60行代码,从头开始构建GPT!最全实践指南来了
【新智元导读】GPT早已成为大模型时代的基础。国外一位开发者发布了一篇实践指南,仅用60行代码构建GPT。
60行代码,从头开始构建GPT?
最近,一位开发者做了一个实践指南,用Numpy代码从头开始实现GPT。
你还可以将 OpenAI发布的GPT-2模型权重加载到构建的GPT中,并生成一些文本。
话不多说,直接开始构建GPT。

什么是GPT?
GPT代表生成式预训练Transformer,是一种基于Transformer的神经网络结构。
- 生成式(Generative):GPT生成文本。
- 预训练(Pre-trained):GPT是根据书本、互联网等中的大量文本进行训练的。
- Transformer:GPT是一种仅用于解码器的Transformer神经网络。
大模型,如OpenAI的GPT-3、谷歌的LaMDA,以及Cohere的Command XLarge,背后都是GPT。它们的特别之处在于,1) 非常大(拥有数十亿个参数),2) 受过大量数据(数百GB的文本)的训练。
直白讲,GPT会在提示符下生成文本。
即便使用非常简单的API(输入=文本,输出=文本),一个训练有素的GPT也可以做一些非常棒的事情,比如写邮件,总结一本书,为Instagram发帖提供想法,给5岁的孩子解释黑洞,用SQL编写代码,甚至写遗嘱。
以上就是 GPT 及其功能的高级概述。让我们深入了解更多细节。
输入/输出
GPT定义输入和输出的格式大致如下所示:
defgpt(inputs:list[int])->list[list[float]]:#inputshasshape[n_seq]#outputhasshape[n_seq,n_vocab]output=#beepboopneuralnetworkmagicreturnoutput
输入是由映射到文本中的token的一系列整数表示的一些文本:
#integersrepresenttokensinourtext,forexample:#text="notallheroeswearcapes":#tokens="not""all""heroes""wear""capes"inputs=[1,0,2,4,6]
Token是文本的子片段,使用分词器生成。我们可以使用词汇表将token映射到整数:
#theindexofatokeninthevocabrepresentstheintegeridforthattoken#i.e.theintegeridfor"heroes"wouldbe2,sincevocab[2]="heroes"vocab=["all","not","heroes","the","wear",".","capes"]#apretendtokenizerthattokenizesonwhitespacetokenizer=WhitespaceTokenizer(vocab)#theencode()methodconvertsastr->list[int]ids=tokenizer.encode("notallheroeswear")#ids=[1,0,2,4]#wecanseewhattheactualtokensareviaourvocabmappingtokens=[tokenizer.vocab[i]foriinids]#tokens=["not","all","heroes","wear"]#thedecode()methodconvertsbackalist[int]->strtext=tokenizer.decode(ids)#text="notallheroeswear"
简而言之:
- 有一个字符串。
- 使用分词器将其分解成称为token的小块。
- 使用词汇表将这些token映射为整数。
在实践中,我们会使用更先进的分词方法,而不是简单地用空白来分割,比如字节对编码(BPE)或WordPiece,但原理是一样的:
vocab将字符串token映射为整数索引
encode方法,可以转换str -> list[int]
decode 方法,可以转换 list[int] -> str ([2])
输出
输出是一个二维数组,其中 output[i][j] 是模型预测的概率,即 vocab[j] 处的token是下一个tokeninputs[i 1] 。例如:
vocab=["all","not","heroes","the","wear",".","capes"]inputs=[1,0,2,4]#"not""all""heroes""wear"output=gpt(inputs)#["all","not","heroes","the","wear",".","capes"]#output[0]=[0.750.10.00.150.00.00.0]#givenjust"not",themodelpredictstheword"all"withthehighestprobability
#["all", "not", "heroes", "the", "wear", ".", "capes"]# output[1] =[0.00.00.80.10.00.00.1]# given the sequence ["not", "all"], the model predicts the word "heroes" with the highest probability
#["all", "not", "heroes", "the", "wear", ".", "capes"]# output[-1] = [0.00.00.00.10.00.050.85]# given the whole sequence ["not", "all", "heroes", "wear"], the model predicts the word "capes" with the highest probability
要获得整个序列的下一个token预测,我们只需获取 output[-1] 中概率最高的token:
vocab=["all","not","heroes","the","wear",".","capes"]inputs=[1,0,2,4]#"not""all""heroes""wear"output=gpt(inputs)next_token_id=np.argmax(output[-1])#next_token_id=6next_token=vocab[next_token_id]#next_token="capes"
将概率最高的token作为我们的预测,称为贪婪解码(Greedy Decoding)或贪婪采样(greedy sampling)。
预测序列中的下一个逻辑词的任务称为语言建模。因此,我们可以将GPT称为语言模型。
生成一个单词很酷,但整个句子、段落等又如何呢?
生成文本
自回归
我们可以通过迭代从模型中获得下一个token预测来生成完整的句子。在每次迭代中,我们将预测的token追加回输入:
defgenerate(inputs,n_tokens_to_generate):for_inrange(n_tokens_to_generate):#auto-regressivedecodeloopoutput=gpt(inputs)#modelforwardpassnext_id=np.argmax(output[-1])#greedysamplinginputs.append(int(next_id))#appendpredictiontoinputreturninputs[len(inputs)-n_tokens_to_generate:]#onlyreturngeneratedids
input_ids = [1,0] # "not" "all"output_ids = generate(input_ids,3) # output_ids = [2,4,6]output_tokens = [vocab[i] for i in output_ids] # "heroes" "wear" "capes"
这个预测未来值(回归)并将其添加回输入(自)的过程,就是为什么你可能会看到GPT被描述为自回归的原因。
采样
我们可以从概率分布中采样,而不是贪婪采样,从而为生成的引入一些随机性:
inputs=[1,0,2,4]#"not""all""heroes""wear"output=gpt(inputs)np.random.choice(np.arange(vocab_size),p=output[-1])#capesnp.random.choice(np.arange(vocab_size),p=output[-1])#hatsnp.random.choice(np.arange(vocab_size),p=output[-1])#capesnp.random.choice(np.arange(vocab_size),p=output[-1])#capesnp.random.choice(np.arange(vocab_size),p=output[-1])#pants
这样,我们就能在输入相同内容的情况下生成不同的句子。
如果与top-k、top-p和温度等在采样前修改分布的技术相结合,我们的输出质量就会大大提高。
这些技术还引入了一些超参数,我们可以利用它们来获得不同的生成行为(例如,提高温度会让我们的模型承担更多风险,从而更具「创造性」)。
训练
我们可以像训练其他神经网络一样,使用梯度下降法训练GPT,并计算损失函数。对于GPT,我们采用语言建模任务的交叉熵损失:
deflm_loss(inputs:list[int],params)->float:#thelabelsyarejusttheinputshifted1totheleft##inputs=[not,all,heros,wear,capes]#x=[not,all,heroes,wear]#y=[all,heroes,wear,capes]##ofcourse,wedon'thavealabelforinputs[-1],soweexcludeitfromx##assuch,forNinputs,wehaveN-1langaugemodelingexamplepairsx,y=inputs[:-1],inputs[1:]#forwardpass#allthepredictednexttokenprobabilitydistributionsateachpositionoutput=gpt(x,params)#crossentropyloss#wetaketheaverageoverallN-1examplesloss=np.mean(-np.log(output[y]))returnlossdeftrain(texts:list[list[str]],params)->float:fortextintexts:inputs=tokenizer.encode(text)loss=lm_loss(inputs,params)gradients=compute_gradients_via_backpropagation(loss,params)params=gradient_descent_update_step(gradients,params)returnparams
这是一个经过大量简化的训练设置,但可以说明问题。
请注意,我们在gpt函数签名中添加了params (为了简单起见,我们在前面的章节中没有添加)。在训练循环的每一次迭代期间:
- 对于给定的输入文本实例,计算了语言建模损失
- 损失决定了我们通过反向传播计算的梯度
- 我们使用梯度来更新我们的模型参数,以使损失最小化(梯度下降)
请注意,我们不使用显式标记的数据。相反,我们能够仅从原始文本本身生成输入/标签对。这被称为自监督学习。
自监督使我们能够大规模扩展训练数据,只需获得尽可能多的原始文本并将其投放到模型中。例如,GPT-3接受了来自互联网和书籍的3000亿个文本token的训练:
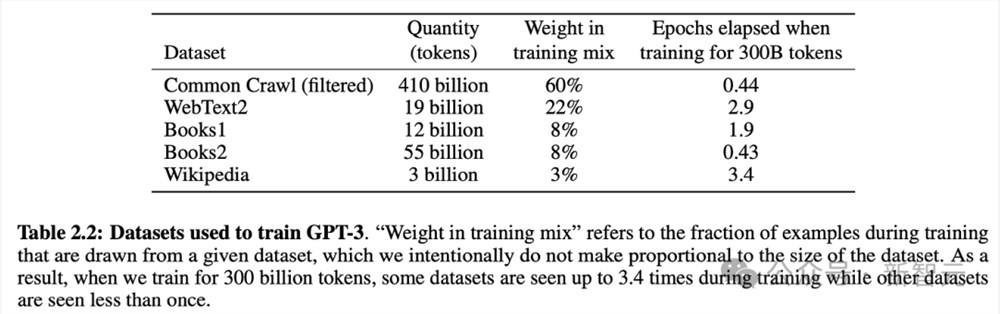
当然,你需要一个足够大的模型才能从所有这些数据中学习,这就是为什么GPT-3有1750亿个参数,训练的计算成本可能在100万至1000万美元之间。
这个自监督的训练步骤被称为预训练,因为我们可以重复使用「预训练」的模型权重来进一步训练模型的下游任务。预训练的模型有时也称为「基础模型」。
在下游任务上训练模型称为微调,因为模型权重已经经过了理解语言的预训练,只是针对手头的特定任务进行了微调。
「一般任务的前期训练 特定任务的微调」策略被称为迁移学习。
提示
原则上,最初的GPT论文只是关于预训练Transformer模型用于迁移学习的好处。
论文表明,当对标记数据集进行微调时,预训练的117M GPT在各种自然语言处理任务中获得了最先进的性能。
直到GPT-2和GPT-3论文发表后,我们才意识到,基于足够的数据和参数预训练的GPT模型,本身能够执行任何任务,不需要微调。
只需提示模型,执行自回归语言建模,然后模型就会神奇地给出适当的响应。这就是所谓的「上下文学习」(in-context learning),因为模型只是利用提示的上下文来完成任务。
语境中学习可以是0次、一次或多次。
在给定提示的情况下生成文本也称为条件生成,因为我们的模型是根据某些输入生成一些输出的。
GPT并不局限于NLP任务。
你可以根据你想要的任何条件来微调这个模型。比如,你可以将GPT转换为聊天机器人(如ChatGPT),方法是以对话历史为条件。
说到这里,让我们最后来看看实际的实现。
设置
克隆本教程的存储库:
gitclonehttps://github.com/jaymody/picoGPTcdpicoGPT
然后安装依赖项:
pipinstall-rrequirements.txt
注意:这段代码是用Python3.9.10测试的。
每个文件的简单分类:
- encoder.py包含OpenAI的BPE分词器的代码,这些代码直接取自gpt-2repo。
- utils.py包含下载和加载GPT-2模型权重、分词器和超参数的代码。- gpt2.py包含实际的GPT模型和生成代码,我们可以将其作为python脚本运行。- gpt2_pico.py与gpt2.py相同,但代码行数更少。
我们将从头开始重新实现gpt2.py ,所以让我们删除它并将其重新创建为一个空文件:
rmgpt2.pytouchgpt2.py
首先,将以下代码粘贴到gpt2.py中:
importnumpyasnpdefgpt2(inputs,wte,wpe,blocks,ln_f,n_head):pass#TODO:implementthisdefgenerate(inputs,params,n_head,n_tokens_to_generate):fromtqdmimporttqdmfor_intqdm(range(n_tokens_to_generate),"generating"):#auto-regressivedecodelooplogits=gpt2(inputs,**params,n_head=n_head)#modelforwardpassnext_id=np.argmax(logits[-1])#greedysamplinginputs.append(int(next_id))#appendpredictiontoinputreturninputs[len(inputs)-n_tokens_to_generate:]#onlyreturngeneratedidsdefmain(prompt:str,n_tokens_to_generate:int=40,model_size:str="124M",models_dir:str="models"):fromutilsimportload_encoder_hparams_and_params#loadencoder,hparams,andparamsfromthereleasedopen-aigpt-2filesencoder,hparams,params=load_encoder_hparams_and_params(model_size,models_dir)#encodetheinputstringusingtheBPEtokenizerinput_ids=encoder.encode(prompt)#makesurewearenotsurpassingthemaxsequencelengthofourmodelassertlen(input_ids) n_tokens_to_generate<hparams["n_ctx"]#generateoutputidsoutput_ids=generate(input_ids,params,hparams["n_head"],n_tokens_to_generate)#decodetheidsbackintoastringoutput_text=encoder.decode(output_ids)returnoutput_textif__name__=="__main__":importfirefire.Fire(main)
将4个部分分别分解为:
- gpt2函数是我们将要实现的实际GPT代码。你会注意到,除了inputs之外,函数签名还包括一些额外的内容:
wte、 wpe、 blocks和ln_f是我们模型的参数。
n_head是前向传递过程中需要的超参数。
- generate函数是我们前面看到的自回归解码算法。为了简单起见,我们使用贪婪抽样。tqdm是一个进度条,帮助我们可视化解码过程,因为它一次生成一个token。
- main函数处理:
加载分词器(encoder)、模型权重(params)和超参数(hparams)
使用分词器将输入提示编码为token ID
调用生成函数
将输出ID解码为字符串
fire.Fire(main)只是将我们的文件转换为CLI应用程序,因此我们最终可以使用python gpt2.py "some prompt here"运行代码
让我们更详细地了解一下笔记本中的encoder 、 hparams和params,或者在交互式的Python会话中,运行:
fromutilsimportload_encoder_hparams_and_paramsencoder,hparams,params=load_encoder_hparams_and_params("124M","models")
这将把必要的模型和分词器文件下载到models/124M ,并将encoder、 hparams和params加载到我们的代码中。
编码器
encoder是GPT-2使用的BPE分词器:
ids=encoder.encode("Notallheroeswearcapes.")ids[3673,477,10281,5806,1451,274,13]encoder.decode(ids)"Notallheroeswearcapes."
使用分词器的词汇表(存储在encoder.decoder中),我们可以看到实际的token是什么样子的:
[encoder.decoder[i]foriinids]['Not','Ġall','Ġheroes','Ġwear','Ġcap','es','.']
请注意,我们的token有时是单词(例如Not),有时是单词但前面有空格(例如Ġall,Ġ表示空格),有时是单词的一部分(例如Capes分为Ġcap和es),有时是标点符号(例如.)。
BPE的一个优点是它可以对任意字符串进行编码。如果它遇到词汇表中没有的内容,它只会将其分解为它能够理解的子字符串:
[encoder.decoder[i]foriinencoder.encode("zjqfl")]['z','j','q','fl']
我们还可以检查词汇表的大小:
len(encoder.decoder)50257
词汇表以及确定如何拆分字符串的字节对合并是通过训练分词器获得的。
当我们加载分词器时,我们从一些文件加载已经训练好的单词和字节对合并,当我们运行load_encoder_hparams_and_params时,这些文件与模型文件一起下载。
超参数
hparams是一个包含我们模型的超参数的词典:
>>>hparams{"n_vocab":50257,#numberoftokensinourvocabulary"n_ctx":1024,#maximumpossiblesequencelengthoftheinput"n_embd":768,#embeddingdimension(determinesthe"width"ofthenetwork)"n_head":12,#numberofattentionheads(n_embdmustbedivisiblebyn_head)"n_layer":12#numberoflayers(determinesthe"depth"ofthenetwork)}
我们将在代码的注释中使用这些符号来显示事物的基本形状。我们还将使用n_seq表示输入序列的长度(即n_seq = len(inputs))。
参数
params是一个嵌套的json字典,它保存我们模型的训练权重。Json的叶节点是NumPy数组。我们会得到:
>>>importnumpyasnp>>>defshape_tree(d):>>>ifisinstance(d,np.ndarray):>>>returnlist(d.shape)>>>elifisinstance(d,list):>>>return[shape_tree(v)forvind]>>>elifisinstance(d,dict):>>>return{k:shape_tree(v)fork,vind.items()}>>>else:>>>ValueError("uhoh")>>>>>>print(shape_tree(params)){"wpe":[1024,768],"wte":[50257,768],"ln_f":{"b":[768],"g":[768]},"blocks":[{"attn":{"c_attn":{"b":[2304],"w":[768,2304]},"c_proj":{"b":[768],"w":[768,768]},},"ln_1":{"b":[768],"g":[768]},"ln_2":{"b":[768],"g":[768]},"mlp":{"c_fc":{"b":[3072],"w":[768,3072]},"c_proj":{"b":[768],"w":[3072,768]},},},...#repeatforn_layers]}
这些是从原始OpenAI TensorFlow检查点加载的:
importtensorflowastftf_ckpt_path=tf.train.latest_checkpoint("models/124M")forname,_intf.train.list_variables(tf_ckpt_path):arr=tf.train.load_variable(tf_ckpt_path,name).squeeze()print(f"{name}:{arr.shape}")model/h0/attn/c_attn/b:(2304,)model/h0/attn/c_attn/w:(768,2304)model/h0/attn/c_proj/b:(768,)model/h0/attn/c_proj/w:(768,768)model/h0/ln_1/b:(768,)model/h0/ln_1/g:(768,)model/h0/ln_2/b:(768,)model/h0/ln_2/g:(768,)model/h0/mlp/c_fc/b:(3072,)model/h0/mlp/c_fc/w:(768,3072)model/h0/mlp/c_proj/b:(768,)model/h0/mlp/c_proj/w:(3072,768)model/h1/attn/c_attn/b:(2304,)model/h1/attn/c_attn/w:(768,2304)...model/h9/mlp/c_proj/b:(768,)model/h9/mlp/c_proj/w:(3072,768)model/ln_f/b:(768,)model/ln_f/g:(768,)model/wpe:(1024,768)model/wte:(50257,768)
下面的代码将上述TensorFlow变量转换为我们的params词典。
作为参考,以下是params的形状,但用它们所代表的hparams替换了数字:
>>>importtensorflowastf>>>tf_ckpt_path=tf.train.latest_checkpoint("models/124M")>>>forname,_intf.train.list_variables(tf_ckpt_path):>>>arr=tf.train.load_variable(tf_ckpt_path,name).squeeze()>>>print(f"{name}:{arr.shape}")model/h0/attn/c_attn/b:(2304,)model/h0/attn/c_attn/w:(768,2304)model/h0/attn/c_proj/b:(768,)model/h0/attn/c_proj/w:(768,768)model/h0/ln_1/b:(768,)model/h0/ln_1/g:(768,)model/h0/ln_2/b:(768,)model/h0/ln_2/g:(768,)model/h0/mlp/c_fc/b:(3072,)model/h0/mlp/c_fc/w:(768,3072)model/h0/mlp/c_proj/b:(768,)model/h0/mlp/c_proj/w:(3072,768)model/h1/attn/c_attn/b:(2304,)model/h1/attn/c_attn/w:(768,2304)...model/h9/mlp/c_proj/b:(768,)model/h9/mlp/c_proj/w:(3072,768)model/ln_f/b:(768,)model/ln_f/g:(768,)model/wpe:(1024,768)model/wte:(50257,768)
基本层
在我们进入实际的GPT体系结构本身之前,最后一件事是,让我们实现一些非特定于GPT的更基本的神经网络层。
GELU
GPT-2选择的非线性(激活函数)是GELU(高斯误差线性单元),它是REU的替代方案:
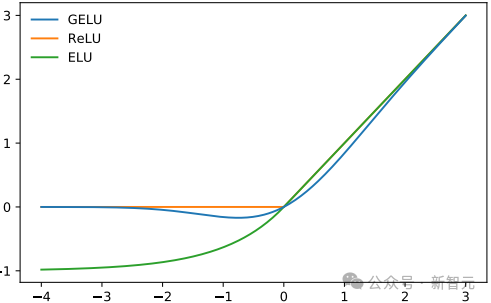
它由以下函数近似表示:
defgelu(x):return0.5*x*(1 np.tanh(np.sqrt(2/np.pi)*(x 0.044715*x**3)))
与RELU类似,Gelu在输入上按元素操作:
gelu(np.array([[1,2],[-2,0.5]]))array([[0.84119,1.9546],[-0.0454,0.34571]])
Softmax
Good ole softmax:
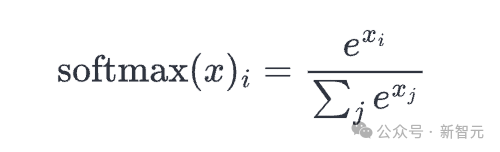
defsoftmax(x):exp_x=np.exp(x-np.max(x,axis=-1,keepdims=True))returnexp_x/np.sum(exp_x,axis=-1,keepdims=True)
我们使用max(x)技巧来保证数值稳定性。
SoftMax用于将一组实数(介于−∞和∞之间)转换为概率(介于0和1之间,所有数字的总和为1)。我们在输入的最后一个轴上应用softmax 。
x=softmax(np.array([[2,100],[-5,0]]))xarray([[0.00034,0.99966],[0.26894,0.73106]])x.sum(axis=-1)array([1.,1.])
层归一化
层归一化将值标准化,使其平均值为0,方差为1:
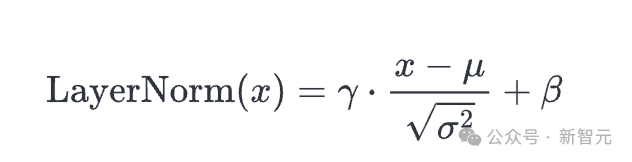
deflayer_norm(x,g,b,eps:float=1e-5):mean=np.mean(x,axis=-1,keepdims=True)variance=np.var(x,axis=-1,keepdims=True)x=(x-mean)/np.sqrt(variance eps)#normalizextohavemean=0andvar=1overlastaxisreturng*x b#scaleandoffsetwithgamma/betaparams
层归一化确保每一层的输入始终在一致的范围内,这会加快和稳定训练过程。
与批处理归一化一样,归一化输出随后被缩放,并使用两个可学习向量gamma和beta进行偏移。分母中的小epsilon项用于避免除以零的误差。
由于种种原因,Transformer采用分层定额代替批量定额。
我们在输入的最后一个轴上应用层归一化。
>>>x=np.array([[2,2,3],[-5,0,1]])>>>x=layer_norm(x,g=np.ones(x.shape[-1]),b=np.zeros(x.shape[-1]))>>>xarray([[-0.70709,-0.70709,1.41418],[-1.397,0.508,0.889]])>>>x.var(axis=-1)array([0.99996,1.])#floatingpointshenanigans>>>x.mean(axis=-1)array([-0.,-0.])Linear
你的标准矩阵乘法 偏差:
deflinear(x,w,b):#[m,in],[in,out],[out]->[m,out]returnx@w b
线性层通常称为映射(因为它们从一个向量空间映射到另一个向量空间)。
>>>x=np.random.normal(size=(64,784))#inputdim=784,batch/sequencedim=64>>>w=np.random.normal(size=(784,10))#outputdim=10>>>b=np.random.normal(size=(10,))>>>x.shape#shapebeforelinearprojection(64,784)>>>linear(x,w,b).shape#shapeafterlinearprojection(64,10)
GPT架构
GPT架构遵循Transformer的架构:
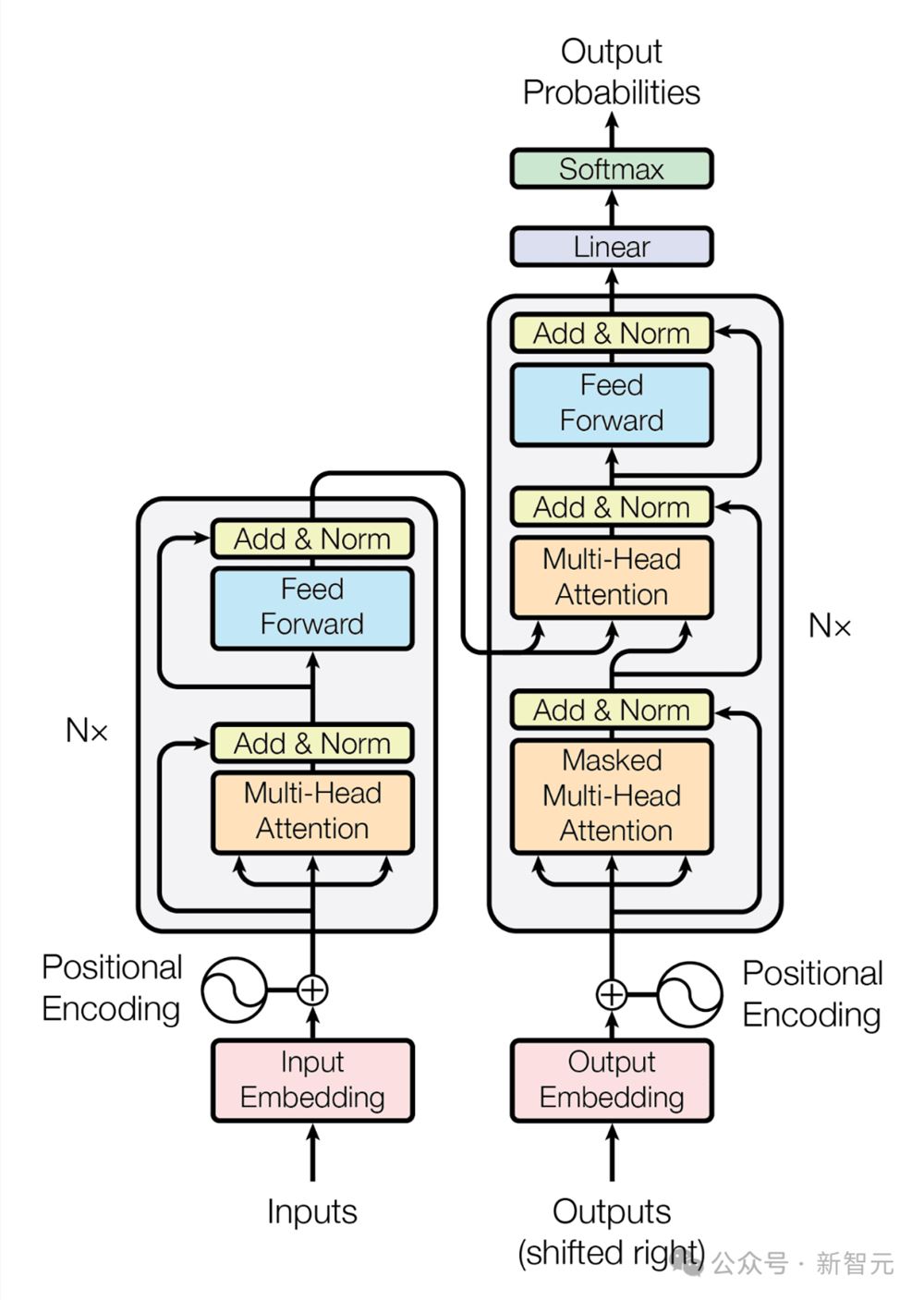
从高层次上讲,GPT体系结构有三个部分:
文本 位置嵌入
一种transformer解码器堆栈
向单词步骤的映射
在代码中,它如下所示:
defgpt2(inputs,wte,wpe,blocks,ln_f,n_head):#[n_seq]->[n_seq,n_vocab]#token positionalembeddingsx=wte[inputs] wpe[range(len(inputs))]#[n_seq]->[n_seq,n_embd]#forwardpassthroughn_layertransformerblocksforblockinblocks:x=transformer_block(x,**block,n_head=n_head)#[n_seq,n_embd]->[n_seq,n_embd]#projectiontovocabx=layer_norm(x,**ln_f)#[n_seq,n_embd]->[n_seq,n_embd]returnx@wte.T#[n_seq,n_embd]->[n_seq,n_vocab]
把所有放在一起
把所有这些放在一起,我们得到了gpt2.py,它总共只有120行代码(如果删除注释和空格,则为60行)。
我们可以通过以下方式测试我们的实施:
pythongpt2.py\"AlanTuringtheorizedthatcomputerswouldonedaybecome"\--n_tokens_to_generate8
它给出了输出:
themostpowerfulmachinesontheplanet.
它成功了!
我们可以使用下面的Dockerfile测试我们的实现与OpenAI官方GPT-2repo的结果是否一致。
dockerbuild-t"openai-gpt-2""https://gist.githubusercontent.com/jaymody/9054ca64eeea7fad1b58a185696bb518/raw/Dockerfile"dockerrun-dt"openai-gpt-2"--name"openai-gpt-2-app"dockerexec-it"openai-gpt-2-app"/bin/bash-c'python3src/interactive_conditional_samples.py--length8--model_type124M--top_k1'#paste"AlanTuringtheorizedthatcomputerswouldonedaybecome"whenprompted
这应该会产生相同的结果:
themostpowerfulmachinesontheplanet.
下一步呢?
这个实现很酷,但它缺少很多花哨的东西:
GPU/TPU支持
将NumPy替换为JAX:
importjax.numpyasnp
你现在可以使用代码与GPU,甚至TPU!只需确保正确安装了JAX即可。
反向传播
同样,如果我们用JAX替换NumPy:
importjax.numpyasnp然后,计算梯度就像以下操作一样简单:deflm_loss(params,inputs,n_head)->float:x,y=inputs[:-1],inputs[1:]output=gpt2(x,**params,n_head=n_head)loss=np.mean(-np.log(output[y]))returnlossgrads=jax.grad(lm_loss)(params,inputs,n_head)Batching
再一次,如果我们用JAX替换NumPy:
importjax.numpyasnp然后,对gpt2函数进行批处理非常简单:gpt2_batched=jax.vmap(gpt2,in_axes=[0,None,None,None,None,None])gpt2_batched(batched_inputs)#[batch,seq_len]->[batch,seq_len,vocab]
推理优化
我们的实现效率相当低。你可以进行的最快、最有效的优化(在GPU 批处理支持之外)将是实现KV缓存。
训练
训练GPT对于神经网络来说是相当标准的(梯度下降是损失函数)。
当然,在训练GPT时,你还需要使用标准的技巧包(例如,使用ADAM优化器、找到最佳学习率、通过辍学和/或权重衰减进行正则化、使用学习率调度器、使用正确的权重初始化、批处理等)。
训练一个好的GPT模型的真正秘诀是调整数据和模型的能力,这才是真正的挑战所在。
对于缩放数据,你需要一个大、高质量和多样化的文本语料库。
- 大意味着数十亿个token(TB级的数据)。
- 高质量意味着您想要过滤掉重复的示例、未格式化的文本、不连贯的文本、垃圾文本等。
- 多样性意味着不同的序列长度,关于许多不同的主题,来自不同的来源,具有不同的视角等等。
评估
如何评价一个LLM,这是一个很难的问题。
停止生成
当前的实现要求我们提前指定要生成的token的确切数量。这并不是一个好方法,因为我们生成的token最终会过长、过短或在句子中途中断。
为了解决这个问题,我们可以引入一个特殊的句尾(EOS)标记。
在预训练期间,我们将EOS token附加到输入的末尾(即tokens = ["not", "all", "heroes", "wear", "capes", ".", "<|EOS|>"])。
在生成期间,只要我们遇到EOS token(或者如果我们达到了某个最大序列长度),就会停止:
defgenerate(inputs,eos_id,max_seq_len):prompt_len=len(inputs)whileinputs[-1]!=eos_idandlen(inputs)<max_seq_len:output=gpt(inputs)next_id=np.argmax(output[-1])inputs.append(int(next_id))returninputs[prompt_len:]
GPT-2没有预训练EOS token,所以我们不能在我们的代码中使用这种方法。
无条件生成
使用我们的模型生成文本需要我们使用提示符对其进行条件调整。
但是,我们也可以让我们的模型执行无条件生成,即模型在没有任何输入提示的情况下生成文本。
这是通过在预训练期间将特殊的句子开始(BOS)标记附加到输入开始(即tokens = ["<|BOS|>", "not", "all", "heroes", "wear", "capes", "."])来实现的。
然后,要无条件地生成文本,我们输入一个只包含BOS token的列表:
defgenerate_unconditioned(bos_id,n_tokens_to_generate):inputs=[bos_id]for_inrange(n_tokens_to_generate):output=gpt(inputs)next_id=np.argmax(output[-1])inputs.append(int(next_id))returninputs[1:]
GPT-2预训练了一个BOS token(名称为<|endoftext|>),因此使用我们的实现无条件生成非常简单,只需将以下行更改为:
input_ids=encoder.encode(prompt)ifpromptelse[encoder.encoder["<|endoftext|>"]]然后运行:pythongpt2.py""这将生成:ThefirsttimeIsawthenewversionofthegame,Iwassoexcited.Iwassoexcitedtoseethenewversionofthegame,Iwassoexcitedtoseethenewversion
因为我们使用的是贪婪采样,所以输出不是很好(重复),而且是确定性的(即,每次我们运行代码时都是相同的输出)。为了得到质量更高且不确定的生成,我们需要直接从分布中抽样(理想情况下,在应用类似top-p的方法之后)。
无条件生成并不是特别有用,但它是展示GPT能力的一种有趣的方式。
微调
我们在训练部分简要介绍了微调。回想一下,微调是指当我们重新使用预训练的权重来训练模型执行一些下游任务时。我们称这一过程为迁移学习。
从理论上讲,我们可以使用零样本或少样本提示,来让模型完成我们的任务,
然而,如果你可以访问token的数据集,微调GPT将产生更好的结果(在给定更多数据和更高质量的数据的情况下,结果可以扩展)。
有几个与微调相关的不同主题,我将它们细分如下:
分类微调
在分类微调中,我们给模型一些文本,并要求它预测它属于哪一类。
例如,以IMDB数据集为例,它包含将电影评为好或差的电影评论:
---Example1---Text:Iwouldn'trentthisoneevenondollarrentalnight.Label:Bad---Example2---Text:Idon'tknowwhyIlikethismoviesowell,butInevergettiredofwatchingit.Label:Good---Example3---...
为了微调我们的模型,我们将语言建模头替换为分类头,并将其应用于最后一个token输出:
defgpt2(inputs,wte,wpe,blocks,ln_f,cls_head,n_head):x=wte[inputs] wpe[range(len(inputs))]forblockinblocks:x=transformer_block(x,**block,n_head=n_head)x=layer_norm(x,**ln_f)#projectton_classes#[n_embd]@[n_embd,n_classes]->[n_classes]returnx[-1]@cls_head
我们只使用最后一个token输出x[-1],因为我们只需要为整个输入生成单一的概率分布,而不是语言建模中的n_seq分布。
尤其,我们采用最后一个token,因为最后一个token是唯一被允许关注整个序列的token,因此具有关于整个输入文本的信息。
像往常一样,我们优化了w.r.t.交叉熵损失:
defsinge_example_loss_fn(inputs:list[int],label:int,params)->float:logits=gpt(inputs,**params)probs=softmax(logits)loss=-np.log(probs[label])#crossentropylossreturnloss
我们还可以通过应用sigmoid而不是softmax来执行多标签分类,并获取关于每个类别的二进制交叉熵损失。
生成式微调
有些任务不能被整齐地归类。例如,总结这项任务。
我们只需对输入和标签进行语言建模,就能对这类任务进行微调。例如,下面是一个总结训练样本:
---Article---ThisisanarticleIwouldliketosummarize.---Summary---Thisisthesummary.
我们像在预训练中一样训练模型(优化w.r.t语言建模损失)。
在预测时间,我们向模型提供直到--- Summary ---的所有内容,然后执行自回归语言建模以生成摘要。
分隔符--- Article ---和--- Summary ---的选择是任意的。如何选择文本的格式由你自己决定,只要它在训练和推理之间保持一致。
注意,我们还可以将分类任务制定为生成式任务(例如使用IMDB):
---Text---Iwouldn'trentthisoneevenondollarrentalnight.---Label---Bad
指令微调
如今,大多数最先进的大模型在经过预寻来你后,还会经历额外的指令微调。
在这一步中,模型对数千个人类标记的指令提示 完成对进行了微调(生成)。指令微调也可以称为有监督的微调,因为数据是人为标记的。
那么,指令微调有什么好处呢?
虽然预测维基百科文章中的下一个单词能让模型擅长续写句子,但这并不能让它特别擅长遵循指令、进行对话或总结文档(我们希望GPT能做的所有事情)。
在人类标注的指令 完成对上对其进行微调,是一种教模型如何变得更有用,并使其更易于交互的方法。
这就是所谓的AI对齐,因为我们正在对模型进行对齐,使其按照我们的意愿行事。

参数高效微调
当我们在上述章节中谈到微调时,假定我们正在更新所有模型参数。
虽然这能产生最佳性能,但在计算(需要对整个模型进行反向传播)和存储(每个微调模型都需要存储一份全新的参数副本)方面成本高昂。
解决这个问题最简单的方法就是只更新头部,冻结(即无法训练)模型的其他部分。
虽然这可以加快训练速度,并大大减少新参数的数量,但效果并不是特别好,因为我们失去了深度学习的深度。
相反,我们可以选择性地冻结特定层,这将有助于恢复深度。这样做的结果是,效果会好很多,但我们的参数效率会降低很多,也会失去一些训练速度的提升。
值得一提的是,我们还可以利用参数高效的微调方法。
以Adapters 一文为例。在这种方法中,我们在transformer块中的FFN和MHA层之后添加一个额外的「适配器」层。
适配层只是一个简单的两层全连接神经网络,输入输出维度为 n_embd ,隐含维度小于 n_embd :
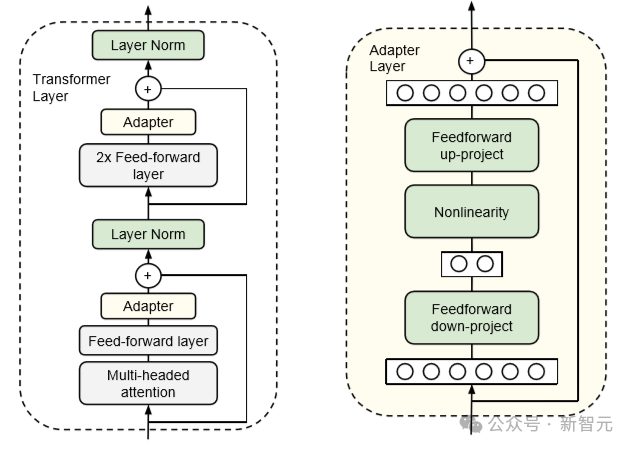
隐藏维度的大小是一个超参数,我们可以对其进行设置,从而在参数与性能之间进行权衡。
论文显示,对于BERT模型,使用这种方法可以将训练参数的数量减少到2%,而与完全微调相比,性能只受到很小的影响(<1%)。
微软悄然推出适用于 Android 的专用 Copilot 应用程序
微软公司近日悄无声息地为Android推出了一款新的独立AI聊天机器人应用,名为「Copilot」。这款应用首次被Twitter用户发现,它的发布丰富了AI驱动移动应用的领域,为消费者提供了更多样化的选择。站长网2023-12-27 09:44:420000我们花一个月调研了小红书种草的新机会和增长策略
随着618的临近,小红书再次成为了品牌重要的“营销战场”。面临着经济环境的不确定性,想必各大品牌都非常关注小红书种草的增长策略,希望能够挖掘出更多的增量空间。于是,我们最近启动了一个小红书种草的专项研究,通过一个月时间追踪平台的数据趋势、调研最佳实践案例,覆盖美妆、母婴、3C、服装等15个主流类目,探索了当前的挑战和创新的机会在哪里。以下为核心观点摘要1.“11”现状:挑战背后也有机遇站长网2023-05-17 17:15:290000从抖音获赞Top5000账号,我们发现了头部达人突破创作瓶颈的秘密
“真的没有创作瓶颈吗?”一些头部达人爆款视频的评论区中,常有网友发出这样的感慨。在网友看来,有这样一批堪称“没有瓶颈”的创作者,比如“papi酱”“李蠕蠕”“智博”和“派小轩”等以内容见长的达人。虽然他们总是通过不断迭代的作品带给网友惊喜,但实际上,创作瓶颈是几乎每位创作者都要面对的难题。站长网2024-06-07 08:42:340000实测快手“AI玩评”功能,以后AI也要来抢热评了
以后,AI也要来抢热评了。继8月推出“文生文”大语言模型“快意”(KwaiYii)后,快手又在“文生图”赛道推出了自研大模型“可图”(Kolors)。据了解,从8月下旬开始,快手AI团队就已在公司内部开启了可图大模型的内测,并支持网页版工具和标准化API两种使用方式。依托可图大模型,快手开始在短视频评论区内测“AI玩评”功能,这是继“AI对话”之后,快手在短视频场景内落地的又一AIGC能力。站长网2023-09-25 09:18:380000版权过期后,米老鼠SD模型上线 以后可以放心用AI画米老鼠了
日前,迪士尼旧版米老鼠的版权正式过期,这意味着任何人都可以自由使用旧版米老鼠形象。AI圈的开发者们手速也不可小觑,这不,才刚宣布过期没多久,他们就已经推出了米老鼠的SD模型Mickey-1928。站长网2024-01-03 15:13:270000