谷歌开源Gemma:参数小、性能超越Llama2,可轻松在笔记本上运行
划重点:
1. 💻 Gemma是谷歌开源的大语言模型,性能强悍,可商用。采用Gemini架构,有20亿、70亿参数版本,测试显示在数学、推理、代码方面超过Llama-2。
2. 🚀 Gemma支持普通笔记本、台式机运行,无需庞大的AI算力。开发者可通过Kaggle、Hugging Face等平台获取模型,同时谷歌提供详细的开发者指南和Responsible Generative AI Toolkit。
3. 🌐 Gemma优化跨框架、设备、硬件,支持多框架工具、跨设备兼容性、高级硬件平台,与NVIDIA合作优化,适用于Google Cloud。性能测试表明Gemma在主流平台上表现优异,是一款参数小而性能强大的大模型。

谷歌于2月22日宣布开源大语言模型Gemma,成为其生成式AI领域的新力量。Gemma采用Gemini架构,有20亿、70亿两个版本,分别支持预训练和指令微调。
据谷歌公布的测试结果显示,Gemma70亿模型在数学、推理、代码方面的能力超过了Llama-2的70亿和130亿,成为小参数类ChatGPT模型中最强的之一。
最令人振奋的是,Gemma不仅性能强大,而且可商用,并且轻松在普通笔记本、台式机上运行,无需庞大的AI算力。这使得开发者可以更加便捷地应用Gemma模型,而Kaggle和Hugging Face等平台也提供了方便的获取途径。同时,为了帮助使用Gemma的开发者更安全地构建AI应用程序,谷歌推出了Responsible Generative AI Toolkit等一系列工具。
Gemma的优势不仅在于性能和可用性,还体现在其全面的优化。谷歌强调,开发者可以在多框架工具中进行推理和微调,跨设备兼容性也是Gemma的一大特色,支持笔记本电脑、台式机、物联网、移动设备和云等多种设备类型。与NVIDIA的合作使得Gemma在GPU优化上表现出色,涵盖了从数据中心到云端再到本地RTX AI PC的多个硬件平台。

对于使用Google Cloud的开发者,Gemma同样得到了优化。Vertex AI提供全面的MLOps工具集,支持一键式部署,并具有内置推理优化功能。高级定制功能通过完全管理的顶点人工智能工具或自我管理的GKE实现,包括部署到GPU、TPU和CPU平台上具有成本效益的基础设施。
谷歌通过Gemma的性能测试展示了其在主流平台中的优越表现,尤其在数学、推理、代码等方面的标准学术基准测试平均分数都高于同规模的Llama2和Mistral模型。这表明,Gemma作为一款参数相对较小但性能异常强大的大模型,将为开发者提供更灵活、高效的AI应用解决方案。
项目入口网址:https://top.aibase.com/tool/gemma
技术报告:https://goo.gle/GemmaReport
百度全面收回快速收录和sitemap提交权限 仅面向VIP站点开放
站长之家(ChinaZ.com)12月6日消息:此前百度站长平台宣布2023年11月30日将回收站点的“快速收录”和“Sitemap提交”权限,此举是为了全面升级搜索资源平台的权益体系。根据百度在12月1日发布的公告《热点问题追踪之消失的权益》,这一决定与使用《站长推送工具》无关。站长网2023-12-06 09:30:430000俞敏洪应该学黄峥
停播6天后,8月1日下午,东方甄选自营产品店终于复播。复播前,东方甄选自营产品店专门在抖音发了一条澄清视频,视频中,CEO孙东旭直言,“大可不必”担心东方甄选和抖音的关系,“和平台的沟通一直顺畅”。但不可否认的是,在独立APP上开启首播后,东方甄选与平台的关系已经变得微妙——至少在外界看如此。而在东方甄选高调在自营APP开启连续三天8.5折促销之后,两者的关系恐怕就更为复杂了。站长网2023-08-06 10:41:190000从市值风云败诉被判赔201万,谈自媒体该如何“报道企业”
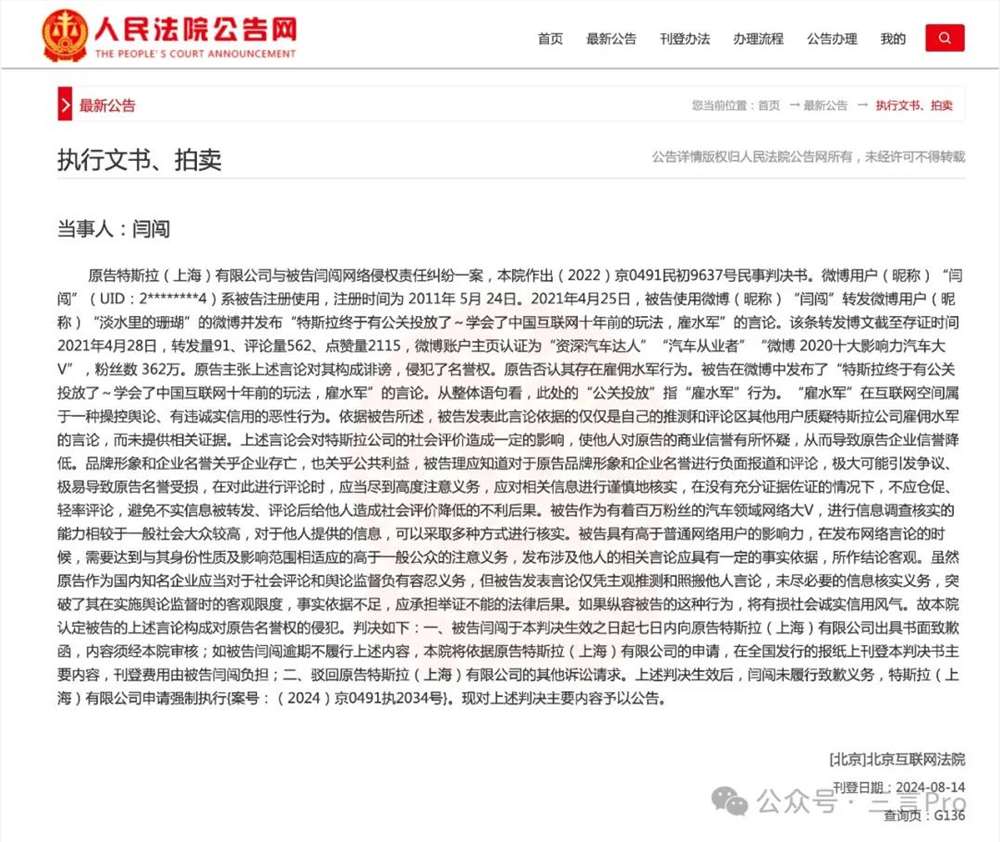
近期,有多起企业诉自媒体胜诉、自媒体败诉需赔偿的消息,涉及360、特斯拉、联想、小米等企业,且企业起诉自媒体有继续多发的态势。有必要分析下这些案例,看看他们为什么败诉、金额判决依据是什么。市值风云一审败诉360判赔偿对方201万今日,360诉自媒体市值风云一审判决书公布。站长网2024-09-01 14:08:230000许多几百万美食账号停更了
各位村民好,我是村长。抖音上,有许多几百万粉丝的做菜美食账号都停更了。而他们停更,主要的原因就是不赚钱。今天我们就和大家一起来聊一聊,关于在家做美食、菜谱这个赛道。图源备注:图片由AI生成,图片授权服务商Midjourney01美食做菜一直有人看为什么在抖音上,有这么多的做菜账号,不停地冒出来。站长网2024-05-30 09:51:520000阿里巴巴:与微信支付合作的潜在用户增量空间很大
快科技11月16日消息,今年9月份,淘宝、微信支付正式拆墙”,可以在淘宝支付页面选择微信支付付款。这意味着阿里巴巴、腾讯的互联互通有了重大进展,从之前的封闭的体系逐步走向开放。阿里巴巴CEO吴泳铭在Q2财报发布后的会议上谈到了此事,称随着微信支付”功能的接入,我们对新用户增长还是有比较大的期待”。0000