OpenAI公布Sora技术报告:模拟世界、视频扩展等,强的离谱!
昨天,OpenAI发布的首个文生视频模型Sora,成功霸屏全球科技媒体头条,其逼真的细节、连贯的视频动作以及精准的文本语义还原令人咋舌。
不少媒体、科技大咖和影视导演指出,Sora的出现不仅一夜让深耕该领域的Runway、Pika、Stability.ai等头部企业黯然失色,就连影视行业都可能一起颠覆。
今天「AIGC开放社区」根据OpenAI公布的技术报告,为大家深度的解读一下Sora的技术原理,以及那些前所未有的超强视频功能。
报告地址:https://openai.com/research/video-generation-models-as-world-simulators
为什么其他模型,很难生成4秒以上的高质量视频
我们先思考一个非常重要的问题,文生视频领域的AI工具那么多,技术迭代也折腾了好几年,为什么无法像Sora那样,一次生成超过4秒甚至1分钟的高质量视频?
下面这个视频是昨天OpenAI公布的一个悬崖拍摄视频,我们将相同的提示词放在Runway的Gen-2中生成视频,并进行了详细的对比。

大家看到了,在彩色饱和度、通透度、视频运动轨迹速率、文本语义还原等方面,Sora是完全碾压Gen-2。
下面这个是刷爆全网的Sora生成中国龙的视频,同样与Gen-2做了对比依然完败,这样的例子还有很多。
限制Gen-2等产品生成高质量长视频的一个重要原因就是缺少——高质量训练数据。
文生视频模型需要大量的视频数据进行训练,包含各种场景、人物、动作、物品等,以帮助模型学习视频的生成规律和运动轨迹等重要元素。
目前公开的视频数据集,例如 Kinetics、HMDB51、Charades等,视频长度都比较短,一般只有几秒钟,并且搜集视频训练数据的难度是文本的好几倍,高质量数据更是难上加难。
大模型的根本原理就是通过模仿然后进行二次创新,所以,训练数据那么短,模型也很难模仿创作更长的视频。
昨天就有科技大咖指出,Sora可能使用了虚幻引擎5合成的游戏视频训练数据,从视频的色彩、细节来看这个判断是靠谱的。
这样看来OpenAI手里已经掌握了一批高质量视频训练数据,同时找到了新的高效数据合成方法。
此外,在训练方法、模型架构、算力需求等方面,Sora也进行了创新将ChatGPT、DALL·E3等模型融合在一起。
Sora可以模拟世界
由于Sora的技术原理比较枯燥,我们放在后面说,先从Sora的超强视频功能说起吧。
OpenAI发现,Sora在经过大规模训练后,会表现出许多有趣的新能力,能够模拟物理世界中的人、动物和环境的某些方面。这些特性的出现并没有对3D、物体等产生任何明确的归纳偏差,纯粹是规模现象。
3D一致性:Sora 可以生成摄像机动态运动的视频。随着摄像机的移动和旋转,人物和场景元素在3D空间中的移动会保持一致。
长距离一致性和对象持久性,是生成高质量长视频的一个重大挑战。OpenAI表示,Sora 经常(并非总是)能够有效地模拟短距离和长距离依赖关系。例如,即使人、动物和物体被遮挡或离开画面,也能保持它们的存在。
此外,Sora还能在单个样本中生成同一角色的多个镜头,并在整个视频中保持其外观。
与物理世界产生互动,Sora有时可以模拟一些影响世界状态的简单动作。例如,画家可以在画布上留下新的笔触,并随着时间的推移而持续;或者一个人在吃一个汉堡时,留下咬痕。
模拟数字世界:Sora还能模拟人工操作流程,例如,在游戏“我的世界中”,Sora 可以通过基本策略控制 游戏中的玩家,同时高保真地呈现世界环境以及动态。
OpenAI也指出了Sora模拟的局限性,例如,不能准确地模拟许多基本交互的物理现象,如玻璃碎裂,并不总能产生正确的物体状态变化。
但从更长远的角度来看,继续扩大Sora的训练数据规模,是开发物理、数字世界以及元宇宙的一种高效模拟手段,可以近乎真实地来还原物体、动物和人等。
视频连接功能
Sora 可以在两个输入视频之间逐步插值,并在主题、场景构成完全不同的视频之间创建无缝过渡。简单来说,就是Sora具备无缝视频剪辑连接,这对于影视行业来说帮助很大。
OpenAI在展示Sora的视频连接功能时,使用了三个20秒的案例:一个飞行的无人机,无缝变成了一只蝴蝶,然后场景切换到海底世界。整个流程非常丝滑,感觉就像人工剪辑的一样。

「AIGC开放社区」将这三个视频整合到了一起,大家可以感受一下。
扩展生成视频
Sora 还能向前或向后多个维度扩展视频。OpenAI举了3个视频案例,它们都是从一段生成的视频开始向后延伸的,所以,这3段视频的开头都与其他视频不同,但结尾都是一样。
视频剪辑
扩散模型为文本提示,编辑图像和视频提供了大量方法。于是,OpenAI将把其中一种方法 SDEdit32应用在了Sora。这使得 Sora 可以在0拍摄的情况下,转换输入视频的风格和环境。
例如,一辆在森林中飞奔的跑车,可以瞬间改成赛博朋克的视频画面。这个功能其实就是一键滤镜 环境修改。说起来很简单,但在技术层面相当有难度。
通过图像、视频进行生成提示
除了文本之外,Sora还能通过图像、视频的方式生成视频。例如,输入一张图像,一只戴着贝雷帽和黑色高领毛衣的柴犬,然后就能制作视频。

生成图像能力,
Sora是一个文生视频模型,但同样具备生成图像能力,这个创新属于业内第一家。
Sora可以生成不同大小,分辨率高达2048x2048的图像
例如,充满活力的珊瑚礁,有色彩缤纷的鱼类和海洋生物

苹果树下有一只可爱的小老虎,哑光绘画数字风格,细节华丽

Sora技术原理以及“视频补丁”
说完了Sora一堆超强功能,我们唠唠它的技术原理。
衣服破了一个洞怎么办?通常的方法是打一个补丁,然后缝缝补补又穿3年。
同理,OpenAI从大语言模型ChatGPT领悟到了灵感:大模型可以生成各种细化文本内容,主要得益于精准的数据标记,统一了文本代码、数学和各种自然语言的不同模式。
既然大模型有文本标记,那Sora当然也可以有“视频补丁”啊。OpenAI发现,视频补丁是一种高度可扩展且有效的表示形式,可用于在不同类型的视频和图像上训练生成模型。
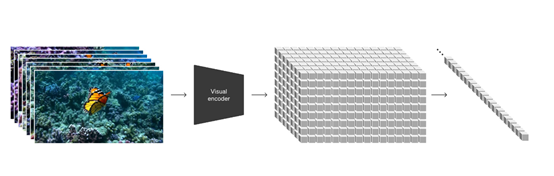
在较高维度上,OpenAI首先将视频压缩到低维潜在空间中,然后将其分解为时空补丁,从而将视频转化为补丁。
视频压缩网络:OpenAI训练了一个降低视觉数据维度的网络。该网络将原始视频作为输入,并输出在时间和空间上压缩的潜在表示。
Sora 在这个压缩的潜在空间中接受训练,并随后生成视频。同时还训练了相应的解码器模型,将生成的潜伏映射回像素空间。
时空潜伏斑块:给定一个压缩输入视频,OpenAI提取了一系列时空补丁作为转换标记。基于补丁的表示法,使 Sora 能够在不同分辨率、持续时间和长宽比的视频和图像上进行训练。
在推理时,可以通过在适当大小的网格中排列随机初始化的补丁,来控制生成视频的大小。

模型架构:Sora是一个扩散模型在给定输入噪声补丁,被训练来预测原始的“干净”补丁。此外,Sora 和ChatGPT一样使用了Transformer 架构,在语言建模、计算机视觉以及图像生成等方面非常优秀。
改善构图:OpenAI发现,在原始长宽比的视频上进行训练,可以极大改善构图和取景,并将 Sora 与所有训练视频裁剪成正方形的模型版本进行了比较,取景效果获得了极大的改善。

右图为Sora生成全景视频。
精准文本语义理解:训练视频模型需要大量,带有相应字幕的视频。OpenAI将DALL·E3的重新字幕技术引入到了Sora。首先训练一个高度描述性的字幕模型,然后用它为训练集中的所有视频制作文本字幕。
OpenAI表示,在高度描述性的视频字幕上进行训练,可提高文本的保真度以及视频的整体质量。
与 DALL-E3一样,OpenAI也通过 GPT 将简短的用户提示转化为较长的详细字幕,并发送给视频模型。这使得 Sora 能够精准地还原用户的文本提示,生成高质量的长视频。

从这份技术报告来看,Sora更像是OpenAI的技术大集合,使用到了很多ChatGPT、DALL·E3以及之前积累的技术沉淀,也是Sora能呈现出那么多超强视频技术的原因。
让我们一起期待Sora公测、开放API的那一天吧,万一开源了呢~
李飞飞「数字表兄弟」破解机器人训练难题!零样本sim2real成功率高达90%
【新智元导读】在用模拟环境训练机器人时,所用的数据与真实世界存在着巨大的差异。为此,李飞飞团队提出「数字表亲」,这种虚拟资产既具备数字孪生的优势,还能补足泛化能力的不足,并大大降低了成本。如何有效地将真实数据扩展到模拟数据,进行机器人学习?最近,李飞飞团队提出一种「数字表亲」的新方法,可以同时降低真实到模拟生成的成本,同时提高学习的普遍性。0000马云成立马家厨房公司 经营范围含销售预制菜
最新工商信息显示,11月22日,由马云持股99.9%的杭州大井头贰拾贰号文化艺术有限公司新增一家子公司,主营预制菜、农产品加工和批发等。该子公司名为杭州马家厨房食品有限公司,法定代表人为PAUJASONJOHN,注册资本1000万人民币,经营范围包括食品销售(仅销售预包装食品)、货物进出口、食用农产品批发、日用品批发、酒店管理、技术服务等。站长网2023-11-24 08:27:550000终于!马斯克 Neuralink 获得 FDA 批准,可首次进行人体实验
去年12月,马斯克曾放话:预计脑机接口公司Neuralink将在6个月后,进行大脑芯片的人体试验。彼时,回想起这些年来马斯克在特斯拉、SpaceX上不断“画饼”的行为,许多人对于“6个月”这个说法,不过笑笑而已——可没想到,这个Flag居然真的成了!本周五,Neuralink官方激动发推:“很高兴地告诉大家,我们已获得FDA的批准,可以启动我们的首次人体临床研究!”站长网2023-05-27 10:11:200001MChat:基于孟子GPT的专业、可控的生成式AI系统
孟子GPT是一个面向生成场景的可控大语言模型,能够帮助用户完成特定场景中的多种工作任务。MChat是一个在线试用的AI对话机器人,利用孟子GPT技术实现对话。它能够进行内容创作、多语言翻译、知识问答、金融场景任务等多种能力。体验地址:https://www.langboat.com/portal/mengzi-gpt站长网2023-08-31 16:52:340000OpenAI的 GPT-4.5 Turbo意外曝光,可能于 6 月发布
划重点:-💡OpenAI的GPT-4.5Turbo被泄露,搜索引擎如Bing和DuckDuckGo在官方公告前索引了产品页面。-💡GPT-4.5Turbo被描述为OpenAI迄今最快、最准确、最可扩展的模型,具有256,000个token的上下文窗口。-💡据传言,GPT-4.5Turbo可能具有视频或3D功能,但泄露的信息并未提及。站长网2024-03-13 10:50:250000