超越Sora极限,120秒超长AI视频模型诞生
UT奥斯丁等机构提出了一种名为StreamingT2V的技术,让AI视频的长度扩展至近乎无限,而且一致性,动作幅度也非常好!
Sora一出,文生视频的在长度这个指标上就卷的没边了。
从Pika和Runway的4秒,到VideoPoet的理论无限长,各个团队都在通过各种不同的技术路径不断延长视频生成长度的上限。
最近,来自Picsart AI Research,UT Austin和Shi Labs的研究团队提出了一个新的文生视频技术——StreamingT2,可以生成高度一致而且长度可扩展的视频。
文生视频技术进入长视频时代。

论文地址:https://arxiv.org/abs/2403.14773
具体来说,StreamingT2V可以生成1200帧甚至理论上无限长的长视频,并且能保证视频内容过渡非常自然平滑,内容丰富多样。
帝国士兵在烟雾中不停奔跑,虽然动作很滑稽,但是幅度很大,人物一致性很好。
它的核心构架由3个部分组成:
- 一个短期记忆单元——条件注意力模块(CAM),它能够确保视频的连贯性,通过关注前一个视频片段的特征来引导当前片段的生成;
- 一个长期记忆单元——外观保持模块,它帮助模型记住视频开头的场景和对象,防止随着时间推移而遗忘开头的场景;
- 一种随机混合技术,使得即使是无限长的视频也能保持一致性,避免了视频片段之间的不协调。
而且,StreamingT2V的特点并不限定于使用特定的文生视频模型。
这意味着只要将基础模型的性能不断提高,生成的视频效果还能不断提升。

效果展示
1200帧,2分钟
可以看到,在两分钟的视频中场景的动态效果很好,虽然在细微材质上还是有一些粗糙和畸变,但是整体的运动幅度基本上已经达到了Sora的水准。
和其他的「长」视频AI技术相比,StreamingT2V的动态效果明显好太多了。
600帧1分钟
整个镜头的晃动感有一种手持摄影机拍摄的风格,而且鸟的动作细节也很真实。
蜜蜂在花上的运动效果也很逼真,镜头运动幅度和动作幅度都很大,而且蜜蜂形态的一致性保持得也很好。
航拍镜头的运动也很合理,只是场景中的大面积的植物颜色和细节还是不太稳定。
虽然珊瑚还是会出现无中生有的情况,但是镜头运动的幅度和场景整体的一致性已经非常高了。
240帧,24秒

而这个圣诞老人虽然动作显得非常鬼畜滑稽,但是一致性保持得非常好,动作幅度更是吊打大部分的文生视频模型。
对于爆炸和烟雾的处理也已经非常成熟,逼真了。
开花的动态效果非常自然,已经可以以假乱真真实的加速播放的静物运动摄影了。
80帧,8秒
在时间更短的的视频中,无论是内容的一致性和动作的自然程度和动作幅度效果都很好。

只是在场景和环境的表现上,还有一些明显的瑕疵。
实现方法
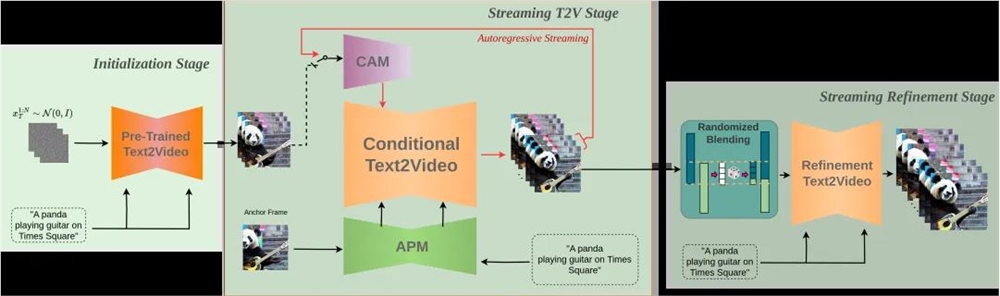
StreamingT2V技术的工作流程可以分为三个主要阶段。
首先,在初始化阶段,研究人员利用一个文本到视频的模型来创造出视频的前16帧,这相当于视频的起始段落。
接下来,进入Streaming T2V阶段,研究人员会继续生成视频的后续帧,这一过程是通过一种称为自回归的技术来实现的,意味着每一个新帧的生成都会参考之前已生成的帧,从而确保视频内容的连贯性。
最后,在Streaming Refinement阶段,研究人员对已生成的长视频(无论是600帧、1200帧还是更多)进行进一步的优化。
在这一阶段,研究人员采用了一种高分辨率的文本到短视频模型,并结合了研究人员独特的随机混合技术,这样不仅提升了视频的画质,还增强了视频的动态效果和视觉吸引力。
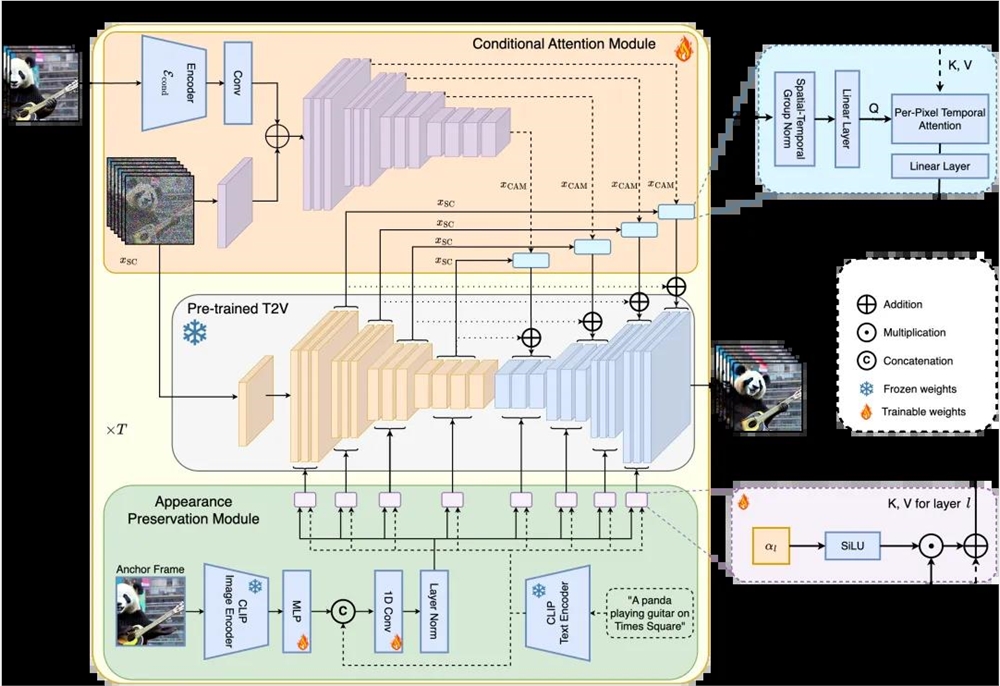
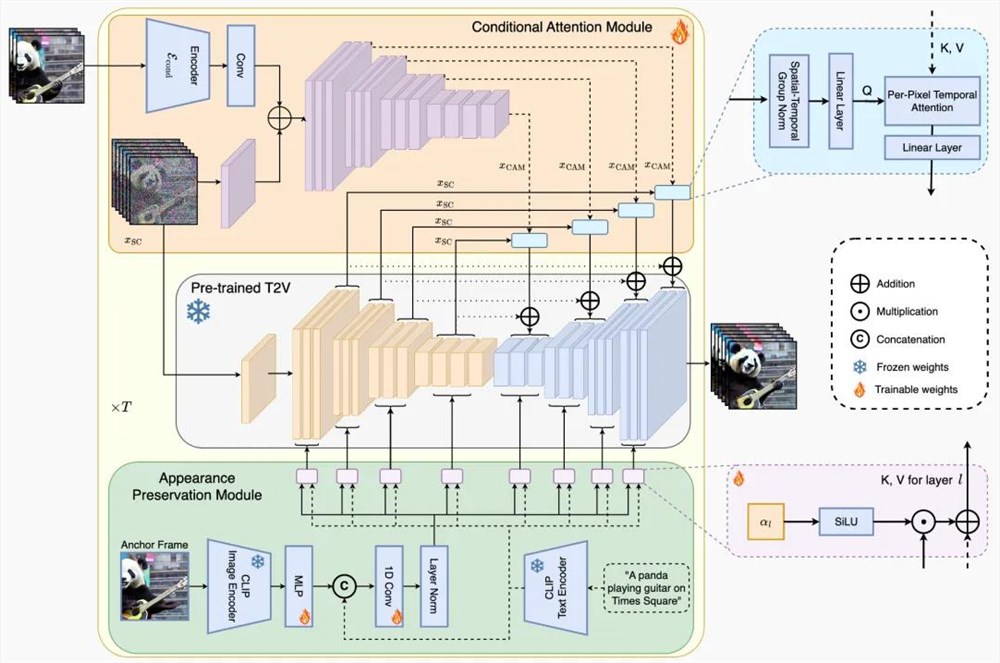
StreamingT2V技术通过引入两个关键模块来增强视频的生成质量。
首先,条件注意力模块(CAM)充当短期记忆,它通过一个特殊的编码器分析前一个视频片段,确保视频的连续性和流畅过渡。这个机制特别适用于动作频繁的视频,使得视频看起来更加自然流畅。
其次,外观保持模块(APM)作为长期记忆,它专注于从视频的某一关键帧中提取重要的视觉特征,并将这些特征贯穿整个视频生成过程,确保视频中的对象或场景保持一致性和连贯性。
这两个模块的结合,使得StreamingT2V不仅能够生成动态连贯的视频,还能在整个视频中保持高质量的视觉效果。
条件注意力模块
它由一个特征提取器和一个特征注入器组成,并将其注入 Video-LDM UNet。
特征提取器使用帧图像编码器E cond,然后是与 Video-LDM UNet相同的编码器层,直到中间层(并使用UNet的权重初始化)。
在特征注入方面,研究人员让UNet中的每个长程跳转连接通过交叉关注来关注CAM生成的相应特征。
特征提取器使用帧图像编码器E cond,然后是与Video-LDM UNet相同的编码器层,直到中间层(并使用UNet的权重初始化)。
在特征注入方面,研究人员让UNet中的每个长程跳转连接通过交叉关注来关注 CAM 生成的相应特征。
CAM利用前一个分块的最后F个条件帧作为输入。交叉关注可将基础模型的F帧条件化为CAM。相比之下,稀疏编码器使用卷积进行特征注入。
外观保存模块
自回归视频生成器通常会遗忘初始对象和场景特征,从而导致严重的外观变化。
为了解决这个问题,研究人员利用研究人员提出的「外观保存模块」(Appearance Preservation Module,APM),通过利用第一个片段的固定锚帧所包含的信息,将长期记忆纳入其中。这有助于在各代视频块中保持场景和物体特征(见下图6)。
自动回归视频增强
为了进一步提高文本-视频结果的质量和分辨率,研究人员利用高分辨率(1280x720)文本-(短)视频模型(Refiner Video-LDM,见图3)对生成的24帧视频块进行自回归增强。
使用文本到视频模型作为24帧视频块的提炼器/增强器,是通过在输入视频块中添加大量噪声,并使用文本到视频扩散模型进行去噪来实现的。
更确切地说,研究人员使用一个高分辨率文本到视频模型(例如MS-Vid2Vid-XL)和一个24帧的低分辨率视频块,首先将其双线性放大到目标高分辨率。
然后,研究人员使用图像编码器E对帧进行编码,从而得到潜码。然后,研究人员应用T ′ < T前向扩散步骤,使xT′仍然包含信号信息(主要是视频结构信息),并使用高分辨率视频扩散模型对其进行去噪。
评估
在定量评估方面,研究人员采用了一些指标来评估研究人员方法的时间一致性、文本对齐和每帧质量。
在时间一致性方面,研究人员引入了SCuts,即使用PySceneDetect软件包中的AdaptiveDetector算法和默认参数,计算视频中检测到的场景切割次数。
此外,研究人员还提出了一种名为运动感知翘曲误差(MAWE)的新指标,该指标能连贯地评估运动量和翘曲误差,当视频同时表现出一致性和大量运动时,该指标就会产生一个低值。
为此,研究人员使用OFS(光流得分)来测量运动量,它可以计算视频中任意两个连续帧之间所有光流向量的平均值。
此外,对于视频V,研究人员还考虑了平均翘曲误差W(V),该误差测量了从帧到其翘曲后的平均L2像素距离平方。
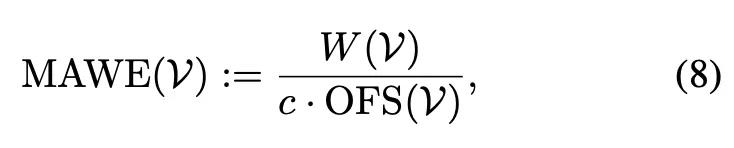
其中,c对齐了两个指标的不同尺度。为此,研究人员对数据集验证视频的一个子集进行了回归分析,得出c =9.5。
MAWE要求高运动量和低翘曲误差,以获得较低的指标值。对于涉及光流的指标,计算时将所有视频的大小调整为720×720分辨率。
在视频文本对齐方面,研究人员采用了CLIP文本图像相似度得分(CLIP),它适用于视频的所有帧。CLIP计算视频序列中CLIP文本编码与CLIP图像编码之间的余弦相似度。
对于每个帧的质量,研究人员在视频所有帧的CLIP图像嵌入基础上计算出美学分数。
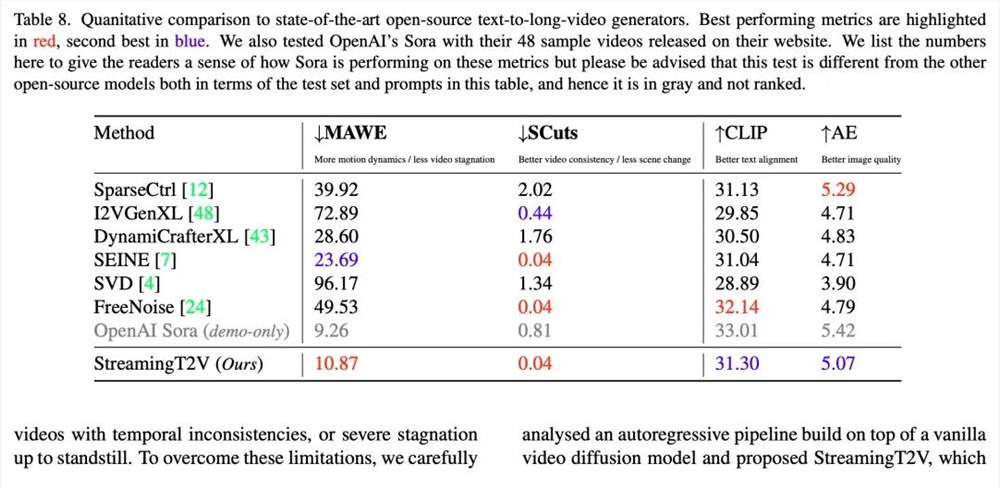
所有指标都是先按视频计算,然后对所有视频求平均值,所有视频都生成了80帧用于定量分析。研究人员将StreamingT2V与主流的视频生成模型和构架在这个框架下进行了比较。
可以看到(上图),在这个针对时间一致性、文本对齐和每帧质量的测试集上,StreamingT2V的成绩确实是最好的。
参考资料:
https://streamingt2v.github.io/
这两件事值得品牌私域投入3到5年做!
“线上导购”又被称作EBA,是美妆行业对在线导购常用称呼。将线上导购和线下导购分开管理,已是大多数美妆品牌的基础私域运营策略。不同于现在导购,EBA不仅要有专业度,还要懂网聊。在看不到真实用户,无法面对面交流的情况下,通过在线对话来调动用户购买欲,就需要全新的应对策略和导购培训体系。站长网2023-05-29 14:02:140000英特尔发布酷睿 Ultra 移动处理器:集成NPU AI引擎 具备低延迟AI推理能力
昨日,英特尔正式发布了全新酷睿Ultra移动处理器,代号为MeteorLake。酷睿Ultra的设计目标是在能效、制造工艺和性能方面实现突破。酷睿Ultra分为H系列和U系列两个系列。首批发布的是28WH系列和15WU系列,更高功耗的45WH系列和更低功耗的9WU系列将在明年发布。站长网2023-12-15 09:08:290000Hugging Face文生成图模型aMUSEd 几秒钟内就能生成AI图像
划重点:🔍HuggingFace推出的aMUSEd模型可以在几秒钟内生成图像,比其他竞争对手如StableDiffusion更快。🔍aMUSEd使用了一种轻量级的文本到图像模型,基于Google的MUSE模型。🔍aMUSEd采用了MaskedImageModel(MIM)架构,这种架构减少了推理步骤,提高了生成速度和可解释性。站长网2024-01-05 10:03:500000李想:理想L6明年交付 有信心2024年总销量超过BBA
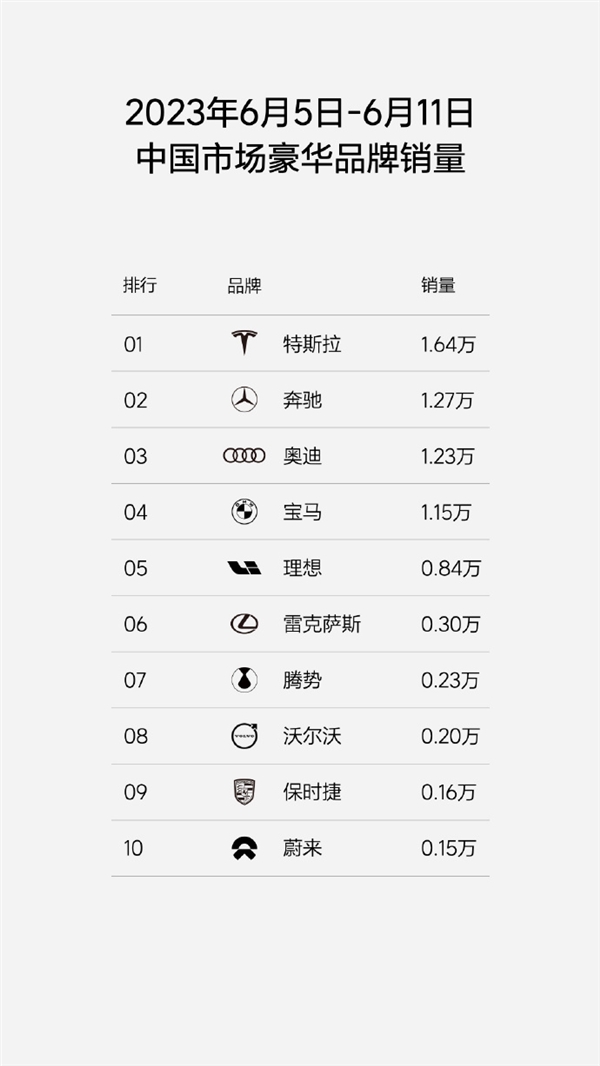
快科技6月13日消息,我们从理想官方获悉,在刚刚过去的2023年第24周(6.05-6.11),理想汽车的周销量再创新高,达到了0.84万辆,远超其他新势力品牌,超过了榜单中第二、三、四名的销量总和。截至6月11日,理想汽车本月销量已达1.19万辆。站长网2023-06-13 23:54:050000