一个读取excel数据处理完成后读入数据库的例子
最近收集了一批数据,各地根据问题数据做出反馈,但是各地在反馈的时候字段都进行了创新,好在下发的数据内容并没有改变,开始写的单进程的,由于时间较长,耗时380 秒,又改成多进程的,时间缩短为80-秒。现在把程序发出来,请各位大神进行指正。
import multiprocessing
import os
import time
import pandas as pd
from sqlalchemy import create_engine
import asyncio
import warnings
# warnings.simplefilter("ignore")
ywstrList=['经办机构', '原子业务编号', '原子业务名称', '风险名称','风险描述',
'校验规则结果', '创建时间', '风险提示信息', '业务日志号']
ywstrListMemo=['经办机构', '原子业务编号', '原子业务名称', '风险名称','风险描述',
'校验规则结果', '创建时间', '风险提示信息', '业务日志号','memo','time']
szlist = ['省本', '成都', '自贡', '攀枝', '泸州', '德阳', '绵阳', '广元',
'遂宁', '内江', '乐山', '南充', '眉山', '宜宾', '广安', '达州',
'雅安', '巴中', '资阳', '阿坝', '甘孜', '凉山']
# connect = create_engine('mysql pymysql://root:@127.0.0.1:3306/ywgk?charset=utf8')
connect = create_engine('mysql mysqlconnector://root:@127.0.0.1:3306/ywgk?charset=utf8')
# engine = create_engine('mysql mysqlconnector://scott:tiger@localhost/foo')
def findSZ(filename):
for sz in szlist:
if filename.find(sz) != -1:
return sz
return None
def ReadExcel(filename):
xlsdf = ''
xlsdf = pd.read_excel(filename)
""""
remove columns='sz' or '市'
"""
if "市" in list(xlsdf.keys().to_list()):
xlsdf.drop(columns='市', axis=1, inplace=True)
if "sz" in list(xlsdf.keys().to_list()):
xlsdf.drop(columns='sz', axis=1, inplace=True)
xlsdf = xlsdf.fillna("").astype('string')
return xlsdf
def filterDataOfSz(filename, xlsdf):
sz = findSZ(filename)
print(sz)
"""
筛选出包含对应市州的数据。
"""
if sz != None:
xlsdf = xlsdf[xlsdf['经办机构'].str[:2] == sz] # 筛出本市州数据
return xlsdf
def ConCatRestCols(xlsdf):
"""
去掉业务部分字段,保留市州反馈意见。
"""
print(xlsdf)
# if xlsdf==None:
#
print(filename "为空,需要处理")
#
return
xlfdf_keys_set = set(xlsdf.keys().to_list())
xlsdf_restkeys_set = xlfdf_keys_set - set(ywstrList)
xlsdf_restkeys_list = list(xlsdf_restkeys_set)
xls_rest_df = xlsdf.loc[:, xlsdf_restkeys_list] # 可以正确操作
xlsdf['memo'] = '#'
for col in xlsdf_restkeys_list:
xlsdf['memo'] = xlsdf[col]
#
return xlsdf
def SetTimeStamp(filename, xlsdf):
xlsdf['time'] = os.stat(str(filename)).st_mtime
return xlsdf
async def ProcessExcelAndtosql(filename, table):
df = ReadExcel(filename)
df = filterDataOfSz(filename=filename, xlsdf=df)
df = ConCatRestCols(df)
df = SetTimeStamp(filename=filename, xlsdf=df)
df = df.loc[:, ywstrListMemo]
print(filename)
print(df)
df.to_sql(name=table, con=connect, if_exists='append', index=False, chunksize=1000, method='multi')
def profile(func):
def wrapers(*args,**kwargs):
print("测试开始")
begin=time.time()
func(*args,**kwargs)
end=time.time()
print(f"耗时{end-begin}秒")
return wrapers
# async def getmsg(msg):
#
print(f'#{msg}')
#
await asyncio.sleep(1)
def getFiles(src:str):
import pathlib
files=[]
for file in pathlib.Path(src).rglob("*.xls?"):
files.append(str(file))
return files
def process_asyncio(files,table):
loop=asyncio.new_event_loop()
tasks=[loop.create_task(ProcessExcelAndtosql(filename,table)) for filename in files]
loop.run_until_complete(asyncio.wait(tasks))
@profile
def run(iterable,table):
process_count = multiprocessing.cpu_count()
# print(process_count)
pool = multiprocessing.Pool(process_count-2)
iterable=get_chunks(iterable, process_count)
for lst in iterable:
pool.apply_async(process_asyncio, args=(lst,table))
pool.close()
pool.join()
def main():
files = getFiles(r"e:\市州返回")
run(files, 'ywgk3')
def get_chunks(iterable,num):
# global iterable
import numpy as np
return np.array_split(iterable, num)
# import profile
if __name__=="__main__":
main()
本人只是编程的业余爱好者,只是把技术用于辅助工作,并没有深入研究技术理论,都是野路子,还请批评指正。
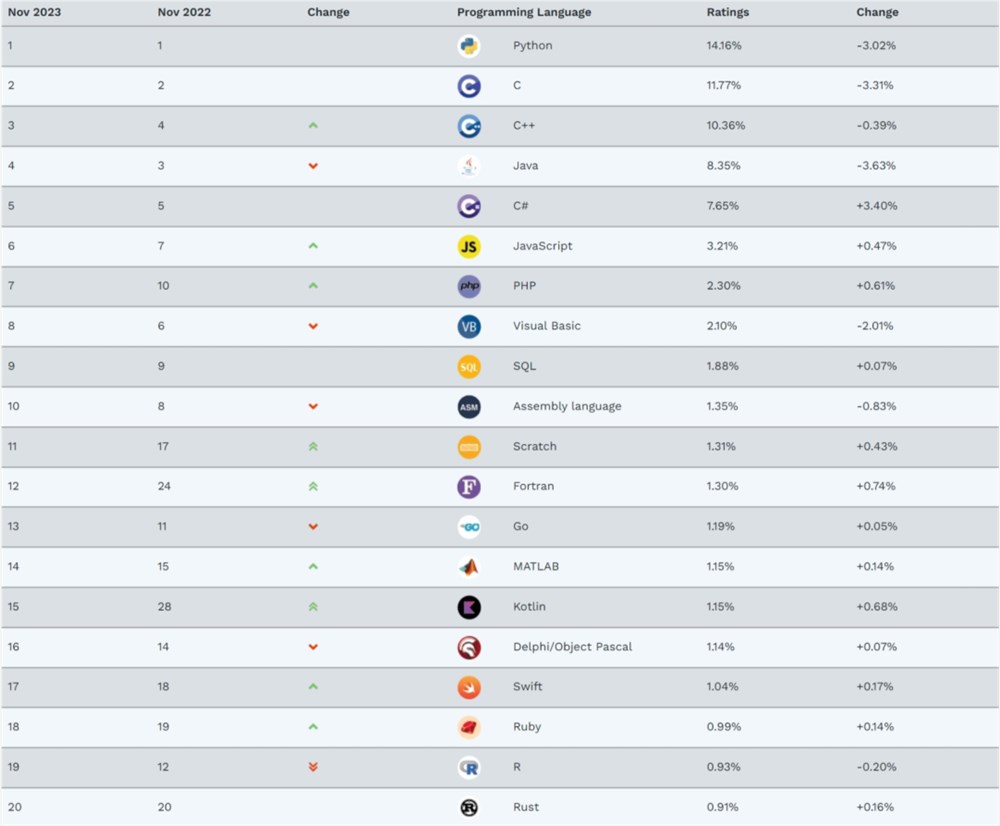
Kotlin 将取代 Java,跻身 Top 10?
一个月的时间过得很快,转眼之间11月TIOBE编程语言榜单已最新出炉,一起来看看这个月又有什么值得关注的新变化吧?“确信Kotlin能跻身前十名!”在今年9月的TIOBE榜单中,对于Kotlin再次冲进Top20这件事,当时TIOBE首席执行官PaulJansen预测:这次Kotlin的崛起可能会更有力,因为其用户群体经过这6年早已不是2017年的规模了。站长网2023-11-14 09:19:130000Mobile ALOHA:一种低成本的整体远程操作系统用于数据收集
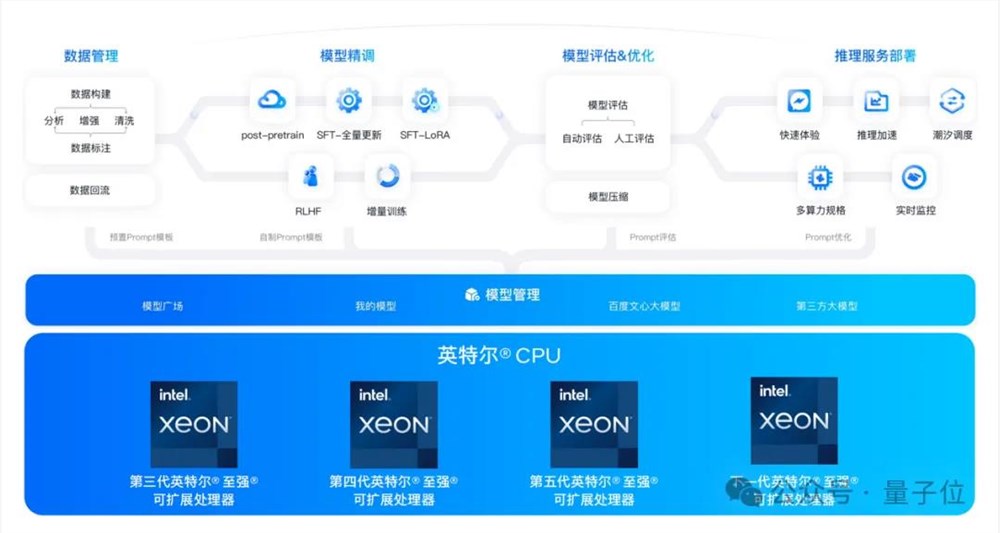
划重点:1.💡研究人员提出了一种低成本的整体远程操作系统,名为MobileALOHA,用于收集关于整体远程操作的数据。2.💡MobileALOHA通过将其放在轮式底座上,扩展了原始ALOHA的功能,使其具有移动能力。3.💡研究人员使用静态ALOHA数据集进行模仿学习,通过预训练和联合训练,实现了在移动操作任务中的良好性能。站长网2024-01-11 17:56:420001国产大模型第一梯队玩家,为什么pick了CPU?
AI一天,人间一年。现在不论是大模型本身,亦或是AI应用的更新速度简直令人直呼跟不上——Sora、Suno、Udio、Luma……重磅应用一个接一个问世。也正如来自InfoQ的调查数据显示的那般,虽然AIGC目前还处于起步阶段,但市场规模已初具雏形:预计到2030年将达4500亿人民币。AIGC应用正呈现多点开花之势,逐步从通用场景向行业纵深渗透。站长网2024-07-11 09:49:370001腾讯:文件传输助手大家放心用 服务器不会保存微信聊天记录!
快科技8月7日消息,今天腾讯公开回应称,文件传输助手大家放心用,服务器不会保存微信聊天记录。之前,国家安全部公众号介绍,文件传输助手”能够实现文件云端存储,在不同设备终端均可下载使用,殊不知涉密文件上传网络后,电脑和手机设备自动同步与存储的过程大大增加了境外间谍情报机关通过木马病毒获取相关文件的风险。传输软件公司后台也能轻易获取涉密文件,且无法有效控制知悉范围,极易造成失泄密。00002024胡润中国人工智能企业50强公布:寒武纪荣登榜首 市值2380亿
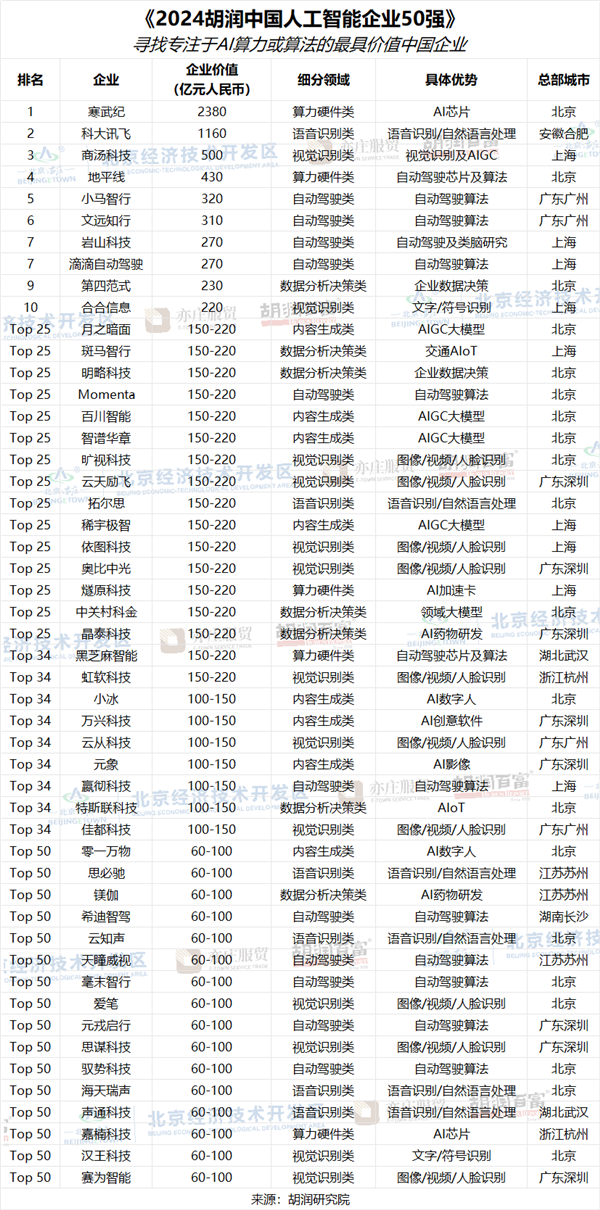
快科技1月15日消息,胡润研究院近日发布了《2024胡润中国人工智能企业50强》榜单,寒武纪以2380亿的价值荣登榜首。作为智能芯片领域的知名新兴公司,寒武纪的这一成就不仅彰显了其在技术创新、产品研发和市场拓展方面的卓越表现,也证明了其价值和潜力得到了市场的高度认可。站长网2025-01-15 22:14:130000