研究表明:大语言模型从人类反馈中学得更快更智能
划重点:
1. 🧠 大型语言模型(LLMs)通过在线上下文学习展现了广泛的机器学习能力,使非专家能够通过语言指令编写机器人代码,根据反馈修改行为或组合执行新任务。
2. 🔄 通过Language Model Predictive Control(LMPC)框架,研究团队成功通过对机器人代码编写LLMs进行微调,提高其适应人类输入的效率,从而加速学习过程。
3. 🤖 实验证明,LMPC不仅提高了未见任务的成功率,还通过优化适应性和响应性,为多轮对话中的机器人适应性学习提供了强大支持。
近期研究表明,大型语言模型(LLMs)在通过在线上下文学习方面表现出许多强大的能力,其中包括从语言命令中编写机器人代码的技能。这使得非专家用户能够直接指导机器人行为,根据反馈进行修改,甚至组合行为以执行新任务。然而,这些能力主要限于短期交互,因为用户的反馈只在LLM上下文大小范围内保持相关,且在较长时间的交互中可能被遗忘。
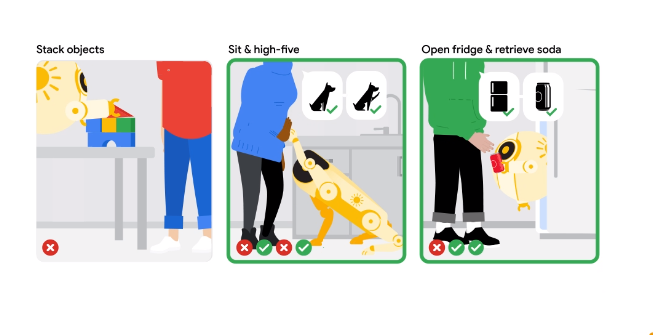
为了解决这一问题,研究团队着手对机器人代码编写LLMs进行微调,以记住其上下文交互并提高其可教学性,即它们对人类输入的适应效率(以用户认为任务成功之前的平均更正次数为度量)。
研究观察到,当将人机交互形式化为部分可观察的马尔科夫决策过程时(其中人类语言输入是观察值,而机器人代码输出是动作),训练LLM以完成先前的交互可以被视为训练一个过渡动态模型。这个模型可以与经典的机器人技术结合使用,如模型预测控制(MPC),以发现通往成功的更短路径。这就是Language Model Predictive Control(LMPC)框架的产生,通过对PaLM2进行微调,它在5个机器人实体上的78个任务中提高了未见任务的非专家教学成功率,同时将人类更正的平均次数从2.4降低到1.9。
LMPC的成功在于其对用户教学新任务的成功率提高了26.9%,同时在未见机器人实体和API上的实验中,通过提高上下文学习新任务的成功率,提高了31.5%。通过LMPC-Rollouts和LMPC-Skip这两个变体,研究团队加速了机器人通过上下文学习进行快速适应的能力。实验证明LMPC-Rollouts在多轮对话中更具通用性,对于首次响应不正确的反馈更易于纠正。为了最大程度地提高实际性能,研究建议使用LMPC-Skip来响应初始用户指令,然后使用LMPC-Rollouts来响应后续用户反馈。
研究团队在78个机器人任务中进行了实验,覆盖了5个机器人实体的模拟环境和2个真实硬件实体。实验中探讨了微调策略对在线上下文学习的影响,包括提高教学效果、LMPC-Rollouts和LMPC-Skip的比较、Top-User Conditioning的好处、微调是否实现跨机器人实体的泛化以及迭代微调是否进一步提高可教学性。
在真实世界中,研究团队对移动操纵器和机器狗的子集任务进行了评估,要求用户直接在真实机器人上进行四次教学会话。结果显示,LMPC-Rollouts在所有任务上的成功率均高于PaLM2-S。尽管在这些任务上,PaLM2-S和LMPC-Rollouts的成功会话的平均聊天轮次大致相同,但LMPC-Rollouts取得了更高的成功率。
通过实际演示,研究团队展示了他们的系统如何教授多个机器人实体复杂的行为,同时还展示了在教学前后机器人行为的显著差异。这个创新的方法不仅在模拟环境中取得了显著成果,而且在真实机器人上也取得了令人瞩目的效果。

这项研究通过LMPC框架的应用,成功提高了机器人代码编写LLMs的可教学性,为人机交互中机器学习的快速适应性开辟了新的道路。
论文网址:https://robot-teaching.github.io/
大模型数据被盗第一案和解 笔神作文称不再对学而思发起诉讼
近日,笔神作文和学而思发布公告称,双方已经和解,笔神作文已于8月4日决定不再对学而思针对相关数据调取事件发起诉讼。据悉,经过深入调查和坦诚沟通,双方对有争议的条款已经达成一致,消除了误会,并将继续深化合作,共同推进AI技术在教育领域的探索。站长网2023-08-14 10:23:540000Midjourney 计划未来几个月推出“文本转视频”模型
**划重点:**1.🎥Midjourney计划在未来几个月推出“文本转视频”模型,将其AI形象生成器扩展到视频创作领域。2.🤖公司将于1月开始培训视频模型,CEODavidHolz表示这是平台的自然发展,将竞争动态引入生成视频行业。3.🌐与竞争对手相比,MidJourney的最新v6更新着重于提高画质和用户体验,预示着AI视频生成领域的激烈竞争。站长网2024-01-03 14:12:150000微信再一次切断了抖音外链(微信切断抖音外链)
微信再一次切断了抖音外链,看来阿里已经不是腾讯的主要威胁了,字节跳动才是。抖音微信外链互通一年后再次被切断,来自第一财经消息,抖音的链接在微信里无法打开了,也无法复制完成跳转,只能通过图片OCR识别进行文字提取,APP间壁垒又现。微信官方昨晚深夜回应,切断抖音外链,是为了保护用户不被骚扰,保护隐私安全。但微信内淘宝链接仍可以复制并进行跳转,看来抖音对微信的生态影响太大了。站长网2023-01-13 22:28:2800011微信盘点2024年度朋友圈十大热度谣言:点早安图片手机会中毒是假的
快科技12月30日消息,2024年即将收官,今日,微信安全中心发文盘点2024年度朋友圈热度谣言。朋友圈热度十大谣言如下,看你看到过几个。点早安”晚安”图片手机会中毒有网友在网上发布以后不要再发送早安、晚安的问候图,接收之后会导致手机中毒个人信息被盗”的警告,引起广大网友的关注。真相:经核查,类似的谣言信息,属于陈年老谣言。针对此类谣言,多地的网信等部门,都曾经对此进行过辟谣。0000网信办等三部门确认目标:2024年末IPv6活跃用户数达到8亿
快科技4月20日消息,中央网信办、国家发展改革委、工业和信息化部近日联合印发《深入推进IPv6规模部署和应用2024年工作安排》。明确以下工作目标:到2024年末,IPv6活跃用户数达到8亿,物联网IPv6连接数达到6.5亿,固定网络IPv6流量占比达到23%,移动网络IPv6流量占比达到65%。IPv6网络性能显著提高,使用体验提升明显。0000