尤洋团队开源OpenDiT,训练类似Sora模型实现80%加速
**划重点:**
1. 🚀 新加坡国立大学尤洋团队开源项目OpenDiT,加速Diffusion Transformer(DiT)模型训练和部署。
2. 💻 OpenDiT在GPU上实现高达80%的加速,同时节省50%内存,通过采用混合并行和序列并行方法等优化。
3. 🌐 提供易用的pipeline,包括文本到图像和文本到视频生成,验证在ImageNet上训练DiT模型的准确性。
新加坡国立大学尤洋团队最近发布的开源项目OpenDiT,为训练和部署DiT模型提供了新思路。
OpenDiT是一个易于使用、快速且内存高效的系统,专门用于提高DiT应用程序的训练和推理效率,包括文本到视频生成和文本到图像生成。该项目利用了ZeRO并行策略,将DiT模型参数分布到多台机器上,初步降低了显存压力。为了达到更好的性能与精度平衡,OpenDiT还采用了混合精度的训练策略。
在DiT模型的序列并行性方面,尤洋团队提出了FastSeq,一种适用于大序列和小规模并行的新型序列并行方法。这种方法通过最小化序列通信,利用AllGather提高通信效率,并巧妙地使用异步ring来优化性能,尤其适用于处理类似DiT的工作负载。
为了优化DiT模型中的运算效率,OpenDiT引入了高效的Fused adaLN Kernel,将多次操作合并,提高了计算效率并减少了I/O消耗。总体而言,OpenDiT具有在GPU上加速高达80%、50%内存节省的性能优势。
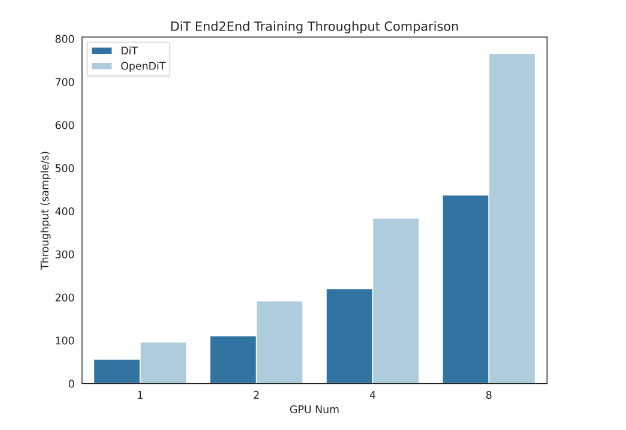
对于用户来说,OpenDiT提供了易于使用的pipeline,包括文本到图像和文本到视频生成。通过在ImageNet上进行文本到图像的训练,研究团队验证了OpenDiT的准确性,并发布了检查点。
OpenDiT为DiT模型的训练和部署提供了一种高效、易用的解决方案,为研究者和工程师在最短时间内复现Sora的效果提供了有力支持。
特色功能亮点:
OpenDiT 采用以下技术提高性能:
- GPU 上高达80% 的加速和50% 的内存减少
- 包括 FlashAttention、Fused AdaLN 和 Fused layernorm 核的内核优化。
- 包括 ZeRO、Gemini 和 DDP 等混合并行方法。此外,对 ema 模型进行分片进一步降低内存成本。
- FastSeq:一种新颖的序列并行方法,特别适用于 DiT 样式的工作负载,其中激活大小较大但参数大小较小。
易于使用:
- 通过几行更改实现巨大的性能提升
- 用户无需了解分布式训练的实现。
-支持 Image 和 Video 训练和推断:
- 使用脚本或命令行进行图像和视频训练
- 支持多节点训练和推断
- 提供用于训练和推断速度提升的库
项目入口:https://top.aibase.com/tool/opendit
微软确认 Bing 聊天实验性第三方浏览器支持正在推出
微软上周确认,Bing聊天将开始尝试为第三方浏览器提供支持。几个月前,Bing聊天作为一项聊天机器人AI服务推出时,只能在Edge浏览器上使用。但最近在Bing的Reddit页面上出现的帖子显示,Bing聊天已经在苹果的Safari和谷歌的Chrome浏览器中正常运行。站长网2023-06-05 21:07:030000仿人脑神经开发AI!剑桥大学最新研究登Nature子刊,人造大脑成AI新方向
【新智元导读】剑桥大学最新研究显示,AI模型和人脑神经结构有不少相似,也许未来会成为AI模型设计的关键。人脑作为地球上最复杂的智能载体,一个最大的特点就是能高能效地产生智能。如果能尽可能按照人脑的工作原理来创建AI系统,将会大大提高AI的工作效率,大幅降低能耗。最近,剑桥大学做了这么项研究,就是想找到一个条路径,让AI系统复制人脑。00002020年最受欢迎的15种商业模式
不少电商平台卖家和提供SaaS效劳创始人以为,构建一个有助于尽可能多地产生收入的业务方式都是至关重要的。很多企业可能以为只需一个方法可以销售自己的产品,在本文中,将跟大家分享增加收入的不同方法和以及相关的案例分析。要记住,那些成功的公司通常会应用多种方式增加收入来源。站长网2020-04-27 14:24:4500012微信“断路”幕后:视频号商业化棋至中局
作为国内社交的领头羊,微信至今已走过十二个年头。在其设计者张小龙的眼中,微信一直是一个“克制”的产品:“微信一直遵循一种好的设计原则,使得我们不会去做很多影响设计美感的事情。”可以说,在移动互联网爆发式增长的前夜,简洁与效率并重使得微信收获了巨大的成功。十二年后的今天,短视频成为承载内容的主要形式,微信也随之推出视频号以挖掘短视频巨大的潜在商业价值。站长网2023-09-05 11:22:570000AI文本生成动漫图片工具——Yodayo AI 含40种虚拟主播模型
YodayoAI是一款先进的人工智能系统,旨在生成免费且最好的AI动漫图像。它采用了创新的深度学习算法和生成对抗网络(GANs)等先进神经网络架构。YodayoAI不仅可以帮助用户创造独特的动漫图像,还能推动艺术创作和表达的界限。体验地址:https://yodayo.com/核心功能:拥有超过40种虚拟主播模型,每个有不同特点和风格。站长网2023-08-07 16:52:420002