Stable Diffusion 3突然发布!与Sora同架构,一切都更逼真了
Stable Diffusion3,它终于来了!

足足酝酿一年之多,相比上一代一共进化了三大能力。
来,直接上效果!
首先,是开挂的文字渲染能力。
且看这黑板上的粉笔字:
Go Big or Go Home(不成功便成仁),这个倒是杀气腾腾啊~
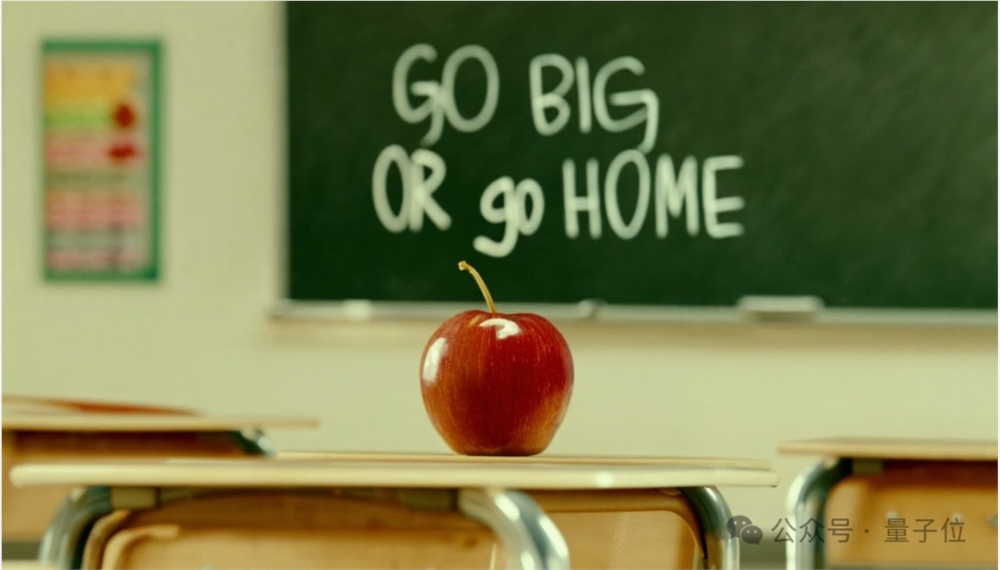
路牌、公交灯牌的霓虹效果:

还有刺绣上“勾”得快要看到针脚的“晚安”:

作品一摆出,网友就大呼:太精确了。

以至于有人表示:赶紧把中文也安排上啊。

其次,多主题提示能力直接拉满。
什么意思?你尽管一次性往提示词中塞入n多“元素”,Stable Diffusion3:漏一个算我输。
呐,仔细瞅下图,这里面就有“宇航员”、“穿着芭蕾舞裙的小猪”、“粉色雨伞”、“戴着礼帽的知更鸟”,角落里还有“Stable Diffusion”几个大字(可不是什么水印)。

有了这个能力,一幅作品你想多丰富就有多丰富。
最后,当属图像质量,再次进化了一个度。
光看前面这些图,就被冲击到有没有?!
而各种超清特写,那是再信手拈来不过的了。

心动吗?目前官方已开放排队名单,大伙可以前往官网申请。
咳咳,也不得不说,最近这AI圈可真是相当热闹啊。
有网友直呼,我的电脑已经Hold不住了……
Stable Diffusion3来了!
全新的Stable Diffusion效果有多好,再给大伙奉送一些。
当然,所有出图均来自官方,比如StabilityAI媒体负责人:

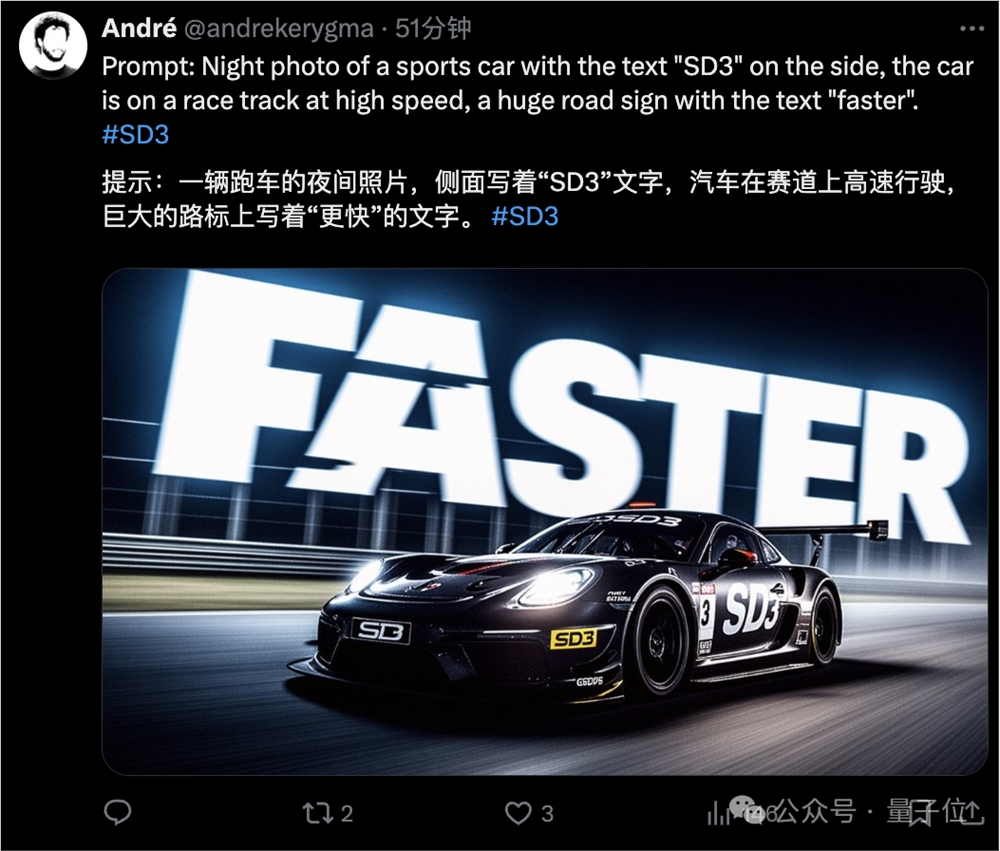
不得不说,文字效果实在最为吸人眼球,各种形式都能呈现得相当清楚和“应景”。

而看到上面这幅图,不得不想到“Midjourney尴尬亮相学术界:为生物学论文乱配图”一事——有了SD3之后,我们是不是可以制作非常专业的学术配图了?
除了这些,SD3的“酒精水墨画”也相当别出心裁:

动漫风格:
again,你可以在上面加清晰的文字了。

由于目前需要排队申请,大伙还不好实际测试摸底。
不过有机智的网友已经用相同的提示词喂给了Midjourney(v6.0)。
比如开头的那张“红苹果与黑板字”(prompt:cinematic photo of a red apple on a table in a classroom, on the blackboard are the words “go big or go home” written in chalk)
最终Midjourney给出的结果如下:


从这组对比来看,可以说是高下立判——SD3无论是文字拼写还是质量、色彩协调性等方面都更胜一筹。
官网入口:https://top.aibase.com/tool/stable-diffusion-3
技术方面,目前,模型可选择的参数范围在800M到8B。
详细的技术报告还未公布,官方目前只透露主要结合了扩散型transformer架构以及flow matching。
前者实际上同Sora一样,附上的技术论文正是22年William Peebles同谢赛宁合写的DiT。

DiT首次将Transformer与扩散模型结合到了一起,相关论文被ICCV2023录用为Oral论文。
在该研究中,研究者训练了潜在扩散模型,用对潜在 patch进行操作的 Transformer 替换常用的 U-Net 主干网络。他们通过以Gflops衡量的前向传递复杂度来分析扩散 Transformer (DiT) 的可扩展性。
而后者flow matching同样也是来自22年,由Meta AI以及魏茨曼科学研究所的科学家完成。

他们提出了基于连续归一化流(CNFs)的生成模型新范式,以及flow matching的概念,这是一种基于回归固定条件概率路径的矢量场的免模拟CNFs的方法。结果发现使用带有扩散路径的flow matching,可以训练出来的模型更稳健和稳定。
不过最近看了这么多视频生成进展,也有网友表示:

你觉得呢?
One More Thing
除此之外,也就在前一天,他们的视频产品Stable Video正式开放公测。
基于SVD1.1(Stable Video Diffusion1.1),人人可用。
主要支持文生视频和图生视频两个功能。

5G网络为何面临“叫好不叫座”局面 邬贺铨:用户感知差 运营商回报低
快科技4月20日消息,中国工程院院士邬贺铨最近在演讲中指出,6G对于5G/5G-A而言不仅仅是技术的简单叠加,更是整体架构平台的彻底变革。他强调,5G网络所具备的大带宽eMBB、大连接mMTC、高可靠低时延uRLLC三大特性将在5G-A和6G中继续得到加强。同时,6G还将引入5G阶段所不具备的特性,比如通感融合、内生智能,以及支持沉浸式体验等。0001CoreWeave「横空出世」现在它准备利用 GPU 云从生成式人工智能中赚取数十亿美元
据该CoreWeave公司的联合创始人兼首席战略官BranninMcBee称,几个月前,几乎没有人听说过CoreWeave,一家专注于GPU加速工作负载的云公司。而现在,CoreWeave凭借其GPU云计算产品从生成式人工智能热潮中赚取数十亿美元。站长网2023-08-02 09:48:310002蔚来与吉利控股签署换电战略合作协议
2023年11月29日,浙江吉利控股集团有限公司与蔚来控股有限公司在杭州签署了换电战略合作协议,双方将在换电电池标准、换电技术、换电服务网络建设及运营、换电车型研发及定制、电池资产管理及运营等多个领域展开全面合作。站长网2023-11-29 14:01:430000申通快递对12省份快件提价 以应对恶劣天气
站长之家(ChinaZ.com)2月1日消息:申通快递近日发布通知,为保障末端派送服务质量和消费者体验,结合当前天气情况,将对发往黑龙江、吉林、江西、湖南、湖北、安徽、四川、河南、山东、山西、内蒙古和辽宁等省份的快件进行价格调整。站长网2024-02-01 08:30:530000苹果最便宜的iPhone即将迎来第四代 iPhone SE 4 2025年春季发布
据消息来源透露,{tag_keyurl_4}计划于2025年春季发布新款iPhoneSE4。这款新机的设计与iPhone14标准版相似,但具体规格尚未公布。据了解,iPhoneSE4将搭载一块6.1英寸的刘海屏,这一设计与之前传闻一致。然而,值得注意的是,在最新的iPhone15系列中,虽然刘海屏形态已经消失,但此次回归似乎并非意外之举。0000










