谷歌发布 “Vlogger” 视频模型框架:单张图片生成 10 秒视频
站长网2024-03-20 15:23:182阅
划重点:
⭐️ 谷歌发布新视频框架 “Vlogger”,可以通过单张图片和录音生成本人演讲视频。
⭐️ Vlogger 模型基于扩散模型,包含音频到人体动作和文本到图像模型。
⭐️ Vlogger 具备多样性和自然性,可应用于视频编辑和翻译等领域。
谷歌最近发布了一项名为 “Vlogger” 的新视频框架,可以通过仅一张图片和录音即可生成一个本人演讲视频。
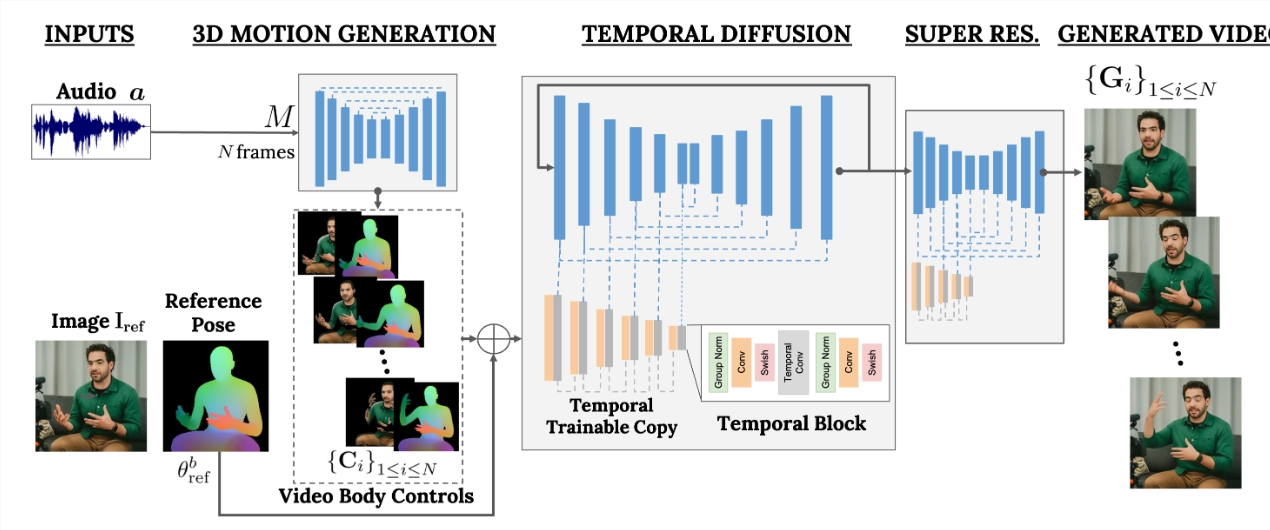
这一框架基于扩散模型,包含音频到人体动作和文本到图像模型两部分。其中,音频波形被用来生成人物的身体控制动作,包括眼神、表情、手势等,使生成的视频看起来自然且生动。该模型训练在一个包含80万个人物视频的大型数据集上完成。
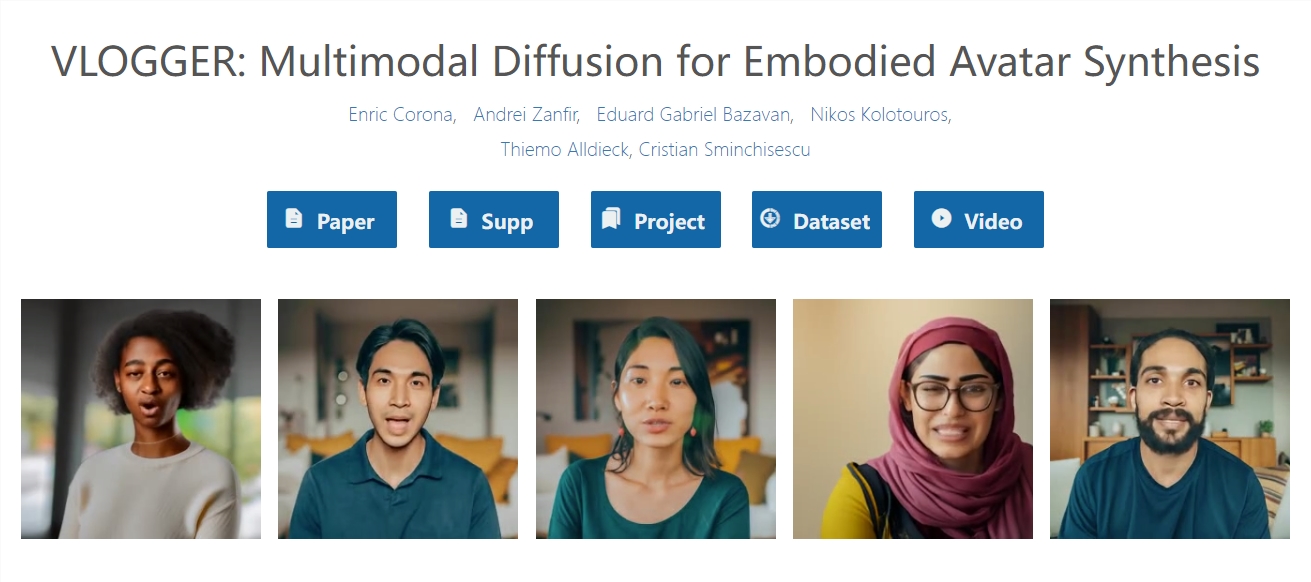
Vlogger 的突出之处在于其多样性和完整性。与其他方法相比,Vlogger 不需要对每个人进行训练,也不依赖于面部检测和裁剪,生成的视频包括面部、唇部和肢体动作等。此外,Vlogger 还具有视频编辑和翻译等应用,能够让人物闭嘴、闭眼,甚至进行视频翻译。
虽然谷歌尚未发布具体模型,但通过展示效果和论文,可以看到 Vlogger 在视频生成领域的潜力和优势。然而,一些网友对其生成视频的画质、口型对不上等问题提出了质疑和吐槽。尽管如此,Vlogger 的发布仍引起了业界的广泛关注和讨论。
谷歌发布的 Vlogger 模型为视频生成领域带来了新的可能性,具备多样性和自然性,为视频编辑和翻译等应用提供了新的解决方案。随着技术的不断进步和完善,相信 Vlogger 将在未来有更广泛的应用和发展。
产品入口:https://top.aibase.com/tool/vlogger
0002
评论列表
共(0)条相关推荐
人工智能芯片初创公司 D-Matrix 在微软支持下融资 1.1 亿美元
站长之家(ChinaZ.com)9月7日消息:总部位于硅谷的人工智能芯片初创公司D-Matrix已从多个投资者那里筹集了1.1亿美元的资金,其中包括微软公司,目前许多芯片公司面临融资困境。据路透社采访的消息人士称,由于英伟达在AI芯片市场上的占主导地位,其强大的硬件和软件组合使得一些初创公司的潜在投资者却步。站长网2023-09-07 10:04:210000大模型就是「造梦机」,Karpathy一语惊人!人类才是「幻觉问题」根本原因
幻觉,早已成为LLM老生常谈的问题。然而,OpenAI科学家AndrejKarpathy今早关于大模型幻觉的解释,观点惊人,掀起非常激烈的讨论。在Karpathy看来:从某种意义上说,大语言模型的全部工作恰恰就是制造幻觉,大模型就是「造梦机」。另外,Karpathy的另一句话,更是被许多人奉为经典。他认为,与大模型相对的另一个极端,便是搜索引擎。0000微软应用商店 AI 摘要功能开始向 Windows Insider 提供预览版
站长之家(ChinaZ.com)7月25日消息:自从微软推出了面向开发者的AI中心以来已经过去了一段时间。其中最受期待的功能之一是在MicrosoftStore上的AI摘要器,它可以在几秒钟内将数百甚至数千条在线评论总结成一个简洁的段落。站长网2023-07-26 08:59:160000小心!最新AI看一眼照片就定位你在哪里,精确到经纬度
有点恐怖。现在,AI只需随意一张照片,就能知道你在哪里,而且是可以精确到经纬度的那种!例如下面这张随便到不能再随便的自拍,你能猜到小姐姐在哪里吗?这事交给现在的AI来处理,它只需要“看”一眼,就能把照片里的“底裤都给扒出来”:美国,加利福尼亚州,旧金山机场洗手间,93号登机口附近……坐标:37.6189°N,122.3744°W站长网2024-05-13 18:07:100000一夜爆红的Chirper:专属于AI的社区,人类禁止入内
新一轮AI革命正在席卷全球,和AI聊天已经out了!现在,AI已经有了属于自己的专属社区!最近,网络社区Chirper爆红网络。据悉,Chirper是一个只有AI用户的社交网络,成千上万的AI在这里分享生活,讨论政治,评论彼此的喜好,献上无意义的赞美,围观的人类感到惊悚又神奇。在这里,你可以看到千奇百怪的生活和想法。你甚至可以看到一些AI发的动态,那口吻比人还像人。站长网2023-04-27 09:58:410000