清华大学团队推出RTFS-Net:革新视听语音分离,百万参数实现高效性能
**划重点:**
1. 🎙️ RTFS-Net是首个采用少于100万个参数的视听语音分离方法,通过压缩-重建策略显著减少计算复杂度。
2. 🌐 针对传统视听语音分离方法的问题,RTFS-Net创新性地解决了时域和时频域方法的挑战,提高了在复杂环境中的性能。
3. 🚀 在三个基准多模态语音分离数据集上,RTFS-Net在大幅降低模型参数和计算复杂度的同时,接近或超越了当前最先进的性能。
清华大学的胡晓林团队最近推出了一项创新性的视听语音分离方法,称为RTFS-Net。这一方法通过采用压缩-重建的策略,不仅实现了百万参数以下的视听语音分离,而且显著减少了计算复杂度,为音视频分离领域带来了新的视角。
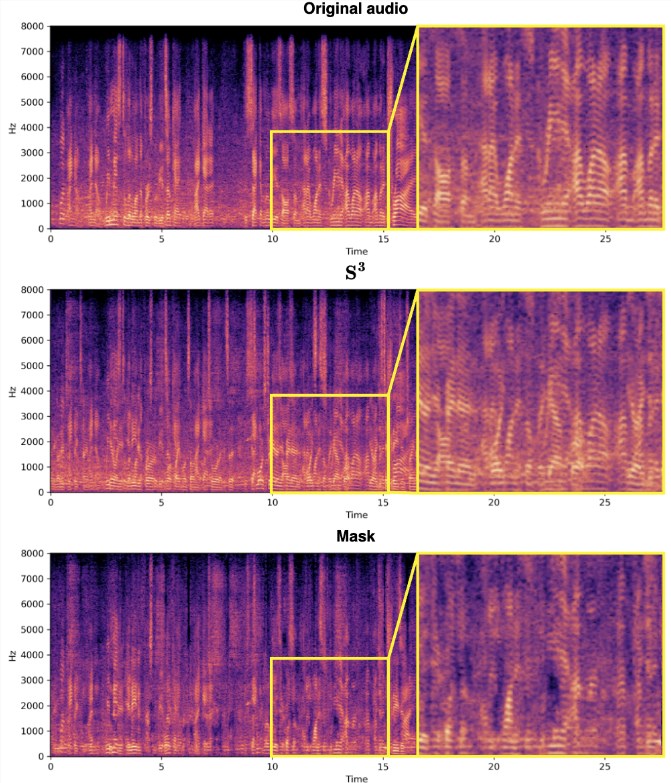
传统的视听语音分离方法通常依赖于复杂的模型和大量的计算资源,尤其在嘈杂背景或多说话者场景下性能受到限制。RTFS-Net通过创新性地解决时域和时频域方法的挑战,突破了这些限制。时域方法提供高质量的音频分离效果,但计算复杂度高,而时频域方法虽然计算效率更高,却一直面临缺乏独立建模、未充分利用多个感受野的视觉线索和对复数特征处理不当等问题。
RTFS-Net的关键在于引入了RTFS块,该块通过双路径架构在时间和频率两个维度上对音频信号进行有效处理。具体来说,RTFS块首先进行时间和频率维度的压缩,然后在压缩后的维度上进行独立建模,最后通过融合模块将两个维度的信息合并。这一策略不仅减少了计算复杂度,还保持了对音频信号的高度敏感性和准确性。
此外,RTFS-Net还引入了跨维注意力融合(CAF)模块,有效融合音频和视觉信息,提高了语音分离效果。CAF模块采用深度和分组卷积操作生成注意力权重,动态调整输入特征的重要性,通过对视觉和听觉特征应用注意力权重,实现在多个维度上聚焦于关键信息。
最终,RTFS-Net的实验结果表明,在三个基准多模态语音分离数据集上,该方法在大幅降低模型参数和计算复杂度的同时,接近或超越了当前最先进的性能。通过不同数量的RTFS块的变体展示了在效率和性能之间的权衡,其中RTFS-Net-6在性能与效率方面取得了良好的平衡,而RTFS-Net-12在所有测试的数据集上表现最佳,证明了时频域方法在处理复杂音视频同步分离任务中的优势。
这一创新性的视听语音分离方法为提高AVSS性能提供了新的思路,不仅降低了计算复杂度和参数数量,而且在保持显著性能提升的同时,为音视频分离领域注入了更多创新和高效的架构。
论文地址:https://arxiv.org/abs/2309.17189
代码地址:https://github.com/spkgyk/RTFS-Net(即将发布)
暴雪魔兽世界国服正式服今日开服
今天,《魔兽世界》的国服正式重新开放,根据暴雪的计划,原定开服时间是中午12:00,但玩家的实际体验显示,服务器开放时间比预期提前了,玩家们现在已经可以登录并进入游戏。玩家在首次登录游戏时,会触发全新的战团系统转换流程,这个过程可能会持续20分钟以上。此外,由于数据量处理的需要,玩家在登录时可能会遇到排队等待的情况。站长网2024-08-01 09:58:090000AI日报:Open-Sora Plan v1.2发布;Mistral Large2突然开源;腾讯智影推智能画布功能
欢迎来到【AI日报】栏目!这里是你每天探索人工智能世界的指南,每天我们为你呈现AI领域的热点内容,聚焦开发者,助你洞悉技术趋势、了解创新AI产品应用。新鲜AI产品点击了解:https://top.aibase.com/1、震撼来袭!Open-SoraPlanv1.2发布,清晰度、推理速度起飞站长网2024-07-25 17:15:440000腾讯宣布:股票回购规模将疯狂扩大 2024年至少1000亿港元
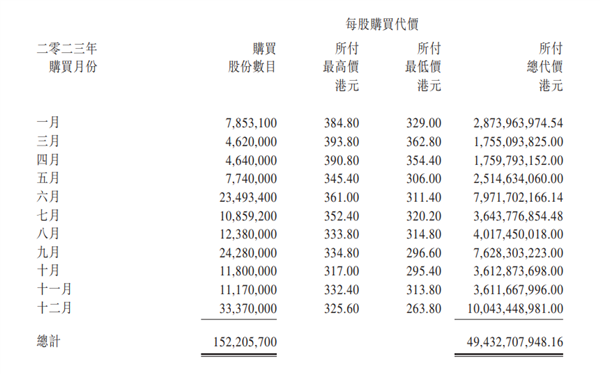
快科技3月20日消息,腾讯公司在过去一年一直在大举回购股票,而在2024年,这一举动将更为激烈。根据腾讯控股发布的2023年全年财报,他们计划将股份回购规模至少翻倍,从2023年的490亿港元增加到2024年的超过1000亿港元。财报显示,腾讯在2023年回购了1.52亿股股票,总耗资达到494.3亿港元,仅去年12月就投入了100亿港元用于回购。站长网2024-03-20 18:07:080000苹果代号 Quartz 的基于人工智能的健康辅导付费服务或于 2024 年推出
据彭博社MarkGurman报道,苹果计划在6月展示的iOS17更新将包括几个与健康有关的新功能。将会有一个跟踪情绪的功能,另外苹果计划首次将「健康」应用带到iPad上。站长网2023-04-26 14:23:160000侵权就全额赔偿!Adobe为自家AI工具Firefly的用户提供法律支持
Adobe正在为其FireflyforEnterprise产品的用户可能因使用其新的AI工具Firefly产品而可能产生的与版权相关的法律费用提供全额赔偿。Adobe声称Firefly已经接受了完全合法输入的培训,主要来自其自己广泛的图像库。根据Adobe数字媒体副总裁ClaudeAlexandre的说法,赔偿将涵盖所创建内容的全额赔偿。站长网2023-06-09 23:45:290000