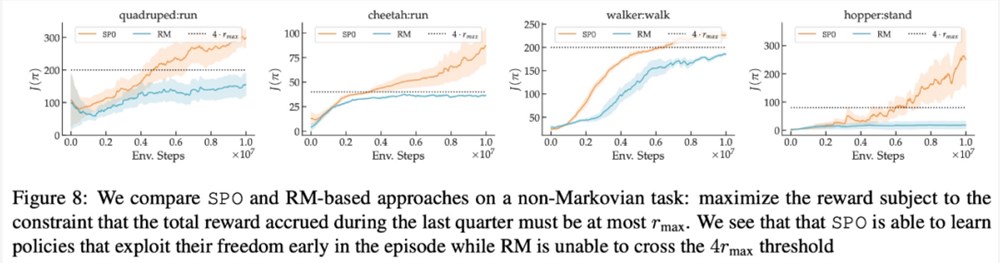
感兴趣的读者可以阅读论文原文,了解更多研究内容。
OpenAI 首席执行官与欧盟再度举行会谈 计划在欧洲建立新总部
据报道,OpenAI的CEOSamAltman将与欧盟进行进一步的会谈,并在欧洲大陆建立新的总部。Altman曾因批评欧盟的AI法案而引起轩然大波。站长网2023-06-02 11:58:240002AI创业要求剧变:拿到融资前必须先挣到钱
“现在投身AI领域的创业团队,能够试错的空间和次数,比几年前移动浪潮小多少?至少下降了80%~90%。早前风险投资容忍度非常高,投决也容易通过,但现在情况有一些变化。那现在AI领域创业,要特别注重什么?收入!必须要先挣到钱。”在和梅花创投创始合伙人吴世春电话讨论的过程中,我们聊起当下超级热度的AI领域创业和投资。如果要说感受,我们几乎听到了两方面感受最深:0002B站“亮底牌”,靠大开环直播导流打赢双11?
平台血拼低价,双11再起波澜,B站也在暗处悄悄使劲。9月,B站推出直播带货超新星计划,为UP主对接货源,持续开放各品类的招商。一个月后,B站陆续对外发布消息,称双11期间将为电商平台导流。站长网2023-11-06 17:11:470000入股、整合、价格战,量贩零食进入下半场
2023年,量贩零食成为最炙手可热的明星赛道之一。量贩零食行业发生多起融资,多起融资金额超过千万。一方面,量贩零食行业的行业竞争与整合加剧,赵一鸣零食与零食很忙合并,合并后门店总数突破6500家。行业规模位列量贩零食领域第一与第二的零食很忙集团与万辰集团的“商战”蔓延至社交平台,争夺加盟商,明面开战。站长网2024-02-18 15:52:230002詹姆斯·卡梅隆自曝:新终结者电影剧本由ChatGPT写,天网大结局,AI自己定
詹姆斯·卡梅隆透露,未来将会以ChatGPT为主角拍一部终结者电影。现在打开豆瓣,1984年10月上映的那部「终结者」评分依然在8分以上。而后,终结者系列的电影不断上新,直到2019年,还在有同款ip的电影上映。当然,终结者系列只有前两部是由詹姆斯·卡梅隆执导的。现在,随着AI之风彻底席卷我们的星球,老詹打算重操旧业,拍一部有关GPT的「终结者」电影。站长网2023-05-30 09:11:210000