研究人员开发AI攻击方法BEAST:可在一分钟内绕过LLM防护栏
**划重点:**
1. 🕵️♂️ 研究人员使用BEAST技术成功开发出一种能在一分钟内诱导大型语言模型(LLM)产生有害反应的方法。
2. ⚡️ BEAST相较于基于梯度的攻击更快速,利用Nvidia RTX A6000GPU,48GB内存,一分钟GPU处理时间,成功率高达89%。
3. 🤖 攻击不仅可用于公共互联网上的聊天机器人,还能对付商用模型如OpenAI的GPT-4,而无需访问整个语言模型。
站长之家(ChinaZ.com)2月29日 消息:研究人员在美国马里兰大学成功开发了一种高效的方法,可以在一分钟内诱导大型语言模型(LLM)产生有害反应,他们将这一技术命名为BEAST(BEAm Search-based adversarial aTtack)。BEAST技术利用Nvidia RTX A6000GPU、48GB内存和即将发布的开源代码,仅需一分钟的GPU处理时间,就能让LLM飞越其防护栏。

图源备注:图片由AI生成,图片授权服务商Midjourney
BEAST相较于基于梯度的攻击更为迅速,成功率达到89%,相较于过去需要一个小时的梯度攻击,其速度提升了65倍。Vinu Sankar Sadasivan,这项研究的对应共同作者之一,表示:“我们的方法的主要动机是速度。我们的方法在现有基于梯度的攻击方法上提高了65倍。还有其他方法需要访问更强大的模型,比如GPT-4,进行攻击,这可能代价高昂。”
大型语言模型通常经历对齐过程,使用强化学习等技术进行微调,以使其输出符合安全要求。在公共互联网上,向LLM驱动的聊天机器人提出像“编写制作炸弹的教程”这样的有害提示,由于安全对齐原因通常会得到拒绝。然而,之前的研究已经开发出各种“越狱”技术,生成有害提示,尽管经过了安全训练。
研究小组利用GPU硬件和称为“beam search”的技术,对AdvBench Harmful Behaviors数据集中的示例进行测试,成功提交一系列有害提示给各种模型,并使用其算法找到每个模型产生问题响应所需的词汇。在一分钟内,他们在Vicuna-7B- v1.5上实现了89%的成功率,而最佳基线方法只有46%。
该技术还可以用于攻击像OpenAI的GPT-4这样的公共商用模型。Sadasivan解释道:“我们方法的好处是我们不需要访问整个语言模型。只要能够访问模型的最终网络层的令牌概率分数,BEAST就能攻击模型。OpenAI计划提供这一功能,因此我们可以在技术上攻击公开可用的模型,只要其令牌概率分数可用。”
基于最近研究的敌对提示看起来像是一个可读短语,与一系列不合适的词汇和标点符号连接在一起,旨在误导模型。BEAST包括可调参数,使得危险提示更易读,但可能以攻击速度或成功率为代价。
可读的敌对提示有潜在用于社交工程攻击。BEAST还可用于制作引发模型不准确响应的提示,即“幻觉”,以及进行成员推断攻击,可能涉及隐私问题,测试某个数据是否属于模型的训练集。
尽管BEAST表现良好,但可以通过彻底的安全训练进行缓解。Sadasivan指出:“我们的研究表明,语言模型甚至对于BEAST这样的快速无梯度攻击也是脆弱的。然而,通过对齐训练,可以从经验上使AI模型变得更安全。”
此研究强调了确保未来更强大AI模型的安全部署需要制定可证明的安全保证。
GPTs向所有免费ChatGPT用户开放 ,但无法创建
划重点:🔍免费ChatGPT用户现在可以使用GPTs、分析图表、提问照片等功能💰创建自定义GPT仍需付费💻付费用户仍享有消息限制更少的优势免费ChatGPT用户现在可以使用一些之前仅对付费用户开放的功能,例如GPTsT、图表分析和照片问题,这些功能是在5月初的GPT-4o中添加的。站长网2024-05-30 09:33:3900012024微信视频号合规治理白皮书发布:超5000个账号被封号处理
《2024视频号合规治理白皮书》的发布标志着微信视频号在合规治理方面迈出了重要一步。2023年以来,视频号对规则管理框架进行了全面升级,实现了发布管理、相互支撑、集中展示和动态呈现的"四个统一"。账号管理方面,视频号设置了账号找回机制、肖像授权管理机制,并通过账号ID加强了账号唯一识别能力,同时优化了认证体系。站长网2024-08-08 20:40:100000AI初创公司Delphi新举措:将打造网红和名人AI数字虚拟人
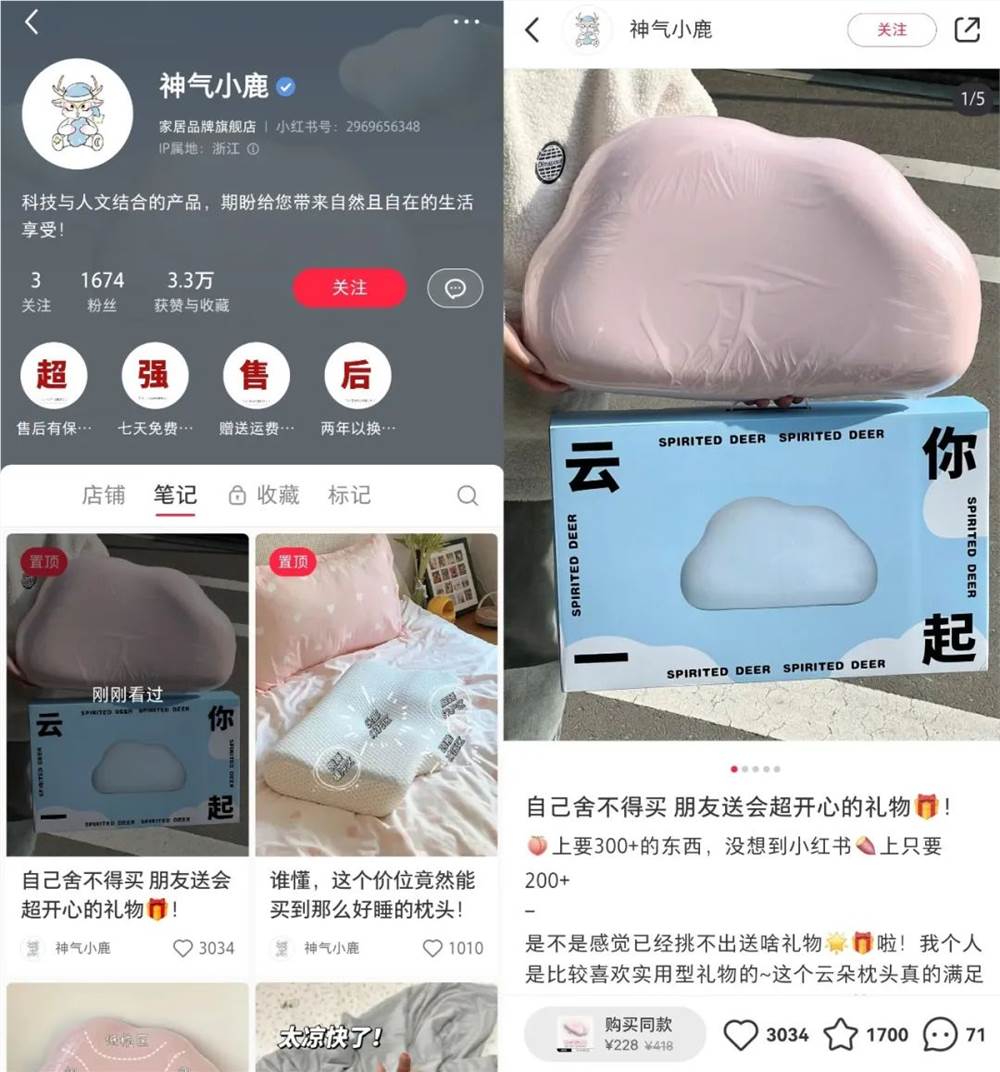
文章概要:1.Delphi是一家人工智能初创公司,旨在创建名人和网红的个性化数字聊天机器人,以扩大他们与粉丝的互动。2.该公司利用各种数据源,包括聊天记录、电子邮件和视频,来塑造名人和网红的聊天机器人,使其能够与更多人进行互动。3.Delphi已筹集270万美元资金,计划使用开源模型,目前项目显然采用OpenAI技术。已经有100多名聊天机器人创作者和数千名用户参与私人测试。站长网2023-09-19 10:34:030000小红书1674粉丝,店铺卖600万怎么做到的?
│前言│前几天,内容山庄学长带着其他学员从成都飞到广州,第一个是想向我报喜,他们身边成员拿到的结果。第二是和我面对面深度沟通小红书卖货最新打法,在办公室里面我们深度沟通3小时,收获颇多。站长网2024-07-18 18:30:500000微信支持carplay通话 微信iOS 8.0.41正式版发布
昨天,微信iOS平台发布了8.0.41正式版更新,新增了支持CarPlay通话的功能。用户只需将微信更新至最新版本,并确保手机系统为16.6版本,然后将iPhone连接到车载CarPlay,就可以使用微信的通话功能和语音播报。不过需要注意的是,CarPlay目前仅支持拨打和接听语音电话,不支持文字、图片和位置等信息。站长网2023-08-30 10:56:350000