让GAN再次伟大!拽一拽关键点就能让狮子张嘴&大象转身,汤晓鸥弟子的DragGAN爆火,网友:R.I.P. Photoshop
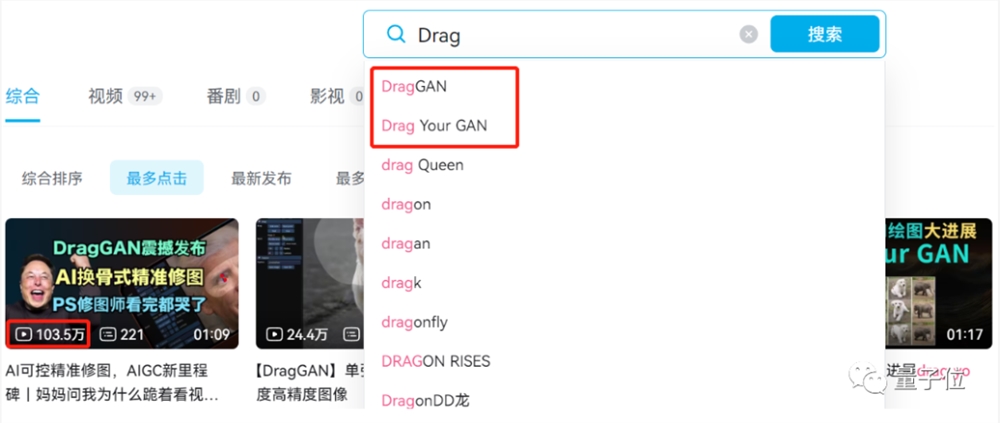
这两天,一段AI修图视频在国内外社交媒体上传疯了。
不仅直接蹿升B站关键词联想搜索第一,视频播放上百万,微博推特也是火得一塌糊涂,转发者纷纷直呼“PS已死”。
怎么回事?
原来,现在P图真的只需要“轻轻点两下”,AI就能彻底理解你的想法!
小到竖起狗子的耳朵:
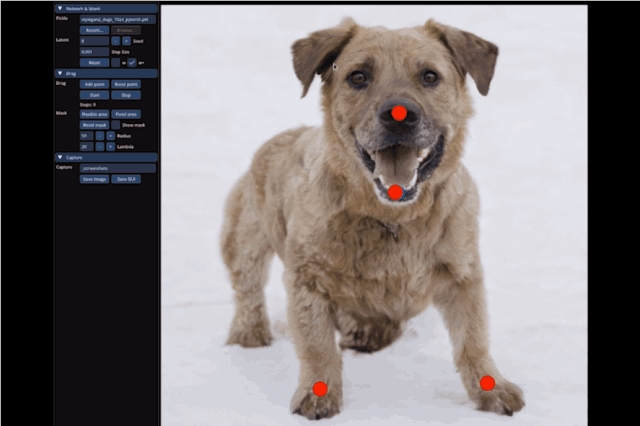
大到让整只狗子蹲下来,甚至让马岔开腿“跑跑步”,都只需要设置一个起始点和结束点,外加拽一拽就能搞定:
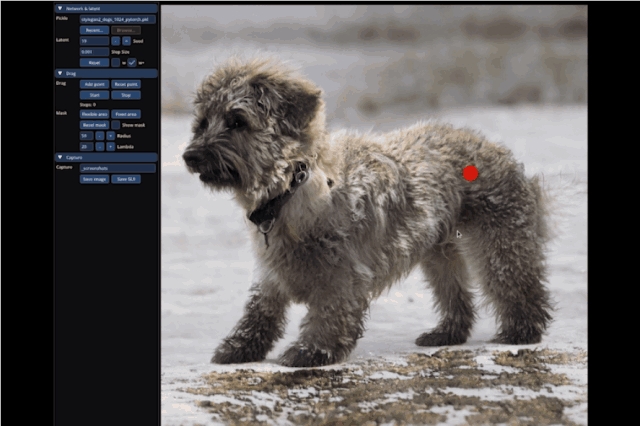
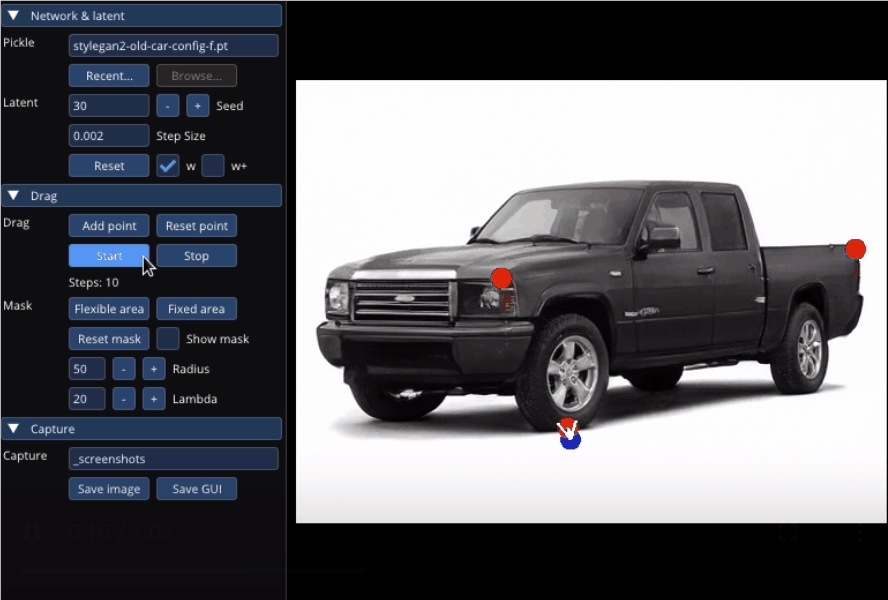
不止是动物的调整,连像汽车这样的“非生物”,也能一键拉升底座,甚至升级成“加长豪华车”:
这还只是AI修图的“基操”。
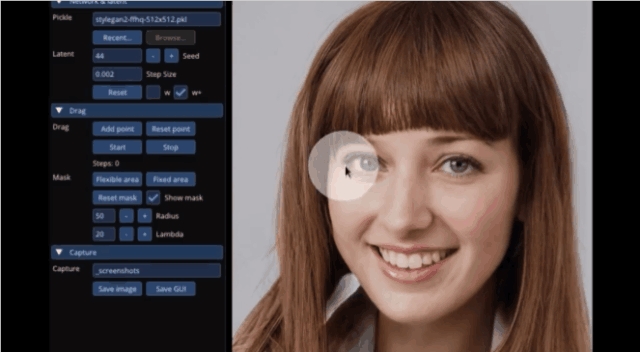
要是想对图像实现更精准的控制,只需画个圈给指定区域“涂白”,就能让狗子转个头看向你:

或是让照片中的小姐姐“眨眨眼”:
甚至是让狮子张大嘴,连牙齿都不需要作为素材放入,AI自动就能给它“安上”:
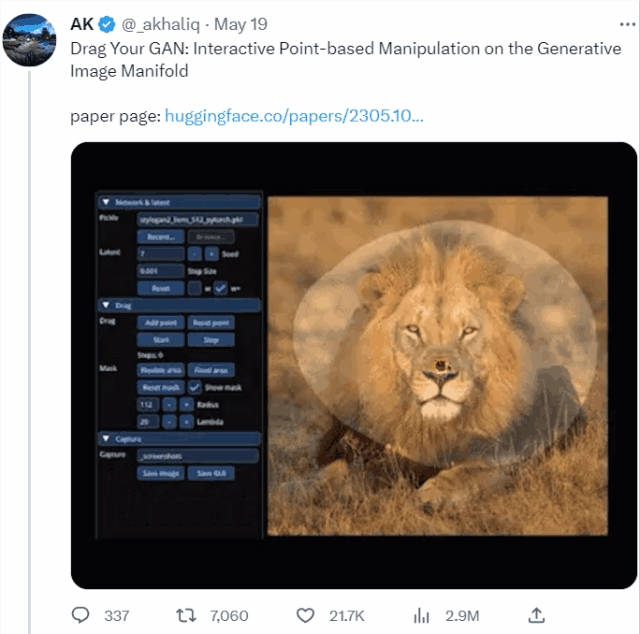
如此“有手就能做”的修图神器,来自一个MIT、谷歌、马普所等机构联手打造的DragGAN新模型,论文已入选SIGGRAPH2023。

没错,在扩散模型独领风骚的时代,竟然还能有人把GAN玩出新花样!

目前这个项目在GitHub上已经有5k Star,热度还在不断上涨中(尽管一行代码还没发)。

所以,DragGAN模型究竟长啥样?它又如何实现上述“神一般的操作”?

拽一拽关键点,就能修改图像细节
这个名叫DragGAN的模型,本质上是为各种GAN开发的一种交互式图像操作方法。
论文以StyleGAN2架构为基础,实现了点点鼠标、拽一拽关键点就能P图的效果。
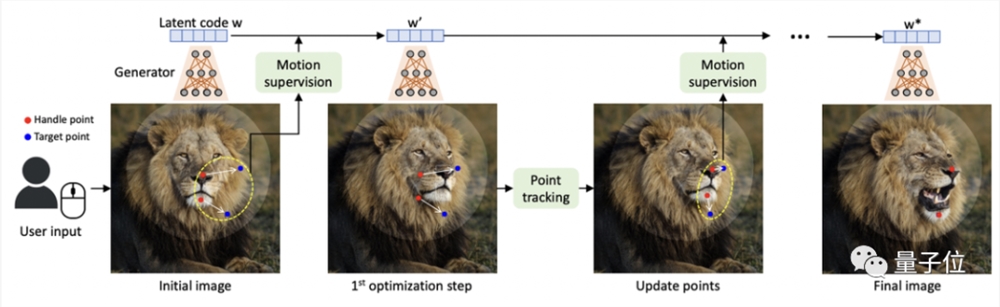
具体而言,给定StyleGAN2生成的一张图像,用户只需要设置几个控制点(红点)和目标点(蓝点),以及圈出将要移动的区域(比如狗转头,就圈狗头)。
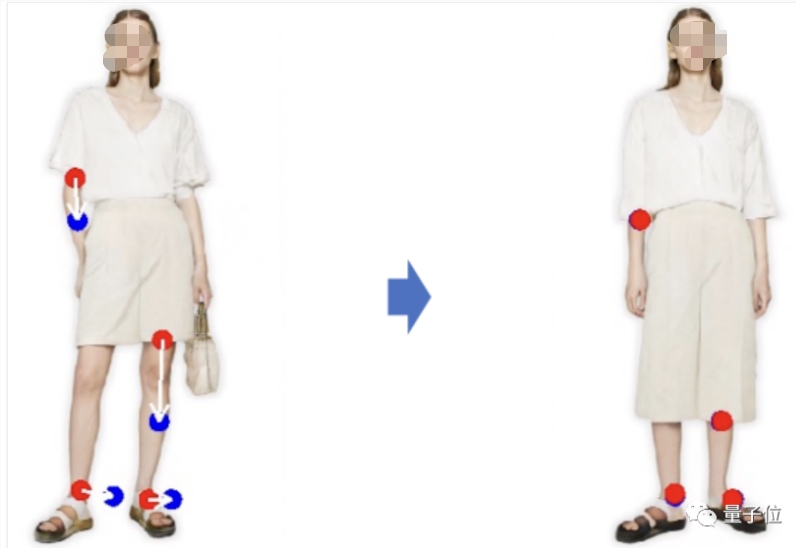
然后模型就将迭代执行运动监督和点跟踪这两个步骤,其中运动监督会驱动红色的控制点向蓝色的目标点移动,点跟踪则用于更新控制点来跟踪图像中的被修改对象。
这个过程一直持续到控制点到达它们对应的目标点。
不错,运动监督和点跟踪就是我们今天要讲的重点,它是DragGAN模型中最主要的两个组件。
先说运动监督。在此之前,业界还没有太多关于如何监督GAN生成图像的点运动的研究。
在这项研究中,作者提出了一种不依赖于任何额外神经网络的运动监督损失(loss)。
其关键思想是,生成器的中间特征具有很强的鉴别能力,因此一个简单的损失就足以监督运动。
所以,DragGAN的运动监督是通过生成器特征图上的偏移补丁损失(shifted patch loss)来实现的。
如下图所示,要移动控制点p到目标点t,就要监督p点周围的一小块patch(红圈)向前移动的一小步(蓝圈)。
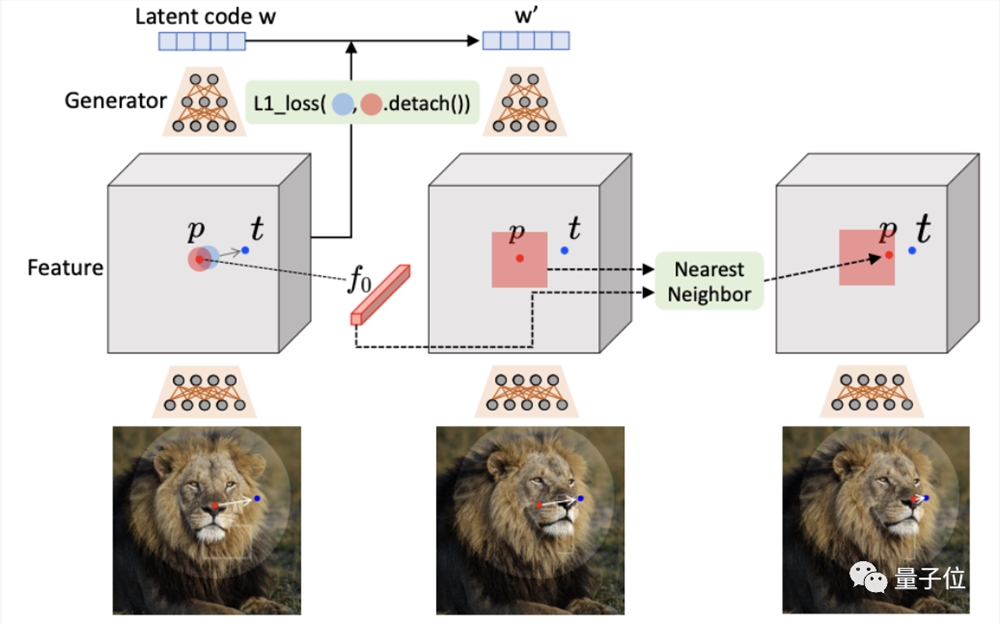
再看点跟踪。
先前的运动监督会产生一个新的latent code、一个新特征图和新图像。
由于运动监督步骤不容易提供控制点的精确新位置,因此我们的目标是更新每个手柄点p使其跟踪上对象上的对应点。
此前,点跟踪通常通过光流估计模型或粒子视频方法实现。
但同样,这些额外的模型可能会严重影响效率,并且在GAN模型中存在伪影的情况下可能使模型遭受累积误差。
因此,作者提供了一种新方法,该方法通过最近邻检索在相同的特征空间上进行点跟踪。
而这主要是因为GAN模型的判别特征可以很好地捕捉到密集对应关系。
基于这以上两大组件,DragGAN就能通过精确控制像素的位置,来操纵不同类别的对象完成姿势、形状、布局等方面的变形。
作者表示,由于这些变形都是在GAN学习的图像流形上进行的,它遵从底层的目标结构,因此面对一些复杂的任务(比如有遮挡),DragGAN也能产生逼真的输出。
单张3090几秒钟出图
所以,要实现几秒钟“精准控图”的效果,是否需要巨大的算力?
nonono。大部分情况下,每一步拖拽修图,单张RTX3090GPU在数秒钟内就能搞定。

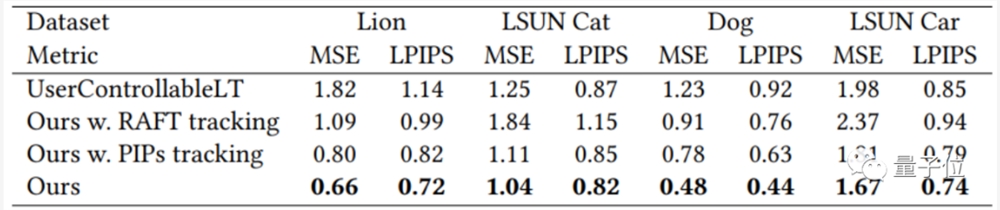
具体到生成图像的效果上,实际评估(均方误差MSE、感知损失LPIPS)也超越了一系列类似的“AI修图”模型,包括RAFT和PIPs等等:
如果说文字的还不太直观,具体到视觉效果上就能感受到差异了:

值得一提的是,DragGAN的“潜力”还不止于此。
一方面,如果增加关键点的数量,还能实现更加精细的AI修图效果,用在人脸这类对修图要求比较严格的照片上,也是完全没问题:

另一方面,不止开头展示的人物和动物,放在汽车、细胞、风景和天气等不同类型的图像上,DragGAN也都能精修搞定。

除了不同的照片类型,从站到坐、从直立到跑步、从跨站到并腿站立这种姿势变动较大的图像,也能通过DragGAN实现:

也难怪网友会调侃“远古的PS段子成真”,把大象转个身这种甲方需求也能实现了。

不过,也有网友指出了DragGAN目前面临的一些问题。
例如,由于它是基于StyleGAN2生成的图像进行P图的,而后者训练成本很高,因此距离真正商业落地可能还有一段距离。

除此之外,在论文中提到的“单卡几秒钟修图”的效果,主要还是基于256×256分辨率图像:

至于模型是否能扩展到256×256以外图像,生成的效果又是如何,都还是未知数。
有网友表示“至少高分辨率图像从生成时间来看,肯定还要更长”。
实际上手的效果究竟如何,我们可以等6月论文代码开源后,一测见真章。
团队介绍
DragGAN的作者一共6位,分别来自马克斯・普朗克计算机科学研究,萨尔布吕肯视觉计算、交互与AI研究中心,MIT,宾夕法尼亚大学和谷歌AR/VR部门。

其中包括两位华人:
一作潘新钢,他本科毕业于清华大学(2016年),博士毕业于香港中文大学(2021年),师从汤晓鸥教授。
现在是马普计算机科学研究所的博士后,今年6月,他将进入南洋理工大学担任助理教授(正在招收博士学生)。
另一位是Liu Lingjie,香港大学博士毕业(2019年),后在马普信息学研究所做博士后研究,现在是宾夕法尼亚大学助理教授(也在招学生),领导该校计算机图形实验室,也是通用机器人、自动化、传感与感知 (GRASP)实验室成员。
值得一提的是,为了展示DragGAN的可控性,一作还亲自上阵,演示了生发、瘦脸和露齿笑的三连P图效果:

是时候给自己的主页照片“修修图”了(手动狗头)。
论文地址:
https://vcai.mpi-inf.mpg.de/projects/DragGAN/data/paper.pdf
项目地址(代码6月开源):
https://github.com/XingangPan/DragGAN
参考链接:
[1]https://weibo.com/1727858283/N1iKl4zVG
[2]https://twitter.com/_akhaliq/status/1659424744490377217
[3]https://twitter.com/mrgreen/status/1659482594516377601
—完—
全球学术圈险被ChatGPT论文攻陷!知名出版商紧急撤稿,AI插图笑翻网友
近日,爱思唯尔上的几篇论文被发现开篇就暴露了「ChatGPT风格」,插图也是用Midjourney画的。学术圈被AI渗透已经不是一天两天了,搞科研的用AI写论文,学生用AI写作业,老师也用AI批作业,整个过程都没有真人了。学术圈,已经抵御不住LLM的入侵了!最近,世界知名出版集团爱思唯尔旗下的几篇论文接连被质疑。比如下面这篇锂电池的论文,在「介绍」部分的第一句,就暴露了可疑的痕迹——站长网2024-03-15 17:45:240000谷歌搜索引入语法检查模型EdiT5 提高语法纠正准确性
💡划重点:-Google研究团队开发了一种高效的语法纠正模型,基于EdiT5架构,使用户能够在Google搜索中检查查询的语法。-这一模型采用了新颖的文本编辑方法,降低了解码延迟,提高了纠正的准确性,同时结合了大型语言模型(LLMs)的优点。站长网2023-10-28 07:49:270000微软与穆迪达成战略合作:基于 Azure OpenAI 服务的 Moody’s CoPilot 已部署给全球 1.4 万名员工
站长之家(ChinaZ.com)6月30日消息:穆迪公司今天宣布与微软公司达成战略合作伙伴关系,为金融服务和全球知识工作者提供下一代数据、分析、研究、协作和风险解决方案。图片来自Microsoft站长网2023-06-30 19:36:100000官宣:余承东出任华为智能汽车解决方案BU董事长
快科技9月22日消息,就在昨天,多家媒体报道称华为智能车业务迎来重大调整,余承东不再担任华为智能汽车解决方案BUCEO一职,升任车BU董事长,接替他的是华为光产品线总裁靳玉志,华为内部已对上述调整进行了内部发文。站长网2023-09-22 21:02:330000半价出击,菜鸟速递硬刚顺丰
菜鸟集团推出自营快递品牌“菜鸟速递”一年后,将触角伸向了同城配送。自7月17日开始,菜鸟速递先后宣布在三个城市升级同城快递服务,广州、上海核心城区实现同城半日达、南京8个区实现同城当日达。其中,广州、上海只面向B端商家,每单首重6元,续重1元/KG,相比同类型产品,价格直降了一半。站长网2024-07-20 00:50:420000